be-quick-or-be-dead-1
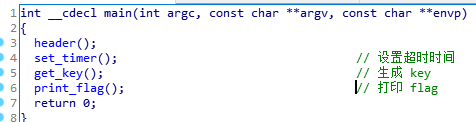
程序逻辑比较简单:
- 设定一个时间计数器,一旦某个函数运行超时就退出
- get_key :生成一个固定的key值
- print_flag : 将 flag 打印出来。因为get_key 超时,导致无法执行到该函数
- 这题如果爆破,估计直接能出结果(将set_timer直接nop掉。)
看别人的wp,patch可以将超时设置到8s,或者将set_timer 直接retn
从IDA 获取数据
flag = 0x0000000000601080
ret = []
for b in get_bytes(flag, 59): // 返回的是str
ret.append(hex(ord(b)))
print ret
得到16进制的数组
['0x52', '0x4b', '0x9e', '0x8a', '0x60', '0x76', '0xbb', '0x9e', '0x53', '0x4a', '0x84', '0xba', '0x47', '0x4d', '0x89', '0x8d', '0x43', '0x50', '0xa2', '0x81', '0x48', '0x4b', '0x93', '0x82', '0x77', '0x57', '0x93', '0x8b', '0x4c', '0x41', '0x98', '0x96', '0x59', '0x43', '0x8f', '0x9c', '0x74', '0x41', '0x92', '0x88', '0x5c', '0x57', '0x89', '0x84', '0x59', '0x4b', '0x92', '0x8b', '0x71', '0x46', '0xcd', '0x86', '0x19', '0x43', '0x9c', '0x86', '0x55', '0x5f', '0x0']核心加密算法
// key = 0xE5FD2222LL
__int64 __fastcall decrypt_flag(int key)
{
__int64 result; // rax
int v2; // [rsp+0h] [rbp-14h]
unsigned int i; // [rsp+10h] [rbp-4h]
v2 = key;
for ( i = 0; ; ++i )
{
result = i;
if ( i > 0x39 )
break;
flag[i] ^= *((_BYTE *)&v2 + (signed int)i % 4);
if ( (signed int)i % 4 == 3 )
++v2;
}
return result;
}
核心就在这句话:
flag[i] ^= *((_BYTE *)&v2 + (signed int)i % 4);v2 是一个int类型:
- &v2: 取int的地址,也就是一个指向v2的整型指针
- (byte *)&v2 :将 int 类型指针转换为 byte 类型
- (byte *)&v2 + i % 4:每次取一个 byte
- 所以整句的意思是,每次取 key 的一个byte出来,进行xor
- 后面 i%4 == 3,也就是四次就把 key + 1
写出解密代码。
flag = ['0x52', '0x4b', '0x9e', '0x8a', '0x60', '0x76', '0xbb', '0x9e', '0x53', '0x4a', '0x84', '0xba', '0x47', '0x4d', '0x89', '0x8d', '0x43', '0x50', '0xa2', '0x81', '0x48', '0x4b', '0x93', '0x82', '0x77', '0x57', '0x93', '0x8b', '0x4c', '0x41', '0x98', '0x96', '0x59', '0x43', '0x8f', '0x9c', '0x74', '0x41', '0x92', '0x88', '0x5c', '0x57', '0x89', '0x84', '0x59', '0x4b', '0x92', '0x8b', '0x71', '0x46', '0xcd', '0x86', '0x19', '0x43', '0x9c', '0x86', '0x55', '0x5f', '0x0']
key = ['0x22', '0x22', '0xFD', '0xE5'] #转换为数组
ret = []
for i in range(0x3a):
c = int(flag[i], 16)
c ^= int(key[i % 4], 16)
ret.append(chr(c))
print key
if i % 4 == 3:
key[0] = hex(int(key[0], 16) + 1)
print ''.join(ret)
得到结果:
picoCTF{why_bother_doing_unnecessary_computation_d0c6aace}be-quick-or-be-dead-2
