转载:https://zhuanlan.zhihu.com/p/259356109
转载:https://blog.csdn.net/kittyzc/article/details/107198055 代码解读
1 前言
欢迎关注【深度学习-目标追踪专栏】!!! 该专栏包含了有关SOT和MOT模型/算法论文和代码的解析。分别如下:
SOT单目标检测:
周威:【SOT】siameseFC论文和代码解析zhuanlan.zhihu.com
周威:【SOT】Siamese RPN论文解读和代码解析zhuanlan.zhihu.com
周威:【SOT】Siamese RPN++ 论文和代码解析zhuanlan.zhihu.com
周威:【SOT】Siamese Mask论文和代码解析zhuanlan.zhihu.com
MOT多目标追踪:
周威:【MOT】详解SORT与卡尔曼滤波算法zhuanlan.zhihu.com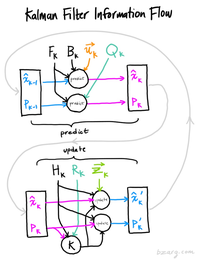
周威:【MOT】详解DeepSORT多目标追踪模型zhuanlan.zhihu.com
周威:【MOT】对JDE的深度解析zhuanlan.zhihu.com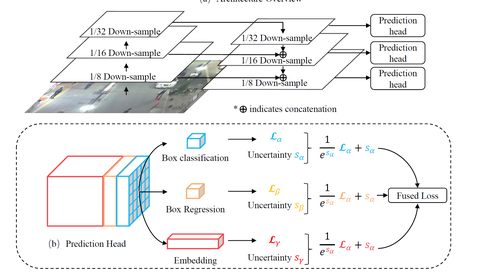
周威:【MOT】CenterTrack深度解析zhuanlan.zhihu.com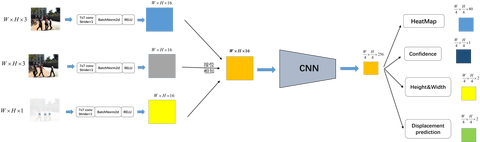
持续更新中。。。
本文我们将介绍一个在多个追踪benchmarks上霸榜的追踪器 ,一个实用又简单的目标追踪Baseline,FairMOT!
其实FairMOT属于JDE(Jointly learns the Detector and Embedding model )的一种。实验证明了现有的JDE方法存在一些不足,FairMOT根据这些不足进行了相关的改进。
作者就以下目前JDE方法在目标追踪领域存在的三点不足进行了说明。我们这里一一解析。
1.1 Anchor-Based 的检测器不适用JDE追踪模式
作者提到目前JDE的检测方式同时提取检测框和检测框内物体的Re-ID信息(低维的向量信息)。而基于Anchor-Based 检测器产生出来的anchor并不适合去学习合适的Re-ID信息,原因有二,其一是一个物体可能被多个anchor负责并进行检测,这会导致严重的网络模糊性(ambiguities for the network)。第二个原因是实际物体的中心可能与负责对该物体进行检测的anchor中心有偏差。这里不妨引用原文中的图进行说明。
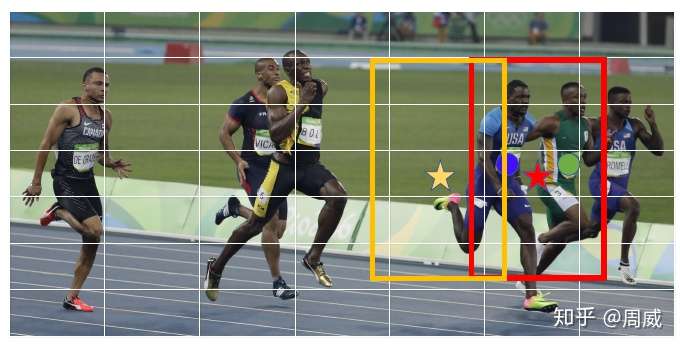
上图中的黄色anchor与红色anchor都负责蓝色小伙的检测,但是很明显,其中心与蓝色小伙的中心并不重合,而且这些anchor并不能很好包含这个蓝色精神小伙。所以这是很多基于Anchor-Based 的检测器的JDE方法的不足。
1.2 多层特征融合
这个考虑到Re-ID信息不能仅仅包含高层网络中的语义信息,也要适度包含低层网络中的的颜色,纹理的信息,所以多层特征融合是非常有必要的。这点不必多说,相信大家应该都懂。
1.3 到底选择多大的Re-ID维度来存储Re-ID信息呢?
