五、线程的概述
5、1 什么是线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程就是进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上执行的单位。
多线程(即多个控制线程)的概念是,在一个进程中存在朵儿控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都是供应一个车间的资源。
5、2 线程和进程的相关概念
-
进程不是一个执行的单位,它其实是一个资源单位
-
进程就是在内存当中有一块隔离的空间,专门存这个进程运行过程当中一些相关的数据。
-
进程申请空间,然后运行代码,那运行代码的过程我们叫做线程的执行
-
每一个进程内都自带一个线程,线程才是cpu上的执行单位,之前说切换实际切换后执行的进程里面的线程。cpu会在多个线程间切换。
5、3 在程序当中应该如何看待进程和线程?
-
右键运行干什么事情?
产生一个进程—>启动进程的目的就是开一个内存空间以及方便操作系统调度—>开空间的目的是为了存放进程相关的数据。**进程其实指的是一个资源单位或者资源集合—>开了空间之后里面存放代码,而代码需要去运行—>而代码的运行过程则是线程
-
所以进程可以说是线程的容器
线程 = 代码的运行过程
进程 = 线程+各种资源(如内存空间)
进程内的线程运行就像车间内的一条条流水线运行。
5、4 作为开发的常识
-
进程的启动和销毁(空间开始和释放)
进程启动--那这个程序的内存空间开辟好了
进程销毁--那么这个进程的空间释放了
-
线程的启动和销毁
线程启动--进程里的一段代码运行起来了
线程销毁--进程里的这段代码运行结束
5、5 线程与进程的区别是什么?
线程:单指代码的执行过程
进程:资源的申请与销毁的过程
问题:
同一进程下可以开多个线程吗?
答:可以
进程VS线程
-
内存共享or隔离
多个进程内存空间彼此隔离
同一进程下的多个线程共享该进程内的数据。
-
创建速度
创建线程的速度要远远快于创建进程的速度
六、多线程
6、1 threading模块介绍
multiprocessing模块的完全模仿了treading模块的接口,二者在使用层面,有很大的相似性.
官网链接:https://docs.python.org/3/library/threading.html?highlight=threading#
6、2 开启线程的两种方式
#方式一
from threading import Thread
import time
def task(name):
print(f'{name}task is running')
time.sleep(2)
print(f'{name}task is done')
if __name__ == '__main__':
t = Thread(target=task,args=('egon',))
t.start() # 告诉操作系统开一个线程 开启线程无需申请内存空间会非常快。
print('主')
# 注意:1 同一个进程下没有父子线程之分大家地位都一样。
# 2 右键运行发生了个什么事情? 开启了一个进程,开辟了一个内存空间,把代码都丢进去,然后运行代码(自带的主线程运行)
# 然后又开启了一个子线程。
# ps:主线程结束和子线程结束没有任何必然联系,比如主线程运行结束,子线程还在运行当中。不是主线程在等待子线程结束,是进程在等待自己的所有线程结束。
from threading import Thread
import time
class MyTread(Thread):
def run(self):
print('thread is running')
time.sleep(2)
print('thread is end')
if __name__ == '__main__':
t = MyTread()
t.start() #
print('主线程')
# 输出:
# thread is running
# 主线程
# thread is end
6、3 进程VS线程
1. 进程和线程的开启速度比较
from threading import Thread
from multiprocessing import Process
import time
def task(name):
print(f"{name} is running")
time.sleep(2)
print(f"{name} is done")
if __name__ == '__main__':
t = Thread(target=task,args=('子线程',))
p = Process(target=task,args=('子进程',))
t.start()
# p.start()
print('主')
'''
开启子进程打印的效果:
>主
>子进程 is running
>子进程 is done
开启子线程打印的效果:
>子线程 is running
>主
>子线程 is done
对比的结果:从打印效果就能看的出来,开启线程要快于进程。
开启进程需要申请空间,复制代码到该空间,然后执行自带线程,非常慢。
开启子线程 基本没有资源消耗所以非常快。
'''
2. 同一进程下的线程共享内存空间
from threading import Thread
import time
x = 100
def task():
global x
x = 20
if __name__ == '__main__':
t = Thread(target=task)
t.start()
time.sleep(2)
print(x) # 20
# 首先子线程修改了全局变量为20,主线程等待子线程修改完毕后打印x为20。
# 说明同一个进程下所有的线程共享同一份内存空间。
3. 查看主线程和子线程的pid
from threading import Thread