相比于第一题,有两点变化:
- set_timer 超时默认从1s变为8s
- get_key 中使用了 fib 函数来生成key,而不是直接返回
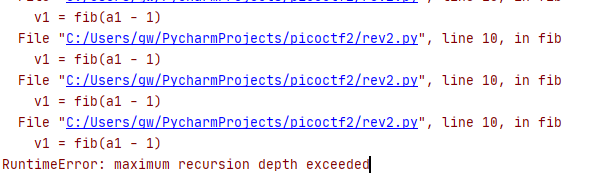
尝试着用python递归实现fib,发现直接超出了递归的最大限制次数:
# fib递归的算法会严重超时
def fib(a1):
v1 = 0
v3 = 0
if(a1 > 1):
v1 = fib(a1 - 1)
v3 = v1 + fib(a1 - 2)
else:
v3 = a1
return v3
提示 max recursion depth exceeded
典型的斐波拉契数列,wiki 一下就知道,有多种算法实现:
- 递归实现
- 非递归(利用数组,循环即可)
- 快速矩阵幂 (涉及到矩阵乘法)
非递归的方法最简单,自己实现一个:
from ctypes import *
def fib2(n):
input= {}
input[0] = 0
input[1] = 1
for i in range(2, n+1):
input[i] = input[i-1] + input[i-2]
input[i] = c_uint(input[i]).value
return hex(input[n])
个人遇到的最大问题是python中的变量,如何转换为 c 语言类型。
使用 ctype 类,文档中给出了各种数据类型的关键字:
| ctypes type | C type | Python type |
|---|---|---|
c_bool | _Bool | bool (1) |
c_char | char | 1-character string |
c_wchar | wchar_t | 1-character unicode string |
c_byte | char | int/long |
c_ubyte | unsigned char | int/long |
c_short | short | int/long |
c_ushort | unsigned short | int/long |
c_int | int | int/long |
c_uint | unsigned int | int/long |
c_long | long | int/long |
c_ulong | unsigned long | int/long |
c_longlong | __int64 or long long | int/long |
c_ulonglong | unsigned __int64 or unsigned long long | int/long |
c_float | float | float |
c_double | double | float |
c_longdouble | long double | float |
c_char_p | char * (NUL terminated) | string or None |
c_wchar_p | wchar_t * (NUL terminated) | unicode or None |
c_void_p | void * | int/long or None |
本题需要将结果转换为 unsigned long,所以选择 c_uint 即可。注意一点,这里只做了类型转换,还需要提取value,否则系统会提示操作符类型不一致。

接下来将 calculate_key 中的 call fib => mov eax, 5D023A41
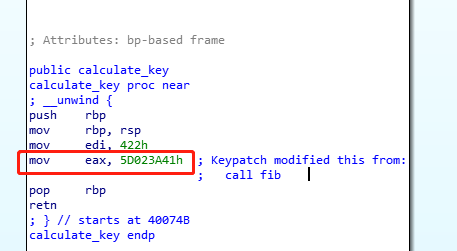
运行patch之后的程序,得到flag
be-quick-or-be-dead-3
相比第二题,第三题仅仅是生成key的算法有区别:
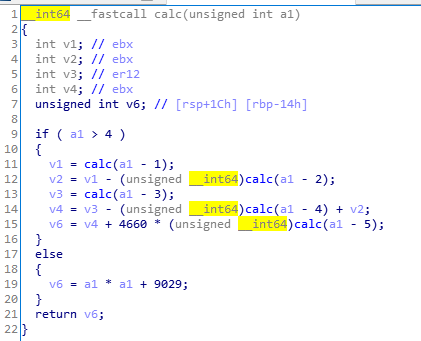
很明显,还是个递归算法导致运行超时。根据前面的经验,直接写出T(N)的算法:
from ctypes import *
def quick3(n):
input = {}
for i in range(5):
input[i] = i*i + 9029
for i in range(5, n + 1):
v2 = input[i-1] - input[i-2]
v4 = input[i-3] - input[i-4] + v2
input[i] = v4 + 4660 * input[i-5]
input[i] = c_uint(input[i]).value
return hex(input[n])
print quick3(0x186B5) ##0x221d8eea
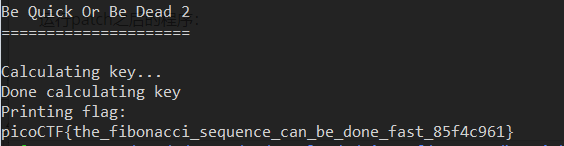
在同样的位置进行patch,运行patch之后的程序,得到flag:
Be Quick Or Be Dead 3
=====================
Calculating key...
