机器翻译:
机器翻译的任务可以看成是将一种源语言词序列转换成语义相等的另一种目标语言词序列。从某种意义上来看,它完成的是某一项序列转换任务,即将一个序列对象通过模型、算法按照某种知识、逻辑转换成为另外一个序列对象。现实生活中有许多的任务场景都是在完成序列对象之间的转换任务,机器翻译任务中的语言只是其中一种序列对象类型。因此,当源语言和目标语言的概念从语种延申到其他对象类型时,机器翻译技术、方法就可以应用于解决许多类似的转换任务。
Why Attention ?
基于编码器~解码器框架的神经机器翻译模型在翻译比较短的句子时效果还不错,当翻译比较长的句子时,翻译质量会严重的下降,而注意力机制的引入进一步提高了编码器~解码器框架在长句子上的翻译质量,使得神经机器翻译模型的翻译全面超越了传统的基于对数线性模型的方法。
Attention:
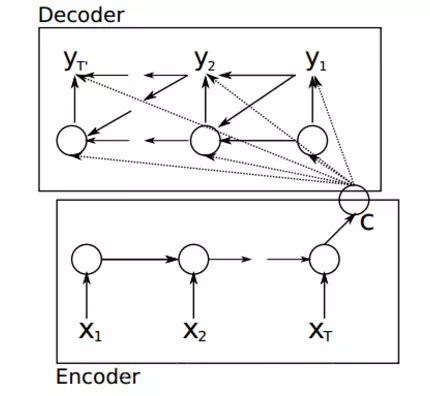
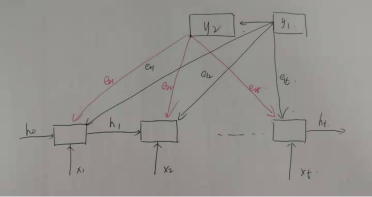
其中 C 就是注意力机制,现在让我们一点一点解开注意力机制的面纱,其中源语言 x 的隐状态用 h 表示,目标语言的隐状态用 s 来表示。
Encoder:
ht = RNN ( Xt,ht-1)
Decoder:
P(y) = { yt | (y1,..........,,yt-1,C ) } = f ( yt-1,st,C)
其中 st = g ( st-1,yt-1,Ct)
Attention:
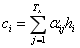


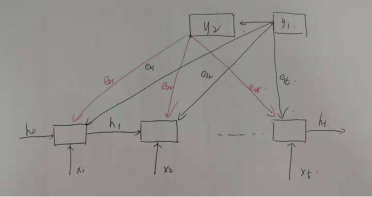
首先我们先观察 eij :
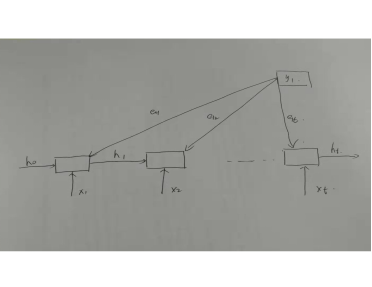
其中函数 a 是匹配函数,当翻译第一个词 y1 的的时候,其前一时刻的隐藏状态为 S0 :
则生成的第一个词时,计算其前一时刻隐藏状态和每一个源语言词的隐藏状态的匹配因子 e1j
同理生成第二个词的时候,其前一时刻的隐藏状态为 S1
则生成的第二个词时,计算其前一时刻隐藏状态和每一个源语言词的隐藏状态的匹配因子 e2j
依次类推
其次我们观察公式二:
其中参数 i 代表的是目标语言的序号,参数 j 代表的是源语言的序号。
则翻译第一个词的时候有:

其实相当于对每一个词的匹配因子经过了 softmax 函数层的归一化匹配概率。
最终我们观察注意力向量 Ci :
该步骤相当将翻译目标词时根据目标词和每个源语言词的比重重新联结之后生成一个新的注意力向量
例如:
当翻译第一个词的时候有:
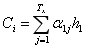

其他以此类推。
Why Transformer ?
注意力网络通过将源语言句子的隐状态和目标语言句子的隐状态直接链接,从而缩短了源语言词的信息到对应目标语言词的传递路径,显著的提高了翻译的质量。
(1)基于循环神经网络的编码器和解码器的模型,每一个词的隐含状态都严重依赖于前一个词的信息,所以编码的状态时顺序生成的,这严重影响了模型的并行能力。
(2)尽管基于门控单元的循环神经网络可以解决循环神经网络的梯度消失、爆炸的问题,但是相距太远的词的信息仍然不能保证被考虑进来。
(3)尽管卷积神经网络可以提高模型并行化的能力,然而其只能考虑一定窗口内的历史信息。
为了解决上述问题,我们可以将两个额外的注意力网络引入编码器和解码器的内部,分别用于解决源语言句子和目标语言句子内部词语之间的依赖关系。
Transformer:
编码器:(1)自关注分组注意力网络(2)前馈式网络
解码器:(1)掩码自关注分组注意力网络(2)分组注意力网络(3)前馈式网络

自注意力机制:
自注意力机制就是源语言和目标语言相同的注意力机制。
当我们将注意力机制中源语言和目标语言的隐状态分别用 Q和K来表示,将翻译目标词时当前词的权重用V来表示,则有:

但是在实际运算时,在使用softmax函数将计算得到的相似度归一化为权重,如果权重分布的非常不均匀,则反向传播时会产生一个非常大的梯度值,这时我们可以通过引入一个温度因子来解决这个问题,温度因子一般设为向量长度(dk)的平方根,则有:
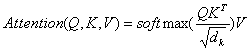
如果我们在计算注意力相似度的时候采用点积来计算匹配函数的时候,就是缩放的点积注意力网络。
分组注意力网络(编码器)
与传统的注意力机制只使用一个注意力网络不同,分组的注意力网络将多个注意力网络进行拼接。
具体的给定(Q,K,V):
(1)通过不同的线性映射将Q,K,V映射到不同的高维空间内
(2)然后计算不同空间得到的上下文向量
(3)最后将这些上下文向量拼接得到最终的输出
前馈式神经网络(编码器):
其作用是将自注意力网络生成的源语言句子的上下文向量同当前词的信息进行整合,从而生成考虑了整个句子上下文的当前时刻的隐含状态。
掩码自关注分组注意力网络(解码器):
不同与编码器中的自注意力网络,解码器在解码的时候只能够看到已经生成的词的信息,对于未生成的内容,使用掩码机制将其屏蔽掉。
分组注意力网络(解码器):
负责将源语言句子的隐含状态同目标语言的隐含状态进行连接生成源语言句子的上下文向量。
全连接神经网络(解码器):
将自注意力网络生成的目标语言的上下文向量、源语言句子的上下文向量以及当前词的信息进行整合从而更好地预测下一个目标词。
残差链接和层规范化技术是被用来优化模型。