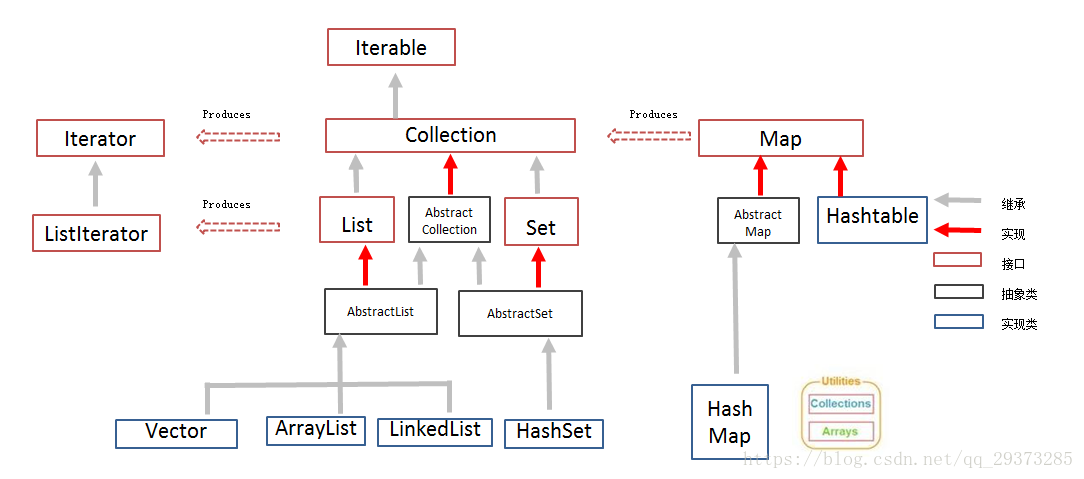
接口概述
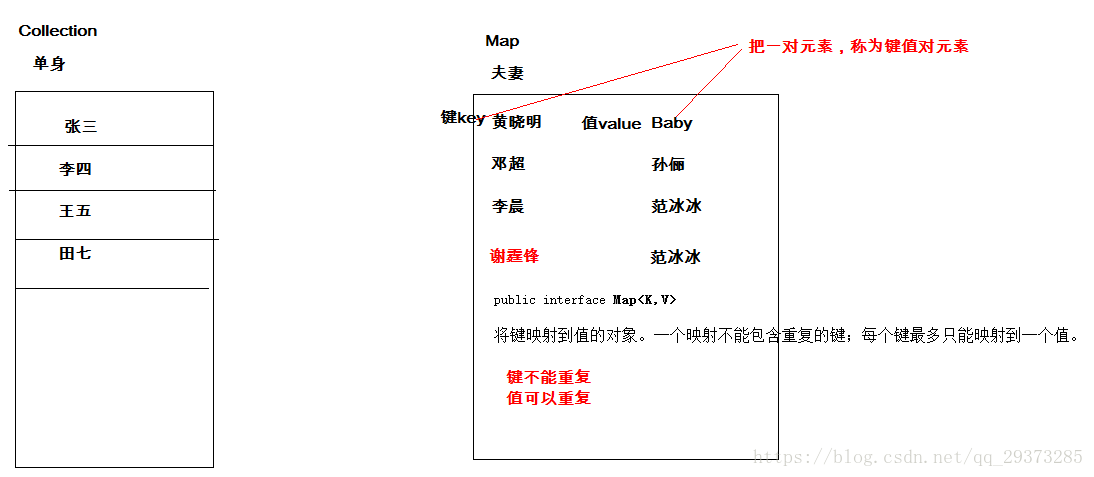
我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同,如下图。
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
Collection中的集合称为单列集合,Map中的集合称为双列集合。
需要注意的是,Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
Map中常用的集合为HashMap集合、LinkedHashMap集合。
Map接口中常用集合概述
通过查看Map接口描述,看到Map有多个子类,这里我们主要讲解常用的HashMap集合、LinkedHashMap集合。
HashMap<K,V>:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
LinkedHashMap<K,V>:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重 写键的hashCode()方法、equals()方法。
注意:Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。两个泛型变量<K,V>的数据类型可以相同,也可以不同。
map简介
在讲解Map排序之前,我们先来稍微了解下map。map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,Hashtable以及LinkedHashMap等。其中这四者的区别如下(简单介绍):
- HashMap
我们最常用的Map,它根据key的HashCode 值来存储数据,根据key可以直接获取它的Value,同时它具有很快的访问速度。HashMap最多只允许一条记录的key值为Null(多条会覆盖);允许多条记录的Value为 Null。非同步的。
- TreeMap
能够把它保存的记录根据key排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
- Hashtable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
- LinkedHashMap
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的
map的排序
- TreeMap的排序
TreeMap默认是升序的,如果我们需要改变排序方式,则需要使用比较器:Comparator。
Comparator可以对集合对象或者数组进行排序的比较器接口,实现该接口的public compare(T o1,To2)方法即可实现排序,该方法主要是根据第一个参数o1,小于、等于或者大于o2分别返回负整数、0或者正整数。如下:

public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>(
new Comparator<String>() {
public int compare(String obj1, String obj2) {
// 降序排序
return obj2.compareTo(obj1);
}
});
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key + ":" + map.get(key));
}
}
}
运行结果如下:
d:ddddd c:ccccc b:bbbbb a:aaaaa
上面例子是对根据TreeMap的key值来进行排序的,但是有时我们需要根据TreeMap的value来进行排序。对value排序我们就需要 借助于Collections的sort(List<T> list, Comparator<? super T> c)方法,该方法根据指定比较器产生的顺序对指定列表进行排序。但是有一个前提条件,那就是所有的元素都必须能够根据所提供的比较器来进行比较。如下:
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>();
map.put("d", "ddddd");
map.put("b", "bbbbb");
map.put("a", "aaaaa");
map.put("c", "ccccc");
//这里将map.entrySet()转换成list
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
//然后通过比较器来实现排序
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
//升序排序
public int compare(Entry<String, String> o1,
Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
运行结果:
a:aaaaa b:bbbbb c:ccccc d:ddddd
- HashMap的排序
我们都是HashMap的值是没有顺序的,他是按照key的HashCode来实现的。对于这个无序的HashMap我们要怎么来实现排序呢?参照TreeMap的value排序,我们一样的也可以实现HashMap的排序。
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
//升序排序
public int compare(Entry<String, String> o1,
Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
运行结果:
a:aaaaa b:bbbbb c:ccccc d:ddddd
List是Java中比较常用的集合类,关于List接口有很多实现类,本文就来简单介绍下其中几个重点的实现ArrayList、LinkedList和Vector之间的关系和区别。
List 是一个接口,它继承于Collection的接口。它代表着有序的队列。当我们讨论List的时候,一般都和Set作比较。