Done calculating key
Printing flag:
picoCTF{dynamic_pr0gramming_ftw_a0b0b7f8}
至此,三道题目完成。
小结
通过三个习题新学习到以下内容
- 如何利用 ida 的 keypatch 插件对程序进行patch
- 如何利用ctypes进行数据类型转换
- 加入 #encoding=utf-8 后,才能写中文注释
- 程序的超时机制。例如这里是 3s 之后 alarm,并调用 alarm_handler 函数
unsigned int set_timer()
{
if ( __sysv_signal(14, alarm_handler) == (__sighandler_t)-1LL )
{
printf(
" Something went terribly wrong. Please contact the admins with "be-quick-or-be-dead-3.c:%d". ",
59LL);
exit(0);
}
return alarm(3u);
}
quackme
核心就在 do_magic 函数中。简单分析后对变量进行重命名,大致逻辑是:
- 通过read_input 获取用户输入
- 创建与用户输入同等大小的空间,并用 v5 指向该位置
int do_magic()
{
int result; // eax
int cnt; // [esp+Ch] [ebp-1Ch]
int i; // [esp+10h] [ebp-18h]
char *input; // [esp+14h] [ebp-14h]
signed int input_len; // [esp+18h] [ebp-10h]
void *v5; // [esp+1Ch] [ebp-Ch]
input = (char *)read_input();
input_len = strlen(input);
v5 = malloc(input_len + 1);
if ( !v5 )
{
puts("malloc() returned NULL. Out of Memory ");
exit(-1);
}
memset(v5, 0, input_len + 1);
cnt = 0;
for ( i = 0; ; ++i )
{
result = i;
if ( i >= input_len )
break;
if ( greetingMessage[i] == (*(_BYTE *)(i + 0x8048858) ^ (unsigned __int8)input[i]) )
++cnt;
if ( cnt == 25 )
return puts("You are winner!");
}
return result;
}
核心就在这里:
greetingMessage[i] == (*(_BYTE *)(i + 0x8048858) ^ (unsigned __int8)input[i])可以看到,从 0x8048858 位置逐个字节取出,与用户输入进行 xor。
0x8048858的内容为(ctrl+g 进行跳转):
将内容拷贝出来(shift + e)
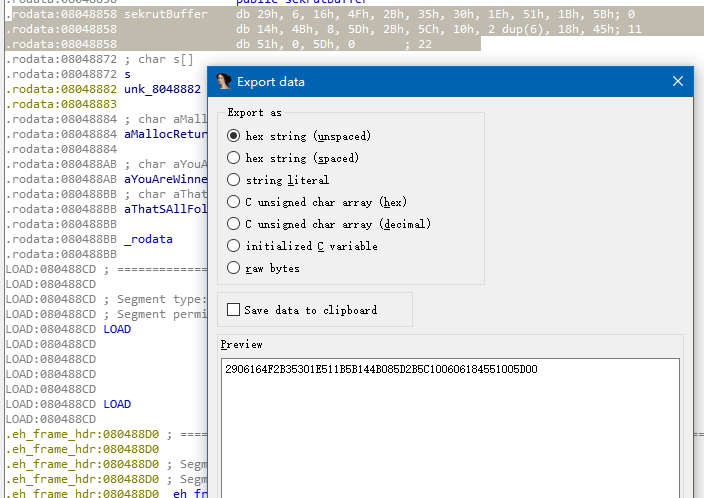
greetingMessage的内容同上进行获取。
最后写出逆向算法:
ret = []
buf = '2906164F2B35301E511B5B144B085D2B5C100606184551005D'
gre = '596F752068617665206E6F7720656E74657265642074686520'
for i in range(0,25):
char1 = int('0x' + buf[i*2:i*2+2], 16)
char2 = int('0x' + gre[i*2:i*2+2], 16)
char3 = chr(char1 ^ char2)
#print char3
ret.append(char3)
print ''.join(ret)
# 得到答案:picoCTF{qu4ckm3_9bcb819e}
assembly-02
What does asm2(0xe,0x21) return? Submit the flag as a hexadecimal value (starting with '0x'). NOTE: Your submission for this question will NOT be in the normal flag format. Source located in the directory at /problems/assembly-2_3_c3ee3603bd2a8e682f1d64cf6dfd21fb.
