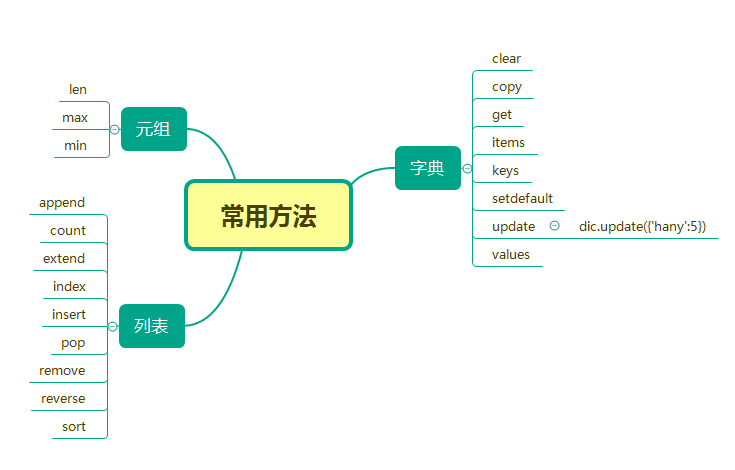
启发:
1.可以使用系统给出的方法,就不要自己去创建判断,效率可能会降低很多
2.使用一个变量不能解决问题,那就创建多个变量
3.找准数据类型,只要数据是这种数据类型,那么它就具有这个数据类型应该具有的方法,如果没有你需要的,那么就进行强制转换.
4.使用字典存储值,可以将两个序列对象的格式进行自定义
dict_xy = dict(zip(df['名称'],df['名称']))
# 将数据存为字典结构
for key,value in dict_xy.items():
# 对字典进行遍历
dict_xy[key] = float(value.split("亿")[0])
# 去掉多余数目
print(dict_xy)
2020-06-07