import os
def task():
print('子线程',os.getpid()) # 子线程 14576
if __name__ == '__main__':
t = Thread(target=task)
t.start()
print('主线程',os.getpid()) #主线程 14576
6、4 线程对象join用法
-
主线程等待子线程运行结束
from threading import Threadimport timedef task(name,n):print(f'{name} is running')time.sleep(n)print(f'{name} is done')if __name__ == '__main__':t1 = Thread(target=task,args=('线程1',1))t2 = Thread(target=task,args=('线程2',2))t3 = Thread(target=task,args=('线程3',3))start_time = time.time()t1.start() #t2.start() #t3.start() #t1.join() # 等1st2.join() # 等1st3.join() # 等1send_time = time.time()print(end_time-start_time) # 3.0023529529571533print('主')# 运行结果:'''线程1 is running线程1 is done主''' -
对比进程的join,进程的join是当前线程在等待等待子进程运行结束并不影响其他线程。(了解)
from multiprocessing import Processfrom threading import Threadimport timedef threadtask(name):print(f'{name} start')time.sleep(5)print(f'{name} end')def processtask(name):print(f'{name} start')time.sleep(20)print(f'{name} end')if __name__ == '__main__':t = Thread(target=threadtask,args=('子线程',))p = Process(target=processtask,args=('子进程',))p.start()t.start()p.join() # 当前线程等待当前进程下的p子进程结束,然后往下运行。from threading import Threadfrom multiprocessing import Processimport osdef work():print('hello',os.getpid())if __name__ == '__main__':#part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样t1=Thread(target=work)t2=Thread(target=work)t1.start()t2.start()print('主线程/主进程pid',os.getpid())#part2:开多个进程,每个进程都有不同的pidp1=Process(target=work)p2=Process(target=work)p1.start()p2.start()print('主线程/主进程pid',os.getpid())from threading import Threadfrom multiprocessing import Processimport osdef work():global nn=0if __name__ == '__main__':# n=100# p=Process(target=work)# p.start()# p.join()# print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100n=1t=Thread(target=work)t.start()t.join()print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据
6、5 思考主线程是否会等待子线程运行结束
import time
def task(name):
print(f'线程 start {name}')
time.sleep(3)
print('线程 end')
if __name__ == '__main__':
t = Thread(target=task,args=('egon',))
t.start() #非常快
print('主')
分析:
1 其实是进程在等
貌似是主线程在原地等着,主线程已经运行完。
原来没有子线程的情况下,其实就一个主线程这一条流水线工作完了,这个进程就结束了。
那现在的情况是当前进程有其他的子线程,是进程等待自己所有的子线程运行完。
# 主进程等子进程是因为主进程要给子进程收尸
# 现在看到的等是进程必须等待其内部所有线程都运行完毕才结束
6、6 线程的其他用法(了解)
-
Thread实例对象的方法
-
isAlive(): 返回线程是否活动的。
-
getName(): 返回线程名。
-
setName(): 设置线程名。
-
-
threading模块提供的一些方法:
-
threading.currentThread(): 返回当前的线程变量。
-
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
-
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
-
from threading import Thread
import threading
'''以后只有周日!!!'''