也是一段汇编代码:
.intel_syntax noprefix
.bits 32
.global asm2
asm2:
push ebp
mov ebp,esp
sub esp,0x10
mov eax,DWORD PTR [ebp+0xc] ;0x21
mov DWORD PTR [ebp-0x4],eax ;ebp-0x4 => 0x21
mov eax,DWORD PTR [ebp+0x8] ;0xE
mov DWORD PTR [ebp-0x8],eax ;ebp-0x8 => 0xE
jmp part_b
part_a:
add DWORD PTR [ebp-0x4],0x1
add DWORD PTR [ebp+0x8],0x41
part_b:
cmp DWORD PTR [ebp+0x8],0x9886
jle part_a
mov eax,DWORD PTR [ebp-0x4]
mov esp,ebp
pop ebp
ret
很容易写出对应的代码:
cnt = 0xe
ret = 0x21
while ( cnt < 0x9886):
ret += 1
cnt += 0x41
print hex(ret)
## picoCTF('0x27a')
radix's terminal
丢到ida,程序逻辑很简单:
- 用户输入一个参数
- 如果参数经过 check_password 计算,相等就提示成功
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
setvbuf(_bss_start, 0, 2, 0);
if ( argc > 1 )
{
if ( (unsigned __int8)check_password((char *)argv[1]) )
{
puts("Incorrect Password!");
result = -1;
}
else
{
puts("Congrats, now where's my flag?");
result = 0;
}
}
else
{
puts("Please provide a password!");
result = -1;
}
return result;
}
看看 check_password 内容:
int __cdecl check_password(char *input)
{
void *v1; // esp
int v2; // eax
int v3; // eax
int v4; // eax
int v5; // eax
int v6; // eax
int v7; // eax
int j0; // eax
int j1; // eax
int j2; // eax
int j3; // eax
int v13; // [esp+0h] [ebp-48h]
char *ptr_input; // [esp+Ch] [ebp-3Ch]
int cnti; // [esp+10h] [ebp-38h]
int cntj; // [esp+14h] [ebp-34h]
int i; // [esp+18h] [ebp-30h]
int input_len; // [esp+1Ch] [ebp-2Ch]
size_t n; // [esp+20h] [ebp-28h]
int v20; // [esp+24h] [ebp-24h]
char *cipher; // [esp+28h] [ebp-20h]
int char0; // [esp+2Ch] [ebp-1Ch]
int char1; // [esp+30h] [ebp-18h]
int char2; // [esp+34h] [ebp-14h]
unsigned int tmp; // [esp+38h] [ebp-10h]
unsigned int v26; // [esp+3Ch] [ebp-Ch]
ptr_input = input;
v26 = __readgsdword(0x14u);
input_len = strlen(input);
n = 4 * ((input_len + 2) / 3);
v20 = 4 * ((input_len + 2) / 3);
v1 = alloca(16 * ((4 * ((input_len + 2) / 3) + 16) / 0x10u));
cipher = (char *)&v13;
cnti = 0;
cntj = 0;
while ( cnti < input_len )
{
if ( cnti >= input_len )
{
v3 = 0;
}
else
{
v2 = cnti++;
v3 = (unsigned __int8)ptr_input[v2];
}
char0 = v3;
if ( cnti >= input_len )
{
v5 = 0;
}
else
{
v4 = cnti++;
v5 = (unsigned __int8)ptr_input[v4];
}
char1 = v5;
if ( cnti >= input_len )
{
v7 = 0;
}
else
{
v6 = cnti++;