之前的一些Re-ID方法中都会选择一些高维度的特征来存储Re-ID信息,但是作者在FairMOT实验中发现使用低维度的特征更适用于JDE这种MOT方法。因为在MOT的一些benchmarks中并没有那么像Re-ID那么多的数据,维度设置大了容易过拟合。
所以作者考虑到之前方法在上述三点中的不足,提出了一种多目标追踪的baseline,也就是FairMOT,就是这么简单。
那么下面给出相关论文和代码:
论文:FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
代码:https://github.com/ifzhang/FairMOT
2 FairMOT网络结构详解
我觉得论文中已经对FairMOT的网络结构说的足够清楚了哈。考虑到目前的Anchor-Based方法不能用了,便使用了Anchor-Free目标检测范式来代替,最常见的Anchor-Free目标检测范式由CornerNet、CenterNet等等,这块的解析我给出以下链接帮助大家入门。
周威:【Anchor free】CornerNet 网络结构深度解析(全网最详细!)zhuanlan.zhihu.com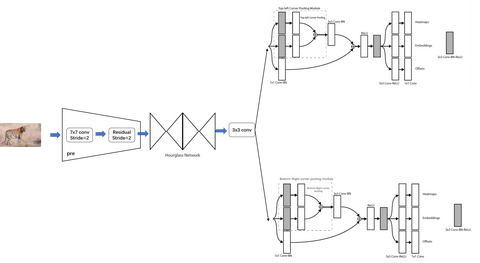
周威:【Anchor free】CornerNet损失函数深度解析(全网最详细!)zhuanlan.zhihu.com
周威:【Anchor Free】CenterNet的详细解析zhuanlan.zhihu.com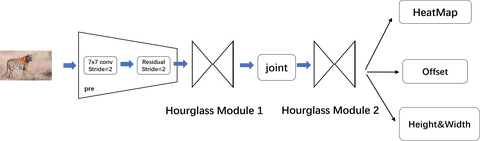
其实anchor-free的方法就是一种基于关键点检测的方法。目前最常见的就是检测物体的中心点。本文中正是采用了基于中心点检测的anchor-free方法,该方法可以有效解决上述讨论的问题1.1。借用原图中的说明(anchor-free方法基本上没有什么网络模糊性,中心点没什么大的偏移问题)

那么在FairMOT中,这个基本的特征提取网络长什么样呢?
作者选择了一个叫做DLA( Deep Layer Aggregation)的网络进行特征提取,这个网络的最大特点就是多层融合(恰好符合Re-ID信息需要多层信息融合的特点)。
当然了,和分类任务或者基于anchor的检测任务不同(这些任务往往不需要多高的输出分辨率),基于关键点的检测(anchor-free)往往需要分辨率更高(一般为stride=4)的输出特征图,这样不会产生较大的中心点偏移了。所以作者采用了一种形似encoder-decoder的DLA网络作为特征提取,如下图所示。
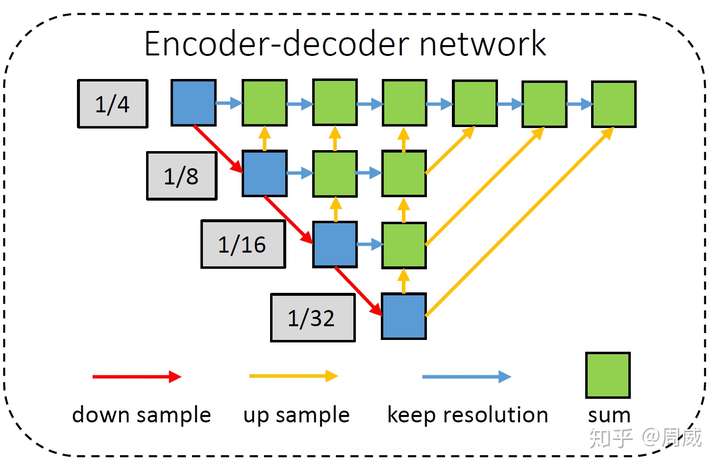
Encoder-decoder网络提取的(stride=4)高分辨率特征图将被作为四个分支的特征图。其中三个被用来检测物体(Detection),一个被用来输出物体的Re-ID信息(Re-ID)。如下图所示。
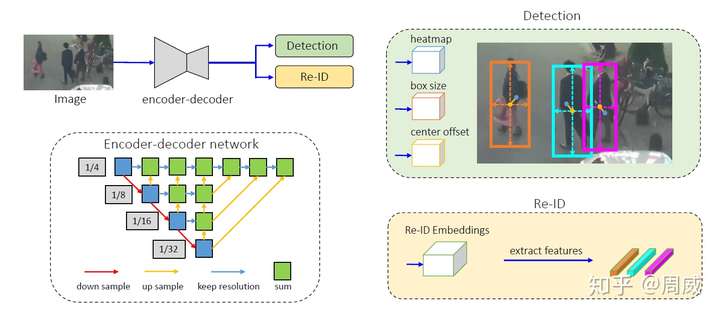
以上的每个分支都被称为一个head分支。每个head除了最后输出通道维度的不同,其组成都类似,论文中提到
Each head is implemented by applying a 3x3 convolution (with 256 channels) to the output feature maps of the backbone network, followed by a 1x1 convolutional layer which generates the nal targets.