def task():
import time
time.sleep(3)
print(threading.current_thread().getName())
if __name__ == '__main__':
t = Thread(target=task)
t1 = Thread(target=task)
print(threading.current_thread().setName('张三')) # None
print(threading.current_thread().getName()) # 张三
t.start()
t1.start()
# 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
print(threading.enumerate()) # [<_MainThread(MainThread, started 17944)>, <Thread(Thread-1, started 19320)>, <Thread(Thread-2, started 19308)>]
print(len(threading.enumerate())) # 3
print(threading.activeCount()) # 返回正在运行的线程数量。与len(threading.enumerate())有相同的结果。
6、7 守护线程(了解)
-
守护线程首先是一个线程。
-
守护线程守护到当前进程运行结束。
-
ps:比如有未完成的子进程阶段会守护,比如有未完成的其他子线程也均会守护。
-
-
守护进程首先是一个进程。
-
守护进程守护到当前进程的最后一行代码结束。
-
代码演示:
# 守护线程守护到当前进程结束
from threading import Thread
import threading
import time
def threadtask(name):
print(f' {name} start')
print(time.sleep(20))
print(f' {name} end')
# print(time.sleep(6))
def threadtask2(name):
print(f'{name} start')
time.sleep(10)
print(threading.enumerate()) # [<_MainThread(MainThread, stopped 14544)>, <Thread(Thread-1, started daemon 13676)>, <Thread(Thread-2, started 13148)>]
print(f'{name} end')
if __name__ == '__main__':
t = Thread(target=threadtask,args=('守护线程',))
t2 = Thread(target=threadtask2,args=('子线程',))
t.daemon = True
t.start()
t2.start()
print('主')
'''
守护线程 start
子线程 start
主
[<_MainThread(MainThread, stopped 15448)>, <Thread(Thread-1, started daemon 17520)>, <Thread(Thread-2, started 10356)>]
子线程 end
'''
可以看到当主线程已经结束的时候,其他子线程没有结束的时候打印当前的活跃的线程发现有守护线程。
6、8 同步锁(线程的互斥锁)
1 示例:
x = 1
def func1():
global x
print(x)
func2()
print(x)
x -= 1
def func2():
global x
x = 10000
func1()
print(x)
```
运行结果:
1
10000
9999
```
2 使用线程互斥锁:
from threading import Thread,current_thread,Lock
import time
x = 1
lock = Lock()
def func1():
global x
lock.acquire()
print(x)
temp = x
time.sleep(0.1)
x = temp - 1
# 再次进行x -1 的时候会获取最新的值
# 注意不要 x = x-1 否则测试不出来减一的效果
lock.release()
if __name__ == '__main__':
t_list = []
for i in range(10):
t = Thread(target=func1)
t_list.append(t)
t.start()
for i in t_list:
i.join()
print(x)
```
运行结果:
1
0
-1
-2
-3
-4
-5
-6
-7
-8
-9
```
死锁问题:
# 两个线程
# 线程1拿到了(锁头2)想要往下执行需要(锁头1),
# 线程2拿到了(锁头1)想要往下执行需要(锁头2)
# 互相都拿到了彼此想要往下执行的必需条件,互相都不放手里的锁头.
from threading import Thread,current_thread,Lock
import time
lock1 = Lock()
lock2 = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
lock1.acquire()
print(f'{self.name} 拿到了锁1')
lock2.acquire()
print(f'{self.name} 拿到了锁2')
lock2.release()
lock1.release()
def func2(self):
lock2.acquire()
print(f'{self.name} 拿到了锁2')
time.sleep(2)
lock1.acquire()
print(f'{self.name} 拿到了锁1')
lock1.release()
lock2.release()
if __name__ == '__main__':
for i in range(5):
t = MyThread()
t.start()
```
运行结果:
Thread-1 拿到了锁1
Thread-1 拿到了锁2
Thread-1 拿到了锁2
Thread-2 拿到了锁1
```
# 从结果可以看出该线程没有运行结束就卡住了,死锁了
解决死锁的问题:
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread, RLock
import time
lock1 = RLock()
lock2 = lock1
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
lock1.acquire()
print(f'{self.name} 拿到了锁1')
lock2.acquire()
print(f'{self.name} 拿到了锁2')
lock2.release()
lock1.release()
```
运行结果:
Thread-1 拿到了锁1
Thread-1 拿到了锁2
Thread-1 拿到了锁2
Thread-1 拿到了锁1
Thread-2 拿到了锁1
Thread-2 拿到了锁2
Thread-2 拿到了锁2
Thread-2 拿到了锁1
Thread-4 拿到了锁1
Thread-4 拿到了锁2
Thread-4 拿到了锁2
Thread-4 拿到了锁1
Thread-3 拿到了锁1
Thread-3 拿到了锁2
Thread-3 拿到了锁2
Thread-3 拿到了锁1
Thread-5 拿到了锁1
Thread-5 拿到了锁2
