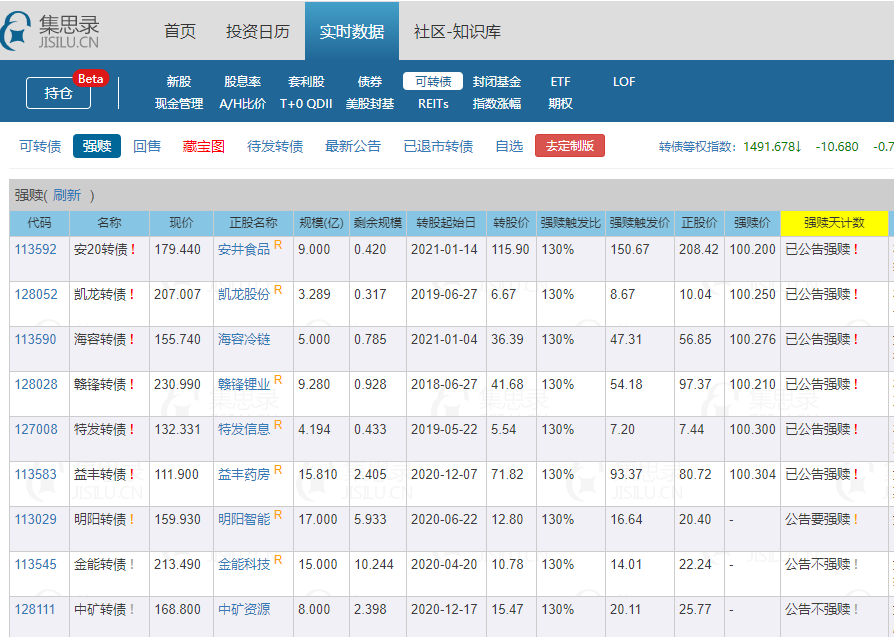
集思录强赎表爬取:
网页样式
实现代码
import requests
import pandas as pd
url = 'https://www.jisilu.cn/data/cbnew/redeem_list/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36' } response = requests.post(url = url,headers=headers) jsl_qiangsu_json = response.json()['rows'] df_jsl = [] for i in range(0,len(jsl_qiangsu_json)): df_jsl.append(jsl_qiangsu_json[i]['cell']) df = pd.DataFrame(df_jsl) df['redeem_count']=df['redeem_count'].str.replace('<span style="color:red;">','') df['redeem_count']=df['redeem_count'].str.replace('</span>','') df['redeem_count']=df['redeem_count'].str.replace('<span title=','') df['redeem_count']=df['redeem_count'].str.replace('style="color:gray;">','') df.to_csv('jslqs.csv',encoding = 'gbk')