也就是每个head由一个3x3卷积层后面接一个1x1卷积层实现的。
网络的最后输出为:
- (1)heatmap,形状为(1,H,W),这里好像和其他anchor-free方法输出的featmap不同,这里只有一个通道,而其他方法有类别数个通达(80居多)。
- (2)center offset,形状为(2,H,W),和centerNet中的offset一样,弥补由于下采样产生的轻微的offset
- (3)bbox size,形状为(2,H,W),仅仅知道中心点位置还不行,还需要用这个特征图来计算中心点对应检测框的宽高
- (4)Re-ID Embedding,形状为(128,H,W),也就是每个物体用一个128维向量表示。
我们发现,其实FairMOT的结构非常简单哈,没有什么多花哨的东西。
3 FairMOT损失函数
3.1 heatmap损失函数
还有一些细节包括如何将物体的中心映射到heatmap上,这在之前对CenterNet,CenterTrack的解析中也提到过。作者按照高斯分布将物体的中心映射到了heatmap上,然后使用变形的focal loss进行预测的heatmap和实际真实的heatmap损失函数的求解,公式如下:
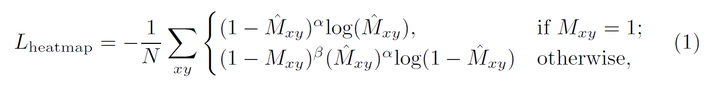
这里的 是预测的heatmap特征图,
是heatmap的ground-truth。
有关检测大小和偏移的损失函数,设置的更为简单。
3.2 Offset和Size 损失
作者仅仅用了两个L1损失就实现了。
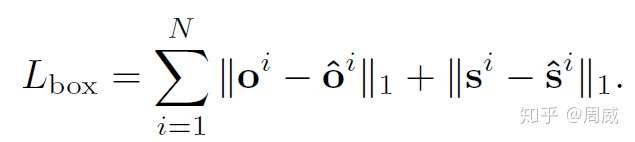
上述中N为一个图中物体总数量。带hat的符号,如 和
分别为偏移的预测特征图与大小的预测特征图。其ground-truth特征图分别设置如下:
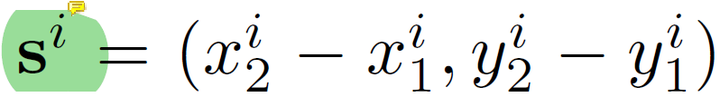
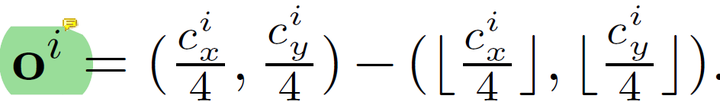
这里的 为物体的左上角坐标,
为物体右下角的坐标,
为物体的中心坐标。
3.3 Re-ID的Embedding损失
和JDE一样,FairMOT中的Embedding也是需要借助分类(按照物体ID为不同物体分配不同的类别)进行学习的。那么分类的话自然需要softmax损失啦!
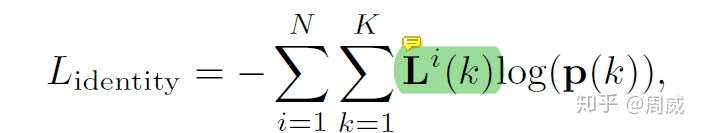
这里的 为第k个物体的预测的类别(ID编号)可能性分布,
为第k个物体真实的one-hot编码。
至此 ,有关FairMOT的网络结构和损失函数就讲解结束了。获得物体的位置和Re-ID信息后,配合卡尔曼滤波求解其代价矩阵(cost matrix),然后利用匈牙利算法进行匹配,FairMOT就结束了。
4 总结
总体来说,FairMOT正如他的论文名说的那样,是一个很简单好用的多目标追踪Baseline。非常推荐大家去读一下原文,原文的结构也是我非常喜欢的叙述结构。
这篇文章中如果存在错误解读,欢迎批评指正!我们共同学习!
5 代码解读
https://blog.csdn.net/kittyzc/article/details/107198055