Thread-5 拿到了锁2
Thread-5 拿到了锁1
```
# 从这个运行结果中我们可以看到死锁问题得到了解决
# 递归锁 在同一个线程内可以被多次acquire
# 如何释放 内部相当于维护了一个计数器 也就是说同一个线程 acquire了几次就要release几次
-
mutexA=mutexB=threading.RLock()
-
一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
6、9 信号量Semaphore
同进程的一样
Semaphore管理一个内置的计数器, 每当调用acquire()时内置计数器-1; 调用release() 时内置计数器+1; 计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread,Semaphore
import threading
import time
def task():
sm.acquire()
print(f"{threading.current_thread().name} get sm")
time.sleep(3)
sm.release()
if __name__ == '__main__':
sm = Semaphore(5) # 同一时间只有5个进程可以执行。
for i in range(20):
t = Thread(target=task)
t.start()
```
运行结果:
Thread-1 get sm
Thread-2 get sm
Thread-3 get sm
Thread-4 get sm
Thread-5 get sm
Thread-6 get sm
Thread-7 get sm
Thread-8 get sm
Thread-9 get sm
Thread-10 get sm
```
*它与进程池是完全不同的概念,进程池Pool(4),最大只能生产4个进程,而且从头到尾都只是这四个进程,不会产生新的,而信号量是产生一堆线程/进程。
6、10 GIL
6、10、1 介绍
'''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
6、10、2 GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test.py,python aaa.py,python bbb.py会产生3个不同的python进程
'''
#验证python test.py只会产生一个进程
#test.py内容
import os,time
print(os.getpid())
time.sleep(1000)
'''
python3 test.py
#在windows下
tasklist |findstr python
#在linux下
ps aux |grep python
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
#2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
综上:
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
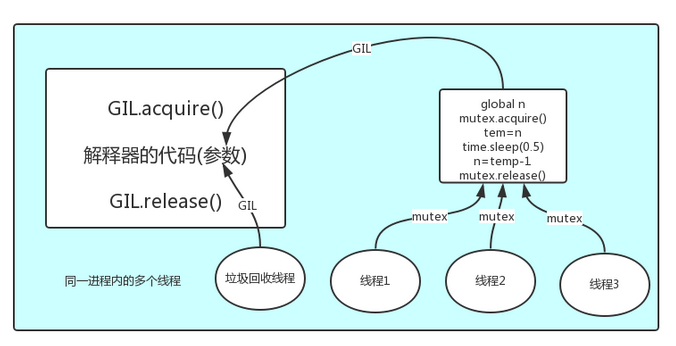](https://img2018.cnblogs.com/blog/1407587/201909/1407587-20190917014738951-36195191.png){kind=link}
6、10、3 GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如下图
](https://img2018.cnblogs.com/blog/1407587/201909/1407587-20190917014727162-463678701.png){kind=link}
](https://img2018.cnblogs.com/blog/1407587/201909/1407587-20190917014717889-1474066452.png){kind=link}
6、11 多进程VS多线程(使用场景)
#分析:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
#多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜。
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
#结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
#计算密集型 -----》推荐多进程
-多线程
四个线程每个都要做计算的时间一点也没少。
-多进程
四个进程可以实现并行的去计算,只花了一个进程计算的时间。
#io密集型 99%都在做io ----》推荐多线程
假设io要10s
-多进程
四个进程每个io 10s,开四个进程并行的拿到cpu,启动4个进程的时间(这个时间比较长)+10s+1点计算时间(忽略不计)+进程的切换(时间较久)。
启动进程时间耗的比较久,进程的切换耗时也比较久。
-多线程
四个线程每个io 10s 遇到io了切遇到io了切,启动4个线程的时间+10s+4点计算的时间(忽略不计)+线程的切换。
计算机密集型测试代码(推荐使用多线程)
from threading import Thread
from multiprocessing import Process
import os, time
def work1():
res = 0
for i in range(100000000):
res *= i
if __name__ == '__main__':
t_list = []
start = time.time()
for i in range(4):
# t = Process(target=work1) #多进程
t = Thread(target=work1) # 多线程
t_list.append(t)
t.start()
for i in t_list:
i.join()
end = time.time()
# print('多进程', end-start) #多进程 10.54699993133545
print('多线程', end - start) #多线程 18.270999908447266
IO密集型测试(推荐使用多线程)
from threading import Thread
from multiprocessing import Process
import os, time
def work1():
time.sleep(5)
if __name__ == '__main__':
t_list = []
start = time.time()
for i in range(4):
t = Process(target=work1) #多进程
# t = Thread(target=work1) # 多线程
t_list.append(t)
t.start()
for i in t_list:
i.join()
end = time.time()
print('多进程', end-start) #多进程 5.593999862670898
# print('多线程', end - start) #多线程 5.000999927520752
927520752
6、12 线程定时器
from threading import Timer, current_thread
def task(x,):
print(f'{x} run...')