v7 = (unsigned __int8)ptr_input[v6];
}
char2 = v7;
tmp = (char1 << 8) + (char0 << 16) + v7;
j0 = cntj++;
cipher[j0] = alphabet[(tmp >> 18) & 0x3F];
j1 = cntj++;
cipher[j1] = alphabet[(tmp >> 12) & 0x3F];
j2 = cntj++;
cipher[j2] = alphabet[(tmp >> 6) & 0x3F];
j3 = cntj++;
cipher[j3] = alphabet[tmp & 0x3F];
}
for ( i = 0; mod[input_len % 3] > i; ++i )
cipher[n - 1 - i] = 61;
return strncmp(cipher, "cGljb0NURntiQXNFXzY0X2VOQ29EaU5nX2lTX0VBc1lfMjk1ODA5OTN9", n);
}
一堆变量,还有一堆移位运算。正好移位运算还没认真分析过,就拿这个练手。
通过名称替换,可以看出来大致逻辑:
- 对于用户输入,每次取一个字符,分别放在 char0/char1/char2 中,各为1个byte
- 将3个char(24bit) 拼接到 int 类型(32bit)的 tmp 中,也就是
tmp = (char0 << 16) + (char1 << 8) + char2
- 再每次取tmp的6bit内容,用该值作为index,去alphabet取字符。24/6 = 4,一共取4次
- 最后对某些字符进行模运算,更改内容为 chr(61) ## 也就是 ‘=’ 号
根据以上逻辑,写出对应的python解密代码:
#coding=utf-8
from ctypes import *
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
cipher = 'cGljb0NURntiQXNFXzY0X2VOQ29EaU5nX2lTX0VBc1lfMjk1ODA5OTN9' # len:56
xlist = []
## 找出cipher中每个字符的位置
for i in range(0, len(cipher)):
tmp = alphabet.index(cipher[i])
xlist.append(tmp)
##print xlist
ret = []
## 每4个字符一组
for j in range(1, (len(xlist)/4) + 1):
tmp = (xlist[j*4 - 4] << 18) + (xlist[j*4 -3] << 12) + (xlist[j*4 - 2] << 6) + (xlist[j*4 - 1])
c1 = c_uint8(tmp >> 16).value
c2 = c_uint8(tmp >> 8).value
c3 = c_uint8(tmp).value
ret.append("{0}{1}{2}".format(chr(c1),chr(c2),chr(c3)))
print ''.join(ret)
## 输出:picoCTF{bAsE_64_eNCoDiNg_iS_EAsY_29580993}
这不是 base64 解密么……真佩服自己,连base64算法都没看出来,还是做题太少啊。
于是用base64库验证了一下:
a = base64.b64decode('cGljb0NURntiQXNFXzY0X2VOQ29EaU5nX2lTX0VBc1lfMjk1ODA5OTN9')
print a
picoCTF{bAsE_64_eNCoDiNg_iS_EAsY_29580993}
小结一下:
- 在 list 中根据 value 查找 index,使用 list.index(value)
- 对于char 的类型运算,c_uintN 真好用
- 再也不怕位运算了
quackme up
核心就是循环移位算法的逆运算:
int __cdecl encrypt(char *s)
{
char v1; // al
signed int i; // [esp+8h] [ebp-10h]
signed int input_len; // [esp+Ch] [ebp-Ch]
input_len = strlen(s);
for ( i = 0; i < input_len; ++i )
{
v1 = rol4(s[i]);
s[i] = ror8(v1 ^ 0x16);
}
return input_len;
}
循环移位和xor都是可逆的运算,但是python中没有循环移位的算法,需要自己实现一个,参考网上的做法,写出最终代码:
#coding=utf-8
cipher = '118020E0225372A101415520A0C025E34520350570209550c1'
# 字符的循环移位
def rol(v, k, bit = 8):
'''
8bit char 的按位循环左移
:param v: 要进行移位的整数
:param k: 要移动几位?
