---恢复内容开始---
1.什么是字符编码
算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符?
必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
以下两个场景下涉及到字符编码的问题:
1. 一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2. python中的数据类型字符串是由一串字符组成的(python文件执行时)
1.2.字符编码的发展
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本 中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
1.3.需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
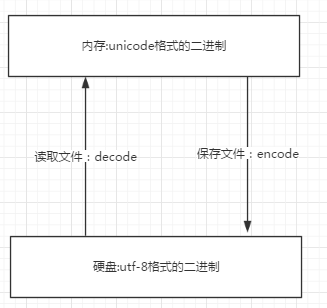
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
2.字符编码的使用
2.1文本编辑器一锅端
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
---恢复内容结束---