print(current_thread().name )
if __name__ == '__main__':
t = Timer(3, task, args=(10,)) # 3表示3s后执行该线程
t.start()
```
运行结果:
10 run...
Thread-1
```
6、13 线程queue
queue队列:使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
这句话的意思是:当必须在多个线程之间安全地交换信息时,队列在线程编程中尤其有用。
-
class queue.Queue(maxsize=0) # 先进先出
import queueq = queue.Queue()q.put('laotie')q.put('laoxiong')q.put('tuhao')print(q.get())print(q.get())print(q.get())```运行结果:laotielaoxiongtuhao```其他方法:
q.task_done()#向q.join()发送一次信号,证明一个数据已经被取走了q.join() #阻塞主线程等待子线程运行结束 -
class queue.LifoQueue(maxsize=0) #实现堆栈效果(先进后出)
import queueq = queue.LifoQueue()q.put('laotie')q.put('laoxiong')q.put('tuhao')print(q.get())print(q.get())print(q.get())'''运行结果:tuhaolaoxionglaotie''' -
class queue.Priority(maxsize=0) # 存储数据时可设置优先级的队列
import queueq = queue.PriorityQueue()# put进入一个元组,元祖的第一个元素是优先级(通常是数字,也可以是非数字之间的比较,)数字越小优先级越高q.put((50, 'laotie'))q.put((20, 'laoxiong'))q.put((90, 'tuhao'))print(q.get())print(q.get())print(q.get())'''运行结果(数字越小优先级越高,优先级高的优先出队):(20, 'laoxiong')(50, 'laotie')(90, 'tuhao')'''
6、14 socket的多线程
6、14、1 基本socket代码模板
服务端:
import socket
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.bind(('127.0.01', 8004))
soc.listen(5)
while True:
conn, addr = soc.accept()
print(f'连接上了{addr}')
while True:
try:
msg = conn.recv(1024)
if msg ==0:break
print(msg.decode())
data = input('>>:').strip()
conn.send(data.encode('utf8'))
except ConnectionResetError:
print(f'客户端{addr}关闭了一个连接')
break
conn.close()
客户端:
import socket
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.connect(('127.0.0.1', 8004))
while True:
msg = input(">>:").strip()
if len(msg) == 0:continue
soc.send(msg.encode('utf8'))
data = soc.recv(1024)
print(data.decode('utf8'))
soc.close()
**这时候我们可以想到socket服务端是IO密集型程序,IO密集型程序更适合使用多线程处理。
那么下面我们就可以试着写一下:
6、14、2 多线程实现服务端并发
多线程服务端:
import socket
from threading import Thread
def task(conn, addr):
while True:
try:
msg = conn.recv(1024)
if msg ==0:break
print(msg.decode())
data = f'回复{addr}:收到'
conn.send(data.encode('utf8'))
except ConnectionResetError:
print(f'客户端{addr}关闭了一个连接')
break
conn.close()
def socket_server():
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.bind(('127.0.01', 8004))
soc.listen(5)
while True:
conn, addr = soc.accept()
print(f'连接上了{addr}')
t = Thread(target=task, args=(conn, addr))
t.start()
if __name__ == '__main__':
socket_server()
多线程客户端:
import socket
from threading import Thread,current_thread
def task():
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.connect(('127.0.0.1', 8004))
while True:
msg = f'你好,这是{current_thread().name}'
if len(msg) == 0:continue
soc.send(msg.encode('utf8'))
data = soc.recv(1024)
print(data.decode('utf8'))
soc.close()
if __name__ == '__main__':
for i in range(5):
t = Thread(target=task)
t.start()
6、15 同步异步
什么是同步?