List中元素可以重复,并且是有序的(这里的有序指的是按照放入的顺序进行存储。如按照顺序把1,2,3存入List,那么,从List中遍历出来的顺序也是1,2,3)。 Set中的元素不可以重复,并且是无序的(从set中遍历出来的数据和放入顺序没有关系)。
ArrayList、 LinkedList 和 Vector之间的区别:
ArrayList、 LinkedList 和 Vector都实现了List接口,是List的三种实现,所以在用法上非常相似。他们之间的主要区别体现在不同操作的性能上。后面会详细分析。
ArrayList
ArrayList底层是用数组实现的,可以认为ArrayList是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其规模是动态增加的。
LinkedList
LinkedList底层是通过双向链表实现的。所以,LinkedList和ArrayList之前的区别主要就是数组和链表的区别。
数组中查询和赋值比较快,因为可以直接通过数组下标访问指定位置。
链表中删除和增加比较快,因为可以直接通过修改链表的指针(Java中并无指针,这里可以简单理解为指针。其实是通过Node节点中的变量指定)进行元素的增删。
所以,LinkedList和ArrayList相比,增删的速度较快。但是查询和修改值的速度较慢。同时,LinkedList还实现了Queue接口,所以他还提供了offer(), peek(), poll()等方法。
Vector
Vector和ArrayList一样,都是通过数组实现的,但是Vector是线程安全的。和ArrayList相比,其中的很多方法都通过同步(synchronized)处理来保证线程安全。
如果你的程序不涉及到线程安全问题,那么使用ArrayList是更好的选择(因为Vector使用synchronized,必然会影响效率)。
二者之间还有一个区别,就是扩容策略不一样。在List被第一次创建的时候,会有一个初始大小,随着不断向List中增加元素,当List认为容量不够的时候就会进行扩容。Vector缺省情况下自动增长原来一倍 的数组长度,ArrayList增长原来的50%。
ArrayList 和 LinkedList的性能对比
使用以下代码对ArrayList和LinkedList中的几种主要操作所用时间进行对比:
ArrayList<Integer> arrayList = new ArrayList<Integer>(); LinkedList<Integer> linkedList = new LinkedList<Integer>(); // ArrayList add long startTime = System.nanoTime(); for (int i = 0; i < 100000; i++) { arrayList.add(i); } long endTime = System.nanoTime(); long duration = endTime - startTime; System.out.println("ArrayList add: " + duration); // LinkedList add startTime = System.nanoTime(); for (int i = 0; i < 100000; i++) { linkedList.add(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList add: " + duration); // ArrayList get startTime = System.nanoTime(); for (int i = 0; i < 10000; i++) { arrayList.get(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("ArrayList get: " + duration); // LinkedList get startTime = System.nanoTime(); for (int i = 0; i < 10000; i++) { linkedList.get(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList get: " + duration); // ArrayList remove startTime = System.nanoTime(); for (int i = 9999; i >=0; i--) { arrayList.remove(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("ArrayList remove: " + duration); // LinkedList remove startTime = System.nanoTime(); for (int i = 9999; i >=0; i--) { linkedList.remove(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList remove: " + duration);
结果:
ArrayList add: 13265642 LinkedList add: 9550057 ArrayList get: 1543352 LinkedList get: 85085551 ArrayList remove: 199961301 LinkedList remove: 85768810
他们的表现的差异是显而易见的。在添加和删除操作上LinkedList更快,但在查询速度较慢。
如何选择
如果涉及到多线程,那么就选择Vector(当然,你也可以使用ArrayList并自己实现同步)。
如果不涉及到多线程就从LinkedList、ArrayList中选。 LinkedList更适合从中间插入或者删除(链表的特性)。 ArrayList更适合检索和在末尾插入或删除(数组的特性)。
资料来源摘自: https://mp.weixin.qq.com/s/eiQj3GLN84knfpyNt8cFVA
https://blog.csdn.net/qq_29373285/article/details/81487594
https://www.cnblogs.com/htyj/p/7723887.html