7、控制语句
if(condition) {statments} 单分支语句
if(condition) {statments} else {statements}组合语句
while(conditon) {statments} while循环
do {statements} while(condition) do循环
for(expr1;expr2;expr3) {statements} for循环
break 控制语句
continue
delete array[index] 从数组中删除指定元素
delete array 删除整个数组
exit
{ statements } 组合语句
7.1 if-else
语法:if(condition) statement [else statement]
# awk -F: '{if($3>=500){print $1,$3}}' /etc/passwd //单分支if语句
# awk -F: '{if($3>=1000) {printf "Common user: %s ",$1} else {printf "root or Sysuser: %s ",$1}}' /etc/passwd 有else是属于分支
# awk -F: '{if($NF=="/bin/bash") print $1}' /etc/passwd 显示为bash的用户
# awk '{if(NF>5) print $0}' /etc/fstab 空白字符大于5个 //前面没有指定分隔符,所以默认空白就是分隔符
# df -h | awk -F[%] '/^/dev/{print $1}' | awk '{if($NF>=20) print $1}'
使用场景:对awk取得的整行或某个字段做条件判断;
7.2 while循环
语法:while(condition) statement
条件“真”,进入循环;条件“假”,退出循环;
使用场景:
对一行内的多个字段逐一类似处理时使用;
对数组中的各元素逐一处理时使用;
内键函数length()
1、显示文件中每一个符合条件的行,行内每一个字段,它的字段本身以及字段个数
# awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {print $i,length($i); i++}}' /etc/grub2.cfg
//$i是字段本身 length($i)是字段的长度 i++之所以要和print都是循环体,一起括在花括号中
2、显示字符个数大于等于7的字段
# awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=7) {print $i,length($i)}; i++}}' /etc/grub2.cfg
7.3 do-while循环
语法:do statement while(condition)(先循环一遍再判断)
意义:至少执行一次循环体
7.4 for循环
语法:for(expr1;expr2;expr3) statement
for(variable assignment(变量赋值);condition;iteration process) {for-body}
# awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
# awk '/^[[:space:]]*linux16/{for(i=1;i<NF;i++) {if(length($i)>7){print $i,length($i)}}}' /etc/grub2.cfg //显示字符数大于7的字段
特殊用法:
能够遍历数组中的元素;
语法:for(var in array) {for-body}
7.5 switch语句
语法:switch(expression) {case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; ...; default: statement}
7.6 break和continue
break [n]
continue 控制循环内部的字段的,不符合条件直接进入下一次循环
7.7 next
提前结束对本行的处理而直接进入下一行;控制awk的内生循环,如果不符合调价,直接进入下一行
# awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd //显示id号为偶数的用户
8、array
关联数组:array[index-expression]
index-expression:索引表达式
(1)、可使用任意字符串;字符串要使用双引号;
# awk 'BEGIN{weekdays["mon"]="monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
(2)、如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”;
若要判断数组中是否存在某元素,要使用"index in array"格式进行;
weekdays["mon"]="Monday"
若要遍历数组中的每个元素,要使用for循环;
for(var in array) {for-body}
# awk BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";for(i in weekdays) {print weekdays[i]}}'
注意:对应的变量var会遍历array的每个索引(下标);
state["LISTEN"]++
state["ESTABLISHED"]++
# netstat -tan | awk '/^tcp>/{state[$NF]++}END{for(i in state) { print i,state[i]}}'
# awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log //统计IP的访问次数
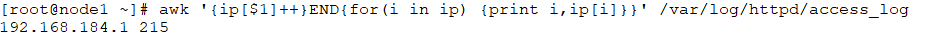
练习1:统计/etc/fstab文件中每个文件系统类型出现的次数;
# awk '/^UUID/{fs[$3]++}END{for(i in fs) {print i,fs[i]}}' /etc/fstab
练习2:统计指定文件中每个单词出现的次数;
# awk '{for(i=1;i<=NF;i++){count[$i]++}}END{for(i in count) {print i,count[i]}}' /etc/fstab
练习3:找去其中一行,并计算每个单词出现的次数
# awk 'NR==1' /etc/passwd | awk -F: '{for(i=1;i<=NF;i++){count[$i]++}}END{for(i in count){print i,count[i]}}'
9、函数
9.1 内置函数
数值处理:
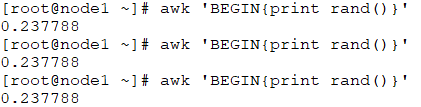
rand():返回0和1之间一个随机数;
# awk 'BEGIN{print rand()}'
字符串处理:
length([s]):返回指定字符串的长度;
sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容;
#awk -F: '{print sub(o,O,$1)}' /etc/passwd //查找$1所表示的字符串中的小写o替换成大写O
gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容;
split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;
统计每一个客户端IP对服务器建立了多少连接
# netstat -tan | awk '/^tcp>/{split($5,ip,":");count[ip[1]]++}END{for (i in count) {print i,count[i]}}'

9.2 自定义函数
《sed和awk》可不看
《Linux命令行与shell脚本编程指南》必须要看
DNF新一代的RPM软件包管理器。他首先出现在 Fedora 18 这个发行版中。而最近,他取代了YUM,正式成为 Fedora 22 的包管理器。
DNF包管理器克服了YUM包管理器的一些瓶颈,提升了包括用户体验,内存占用,依赖分析,运行速度等多方面的内容。
DNF使用 RPM, libsolv 和 hawkey 库进行包管理操作。尽管它没有预装在 CentOS 和 RHEL 7 中,但你可以在使用 YUM 的同时使用 DNF 。
DNF 的最新稳定发行版版本号是 1.0,发行日期是2015年5月11日。 这一版本的额 DNF 包管理器(包括在他之前的所有版本) 都大部分采用 Python 编写,发行许可为GPL v2.
Dependency resolution of YUM is a nightmare and was resolved in DNF with SUSE library ‘libsolv’ and Python wrapper along with C Hawkey.
YUM don’t have a documented API.
Building new features are difficult.
No support for extensions other than Python.
Lower memory reduction and less automatic synchronization of metadata – a time taking process.