# 所谓同步,就是在发出一个功能调用,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。
什么是异步?
# 异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立即得到结果。当该异步功能完成后,通过状态、通知或者回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量值,这其实是一种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没有太多区别。
ps:
”同步“就好比:你去外地上学(人生地不熟),突然生活费不够了;此时你决定打电话回家,通知家里转生活费过来,可是当你拨出电话时,对方一直处于待接听状态(即:打不通,联系不上),为了拿到生活费,你就不停的oncall、等待,最终可能不能及时要到生活费,导致你今天要做的事都没有完成,而白白花掉了时间。 “异步”就是:在你打完电话发现没人接听时,猜想:对方可能在忙,暂时无法接听电话,所以你发了一条短信(或者语音留言,亦或是其他的方式)通知对方后便忙其他要紧的事了;这时你就不需要持续不断的拨打电话,还可以做其他事情;待一定时间后,对方看到你的留言便回复响应你,当然对方可能转钱也可能不转钱。但是整个一天下来,你还做了很多事情。 或者说你找室友临时借了一笔钱,又开始happy的上学时光了。
6、16 进程池&线程池
前言:
重点概念
-
什么时候用池?
池的功能是限制启动的进程数或线程数
什么时候应该限制呢?
当发生并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时
这时候我们就应该使用池的概念将进程数或者线程数限制在计算机可承受的范围内。
-
同步VS异步
同步、异步指的是提交任务的两种方式
同步:提交完任务后就在原地等待,直到任务运行完毕后拿到任务的返回值,再继续运行下一行代码
异步:提交完任务(可以绑定一个回调函数来实现)后根本就不在原地等待,直接运行下一行代码,等到任务有返回值后会自动触发回调函数
回调机制:任务执行中处于某种机制的情况自动触发回调函数
6、16、1 Python标准模块--concurrent.futures
官方链接:https://docs.python.org/dev/library/concurrent.futures.html
1 介绍:
-
concurrent.futures模块提供了高度封装的异步调用接口
-
ThreadPoolExecutor:线程池,提供异步调用
-
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
两者都实现相同的接口,该接口由抽象Executor类定义。
2 基本方法
-
submit(fn, *args, **kwargs) 异步提交任务
-
map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作
-
shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作
-
wait=True,等待池内所有任务执行完毕回收完资源后才继续
-
wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕
-
submit和map必须在shutdown之前
-
result(timeout=None) 取得结果
-
add_done_callback(fn) 回调函数
6、16、2 进程池/线程池的基本用法
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import os, time
def task(i):
print(f'{current_process().name} 在运行 任务{i}')
time.sleep(0.2)
return i**2
if __name__ == '__main__':
# pool = ProcessPoolExecutor(4)
pool = ThreadPoolExecutor(4)
fu_list = []
for i in range(20):
future = pool.submit(task, i)
print(future.result()) #如果拿不到值会在这里阻塞
fu_list.append(future)
pool.shutdown(wait=True) # 等待池内所有人物执行完毕
for i in fu_list:
print(i.result()) # 那不到值阻塞在这
6、16、3 回调函数
# from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# from threading import currentThread
# from multiprocessing import current_process
# import os, time
#
# def task(i):
# print(f'{current_process().name} 在运行 任务{i}')
# time.sleep(0.2)
# return i**2
#
# if __name__ == '__main__':
# # pool = ProcessPoolExecutor(4)
# pool = ThreadPoolExecutor(4)
# fu_list = []
# for i in range(20):
# future = pool.submit(task, i)
# print(future.result()) #如果拿不到值会在这里阻塞
# fu_list.append(future)
# pool.shutdown(wait=True) # 等待池内所有人物执行完毕
# for i in fu_list:
# print(i.result()) # 那不到值阻塞在这
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import os, time
def task(i):
print(f'{current_process().name} 在运行 任务{i}')
time.sleep(0.2)
return i**2
def parse(future):
print(future.result())
# print(currentThread().name,'拿到了结果',future.result()) # 如果是线程池 执行完当前任务 负责执行回调函数的是执行任务的线程。
print(current_process().name,'拿到了结果',future.result()) # 如果是进程池 执行完当前任务 负责执行回调函数的是执行任务的是主进程
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
# pool = ThreadPoolExecutor(4)
fu_list = []
for i in range(20):
future = pool.submit(task, i)
future.add_done_callback(parse)# 绑定回调函数
# 当任务执行结束拿到返回值的时候自动触发回调函数。并且把future当做参数直接传给回调函数parse
6、17 协程
6、17、1 协程的概念
1、协程:
-
单线程实现并发
-
在应用程序里控制多个任务的切换+保存状态
-
优点:
应用程序切换的速度要远远高于操作系统的切换的速度。
-
缺点(对比多线程,多进程):
多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地
该线程内的其他的任务都不能执行了
一旦引入协程,就需要检测单线程下所有的IO行为。
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
3、思考什么样的协程有意义?