:param bit: 位数,默认为8,对应8为整数。
:return:
'''
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[:k] + bin_value[k:]
ret = int(bin_value, 2)
return ret
def ror(v, k, bit = 8):
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[-k:] + bin_value[:-k]
ret = int(bin_value, 2)
return ret
'''
for ( i = 0; i < input_len; ++i )
{
v1 = rol4(s[i]);
s[i] = ror8(v1 ^ 0x16);
}
'''
ret = []
for i in range(0, len(cipher)/2):
c = int('0x' + cipher[i*2: i*2 + 2], 16)
# 先左移8bit
c = rol(c,8,8)
# 再与0x16 xor
c = c ^ 0x16
# 最后右移4bit
c = ror(c, 4, 8)
ret.append(chr(c))
print ''.join(ret)
# output: picoCTF{qu4ckm3_5c21fc8d}
唯一的问题,cipher 在取值的时候,不知道 shift+e 得到的结果为啥不正确。用python snippet跑出来结果也是这样,没做深究,继续做题吧。
assembly-03
看源码,是考察寄存器 eax/ah/al 知识和 sal/sub 指令
.intel_syntax noprefix .bits 32 .global asm3 ; asm3(0xb3fb1998,0xfe1a474d,0xd5373fd4) asm3: push ebp mov ebp,esp mov eax,0x62 xor al,al mov ah,BYTE PTR [ebp+0xa] sal ax,0x10 sub al,BYTE PTR [ebp+0xd] add ah,BYTE PTR [ebp+0xe] xor ax,WORD PTR [ebp+0x10] mov esp, ebp pop ebp ret
根据压栈的顺序,可以画出此时栈的结构。因为涉及到 ah/al 操作,可以将栈同时展开,用excel画出来:

几点说明:
- intel cdel压栈顺序是从右到左,所以 0xd537cfd4 最先入栈。
- ebp+4 指向了下一条指令的位置(常说的eip,做过pwn都懂)
- asm 有声明位 bits 32
- 按照小端存储,小的值在低位,大的值在高位
接下来,按照汇编指令逐步对 eax 进行操作:
| eax | ah | al | ||
|---|---|---|---|---|
| 0 | mov eax,0x62 xor al,al | |||
| fb | mov ah,BYTE PTR [ebp+0xa] ; fb | |||
| fb | sal ax,0x10 ;算数左移16位 | |||
| fb | b9 | sub al,BYTE PTR [ebp+0xd] ;47 | ||
| fb | 1a | b9 | add ah,BYTE PTR [ebp+0xe] ;1a | |
| fb | 0 | 25 | 6d | xor ax,WORD PTR [ebp+0x10] ;3fd4 |
需要说明的点:
- sub al, 47; al 为0,所以sub之后为 -47,负数存储是通过补码形式,也就是“按位取反,再加1”,所以运算过程是 47 => 0100 0111 => 1011 1000 => 1011 1001 => b9。 (不知道这个理解对不对,参考:https://blog.csdn.net/youcharming/article/details/41982239)
- xor ax,WORD PTR [ebp+0x10] ; ax 此时内容为 1ab9, WORD PTR 取两个字节,所以是 3fd4,两者进行xor,结果为 256d。
- 因此结果为 picoCTF{'0xfb00256d'},不对
- 仔细检查,数据都没错,会不会是sal问题?于是改为 picoCTF{'0x0000256d'},还是不对
- 最后看了WP,发现不用4个0…… 直接提交 picoCTF{'0x256d'}即可
https://github.com/Dvd848/CTFs/blob/master/2018_picoCTF/assembly-3.md 这个wp不知道怎么生成的字节图)
assembly-04
从下载文件的后缀名就能看出,这是需要nasm编译:
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ nasm -f elf32 comp.nasm comp nasm: error: more than one input file specified type `nasm -h' for help giantbranch@ubuntu:~/rev/picoctf/assembly-04$ nasm -f elf32 comp.nasm -o comp giantbranch@ubuntu:~/rev/picoctf/assembly-04$ ls comp comp.nasm
根据 ctf-all-in-one 的介绍,此时生成的是.o文件,还需要 ld:
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ gcc -o demo comp
