一.学习内容
本学期在软件需求课中学到了:
需求层次:

需求开发过程
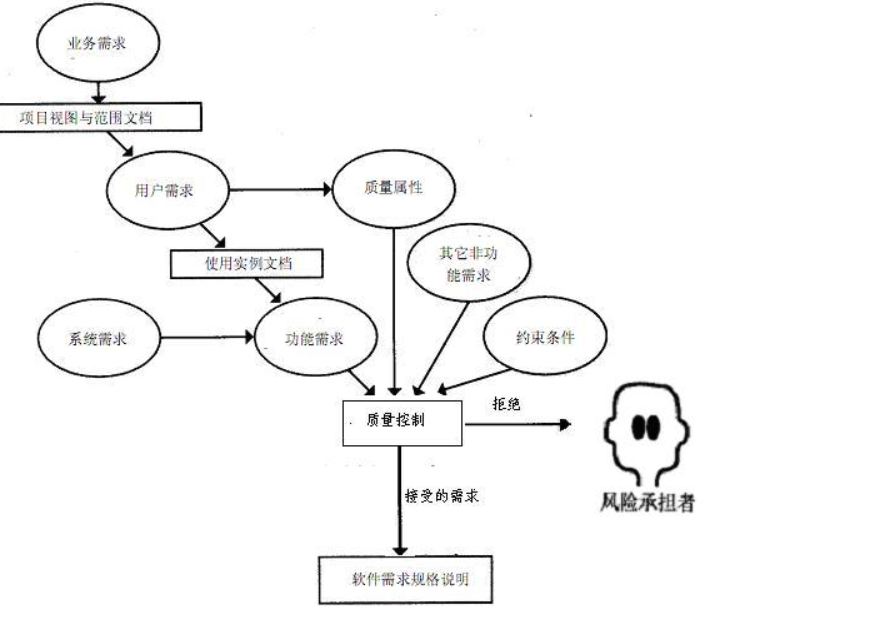
结构化建模:
分析步骤:1、建立当前系统的“具体模型”。 2、抽象出当前系统的逻辑模型。 3、建立目标系统的逻辑模型。 4、为了对目标系统做完整的描述,还需要考虑人机界面和其他一些问题。
细化步骤:① 使用数据流图(DFD)建立系统的功能模型:建立顶层数据流图,确定边界,自顶而下,按照层次逐步分解。 ② 使用逻辑操作符建立数据字典:定义数据流、数据存储、数据项等。 ③ 使用判定表或树给出加工小说明:集中描述一个加工“做什么”,包含执行条件、优先级、执行频率、出错处理等。
面向对象建模:
面向对象分析的主要内容是:开发一系列模型,以描述计算机软件结构,从而满足客户定义的需求
分析模型主要包括:描述领域对象(静态结构)的类图,描述对象交互(动态交互)的交互图 类图(class diagram):描述了构成一类对象特征的状态和行为(描述软件架构) 交互图(interaction diagram):描述对象之间的交互行为(描述系统行为) 每个用例会涉及一组对象的交互
如何建立分析模型:
发现领域对象,定义概念类 识别对象的属性 识别对象的关系,包括建立类的泛化关系、对象的关联关系 建立交互图
定义概念类:
从用例描述中获取候选概念 摘取用例的详细文档中的名词(术语或名词短语),然后进行分析 通过不同类别发现候选概念
使用Wirfs-Brock名词短语策略:
阅读理解需求文档(或用例说明); 反复阅读,筛选出名词或名词短语,建立初始对象清单(候选对象); 将候选对象分成三类,即显而易见的对象、明显无意义的对象和不确定类别的对象; 舍弃明显无意义的名词或短语; 小组讨论不确定类别的对象,直到将它们都合并或调整到其它两类。
属性的表示:
属性的名称和解释:有些属性只适用于该问题域,是专业术语,晦涩难懂;有些常用词语在特定环境下字面的含义有所修改,为了提高清晰度,需要对这些属性进行定义。 属性的数据类型:分析时使用简单类型,如整数、实数、字符串、日期、数组、布尔等,分析阶段因为不考虑技术实现,所以不需要考虑具体语言能支持的数据类型。 其它要求:如取值范围、缺省值等
识别概念类的属性:
如何为对象做一般性的描述?比如人,一般的描述信息有姓名、性别、出生日期、身高、体重等。 在当前问题域,对象还具备那些特定描述项?比如人作为门诊系统的患者,还需要考虑血型、药物过敏、家族病史等。 对象的责任是什么?在系统中对象还需要了解或提供哪些信息?比如图书馆要实现催还功能,与该责任相关的就需要为书籍或借书事项定义借书日期和期限。 对象可能处于什么状态?对象的状态不同,则可能执行的操作也不同。比如出租物品就有在库、出租、维修三个状态。
定义领域类属性的原则:
仅定义与系统责任和系统目标有关的属性。 使用简单数据类型来定义属性。如数字、字符串、日期、布尔、文本等。还包含多种特征或规则的数据,可考虑作为独立的对象类。 一般不使用可导出的属性。 不为对象关联定义属性。属性只用于体现对象本身的内在性质,关联属性来实现,但那是设计阶段的问题,应推迟考虑。 如毕业设计题目与教师和学生存在关联,但题目中不应定义“教师姓名”、“学号”之类的属性。
识别对象 的关联:关联表示不同类的对象之间的结构关系,它在一段时间内将多个类的实例连接在一起。可以使用关联表示对象了解其他对象的程度。
关联的原则:
找出问题域中的对象远远比找出关联更为重要 注意力集中在那些需要将对象之间的关系信息记忆一段持续时间的关联 太多无效关联会使概念模型变得混乱 要避免关联之间的信息冗余以及减少派生关联 关联使用关联名称、角色、多重性和导向性来说明
总之,本学期的软件需求与分析课程,学到了许多知识,但正如老师所说,还是需要自己去真正接触到项目时,才能更好的理解软件的需求,体验到软件需求调研如何进行。
在大型数据库课上学习了大数据的使用和知识,在测试中不断学到了hbase、hive、sqoop,nosql等等,对于大数据有了一定了解,在不断测试中也在不断增强自身的能力,并且在寒假期间会努力学习spark,不断拓展自己的视野,强化自己的能力。
二.课程建议
1.希望以后作业要求能够更加明确
三.加分项
1.本学期测试中认真完成要求。
2.最早申请外包杯报名队伍。
3.老师说的进入大数据学习的钉钉群,发布的一次签到会奖励加分