盲目切换反而会导致效率低下,遇到IO切换的协程才会提升单个线程下的执行效率(降低IO时间)
6、17、2 通过yield实现协程
import time
def func1():
while True:
1000000+1
yield
def func2():
g = func1()
for i in range(100000000):
i+1
next(g)
start = time.time()
func2()
stop = time.time()
print(stop - start) # 28.522686004638672
### 对比通过yeild切换运行的时间反而比串行更消耗时间,这样实现的携程是没有意义的。
import time
def func1():
for i in range(100000000):
i+1
def func2():
for i in range(100000000):
i+1
start = time.time()
func1()
func2()
stop = time.time()
print(stop - start) # 17.141255140304565
6、17、3 Gevent介绍
1 安装
pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或者异步编程,在gevent中用到的只要模式是Greenlet,它是以C扩展模块形式接入Python的轻量级协程。Greenlet全部运行在主程序操作系统进程的内部,但他们被协作式的调度。
2 用法
-
g1 = gevent.spawn(func,1,2,3,x=4,y=5) 创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
-
g2=gevent.spawn(func2)
-
g1.join() #等待g1结束
-
g2.join() #等待g2结束
-
#或者上述两步合作一步:gevent.joinall([g1,g2])
-
g1.value #拿到func1的返回值
import geventdef eat(name):print('%s eat 1' %name)gevent.sleep(2)print('%s eat 2' %name)def play(name):print('%s play 1' %name)gevent.sleep(1)print('%s play 2' %name)g1=gevent.spawn(eat,'egon')g2=gevent.spawn(play,name='egon')g1.join()g2.join()#或者gevent.joinall([g1,g2])print('主')在上述事例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import monkeymonkey.patch_all()import geventimport timedef eat():print('eat food 1')time.sleep(2)print('eat food 2')def play():print('play 1')time.sleep(1)print('play 2')start = time.time()g1 = gevent.spawn(eat)g2 = gevent.spawn(play)g1.join()g2.join()# gevent.joinall([g1,g2])end = time.time() # 3.0165441036224365# 如果打好了补丁 就可以识别非gevent.sleep阻塞进行切换print(end-start)
6、17、4 socket服务端单线程并发
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
客户端:
import socket
from threading import Thread,current_thread
def task():
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.connect(('127.0.0.1', 8004))
while True:
msg = input(f'{current_thread().name}:')
soc.send(msg.encode('utf8'))
data = soc.recv(1024)
print(f'收到服务端回复:{data.decode("utf8")}')
soc.close()
if __name__ == '__main__':
t = Thread(target=task)
t.start()
服务端:
import socket
from threading import Thread
from gevent import monkey;monkey.patch_all()
import gevent
def task(conn,addr):
while True:
try:
msg = conn.recv(1024)
if msg ==0:break
print(f'收到{addr}消息:{msg.decode()}')
data = input(f'回复{addr}:')
conn.send(data.encode('utf8'))
except ConnectionResetError:
print(f'客户端{addr}关闭了一个连接')
break
conn.close()
def socket_server():
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
soc.bind(('127.0.01', 8004))
soc.listen(5)
while True:
conn, addr = soc.accept()
gevent.spawn(task,conn,addr)
print(f'连接上了{addr}')
if __name__ == '__main__':
g = gevent.spawn(socket_server)
g.join()