(resilient distributed dataset,RDD)是一个非常重要的分布式数据架构,即弹性分布式数据集。
它是逻辑集中的实体,在集群中的多台机器上进行了数据分 区。通过对多台机器上不同RDD分区的控制,就能够减少机器之间的数据重排(data shuffling)。Spark提供了“partitionBy”运算符,能够通过集群中多台机器之间对原始RDD进 行数据再分配来创建一个新的RDD。RDD是Spark的核心数据结构,通过RDD的依赖关系形 成Spark的调度顺序。通过对RDD的操作形成整个Spark程序。
(1)RDD的两种创建方式
1)从Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、 Cassandra、Hbase)输入(如HDFS)创建。
2)从父RDD转换得到新的RDD。
(2)RDD的两种操作算子 对于RDD可以有两种计算操作算子:Transformation(变换)与Action(行动)。
1)Transformation(变换)。 Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的转换操 作不是马上执行,需要等到有Actions操作时,才真正触发运算。
2)Action(行动) Action算子会触发Spark提交作业(Job),并将数据输出到Spark系统。
(3)RDD的重要内部属性
1)分区列表。
2)计算每个分片的函数。
3)对父RDD的依赖列表。
4)对Key-Value对数据类型RDD的分区器,控制分区策略和分区数。
5)每个数据分区的地址列表(如HDFS上的数据块的地址)。
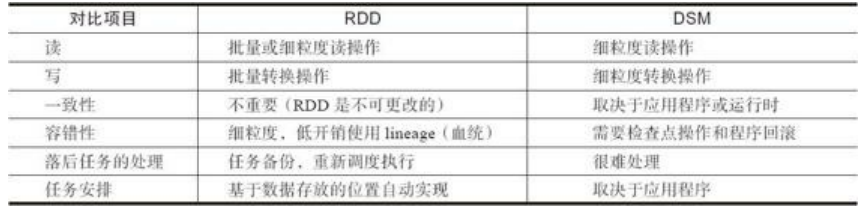
RDD与分布式共享内存的异同
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比。在DSM系统中,应用可以向全局地址空间的任意位置进 行读写操作。DSM是一种通用的内存数据抽象,但这种通用性同时也使其在商用集群上实现 有效的容错性和一致性更加困难。 RDD与DSM主要区别在于,不仅可以通过批量转换创建(即“写”)RDD,还可以对任 意内存位置读写。RDD限制应用执行批量写操作,这样有利于实现有效的容错。特别是,由 于RDD可以使用Lineage(血统)来恢复分区,基本没有检查点开销。失效时只需要重新计 算丢失的那些RDD分区,就可以在不同节点上并行执行,而不需要回滚(Roll Back)整个程序。
RDD任务划分
RDD任务切分中间分为:Application、Job、Stage和Task
1)Application:初始化一个SparkContext即生成一个Application
2)Job:一个Action算子就会生成一个Job
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
4)Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
注意:Application->Job->Stage-> Task每一层都是1对n的关系。
例: wordCount
