经过一段时间的学习,发现对CAP的理解还是存在较大的偏差。总结下方便以后复习,也为进一步的理解打好基础。
定义:在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
一致性(C):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
这里的一致性与我们平常了解ACID的一致性有点偏差,ACID的一致性关注的是数据库的数据完整性。
上面定义没说明是所有节点必须在同一时间数据一致,而关注点在客户端,假如有个场景,您在ATM(客户端)往某张银行卡存500元后,立刻在ATM发起查询余额的时候会显示加了500元后的余额,随后我们也能把这500元取出来。查询余额读操作可以是写后立刻读的主库,也或者写后某个时间段过后(中途无写)读从库。
可用性(A):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
这里的可用性和我们平常所理解的高可用性有点偏差,高可用性指系统无中断的执行其功能的能力。
已故障的节点就不具有可用性了,因为请求结果要么error要么 timeout。合理的响应没有说明是成功还是失败,但是响应应该具有是否成功的精确描述。例如我们读取sql server集群的某从库,同步需要时间,读取出来可能不是最新的数据,但却是合理的响应。
分区容错性(P):当出现网络分区后,系统能够继续“履行职责”。
假如做了一个redis的一主两从的集群,某天某个从节点因为网络故障变成不可用,但是另外的一主一从仍然能正常运作,那么我们认为它具有分区容错性。
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
CP:为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。

AP:为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
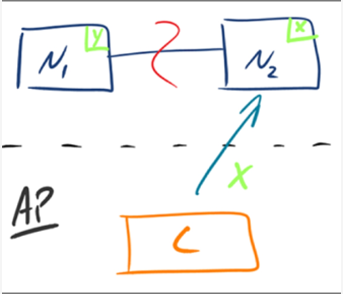
总结:在分析一个功能是CP,还是AP,应当从 系统发生分区状况的时候,系统如何做出相应出发,如果系统返回ERROR或者timeout 则是CP,如果系统返回一个合适的值则是AP 。分析下zookeeper , 在发生网络分区时,zookeepr 集群不对外提供服务(timeout),所以是个CP 。