看到一篇关于加密的论文很好玩。类似于二维码一样,但是呈现形式只是普通的文章,但是对普通文章的字体进行细微的肉眼察觉不出的变化,然后将要加密的信息保存在这些变化里。之后用软件扫描这篇加了密的普通文章,计算机找出那些有细微字形变化的字母,然后还原出加密信息的内容。我初步理解的步骤如下。
第一步
先创建一个密码本,其中对英文字母进行变形。比如下图的a,可以看到其字形有细微的变化,比如橙色的a下面的圈要明显比天蓝色的中间那个a的圈要大,同时每个a右下方向上提的小尾巴的弯曲度也是不同的。
这样,在密码本中就将不同字体跟特定的数字一一对应起来,比如最左边的绿色a代表0,橙色a代表1

第二步
接下来,把想隐藏(加密)的文字先转换成数字,这里想隐藏的文字是“Hello World”这两个单词。转换为数字的办法是把他们变成ASCII码等等。我不知道这个例子里面是把它转换成了什么码。总而言之,是把“Hello World”根据一个固定的编码方式变成数字。而这个数字的逆转换是肯定会得到“Hello World”这两个词的。
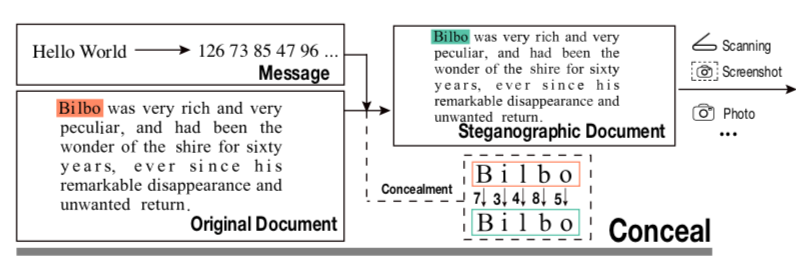
第三步
然后把从Hello World转换成的数字(126 73 85。。。)隐藏在一篇普通的文章中(Bilbo was very rich and。。。),这里先将普通文章切割成5个字母5个字母的小块,在Bilbo这篇文章中,就可以切割成这样(Bilbo wasve ryric。。。。)。刚才第一步里面说了,不同字体形状是在密码本中一一对应一个数字的。所以大体的思路可以是,在密码本的B中找出代表数字1的B的变形,然后i中找出代表2的变形,l中找出代表6的变形,这样就可以在Bil这三个字母隐藏住126这三个数字,也就是说把H这个字母隐藏进去了。实际上改论文并非如此操作,他还会为了保证加密信息不会因为缺失部分文章段落二丢失,特意进行了冗余编码。具体细节没明白。
第四步
就是用OCR和CNN来识别出文章里面变了形的字母,从而解读出里面隐藏的文字,跟扫二维码一样。比如下面就是将该海报的Youtube链接镶嵌在了普通的文字描述中。