/usr/bin/ld: i386 architecture of input file `comp' is incompatible with i386:x86-64 output
collect2: error: ld returned 1 exit status
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ gcc -o demo comp -m32
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ ls
comp comp.nasm demo
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ ./demo
picoCTF{1_h0p3_70u_c0mP1l3d_tH15_2390040222}
giantbranch@ubuntu:~/rev/picoctf/assembly-04$ 但是提交一直不对,后来看到有人wp写了,根据:https://piazza.com/class/jkimphnvxey1qo?cid=65 对flag进行了调整。但是这个网站又打不开……
后来总算搞明白了,piazza 是类似于学生的论坛,里面有勘误信息:
Problem Statuses This Post will contain the Status Information of the current problems (X means the problem is currently down) or when the last change was made (if at all). Please note that we have due to unintentional flag leaking we have redeployed some problems, which could result in a loss of points, please go and solve them again using an intended solution! March 27, 2019 Update
针对这一题,是有调整的:
If your flag does not work, EITHER replace the trailing '3's at the end with a '}' OR change '2390040222' to '2350040222' and change '70u' to 'y0u
所以,提交的时候需要改为:
picoCTF{1_h0p3_y0u_c0mP1l3d_tH15_2350040222}
keygen-me-1
先在 IDA 看代码:
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
setvbuf(_bss_start, 0, 2, 0);
if ( argc > 1 )
{
if ( (unsigned __int8)check_valid_key((char *)argv[1]) )// 输入长度16位,必须是数字和大写字母
{
if ( validate_key((char *)argv[1]) )
{
printf("Product Activated Successfully: ");
print_flag();
result = 0;
}
else
{
puts("INVALID Product Key.");
result = -1;
}
}
else
{
puts("Please Provide a VALID 16 byte Product Key.");
result = -1;
}
}
else
{
puts("Usage: ./activate <PRODUCT_KEY>");
result = -1;
}
return result;
}逻辑很简单:
- 先用 check_valid_key 查看用户输入内容是否为数字+大写字母,且长度为16位
- 再用 validate_key 验证用户输入,如果正确就输出flag
看看 validate_key 的代码:
bool __cdecl validate_key(char *input)
{
unsigned int v2; // [esp+4h] [ebp-14h]
int i; // [esp+8h] [ebp-10h]
size_t input_len; // [esp+Ch] [ebp-Ch]
input_len = strlen(input);
v2 = 0;
for ( i = 0; (signed int)(input_len - 1) > i; ++i )
v2 += ((char)ord(input[i]) + 1) * (i + 1);
return v2 % 0x24 == (char)ord(input[input_len - 1]);
}逻辑很简单,只要最后的ord值 = v2 % 0x24即可。显然,最后一位为校验位。
很快用python写出逆向代码,假定前15位都为1,计算出最后一位:
input = '1' * 15
v2 = 0
## 假定前15个数字都为1
for i in range(0,15):
v2 += (ord(input[i]) + 1) * (i + 1)
v15 = v2 % 0x24
print input + chr(v15)
但是结果一直不对,一堆不可见字符……
回归头仔细分析了validate_key,发现 v2 % 0x24的结果必然小于 0x24,也就是 key 的最后一位不可见,这与逻辑相互矛盾啊。
当时心里就有个疑问,c 语言怎么会有 ord 函数呢?还特意man ord 查看,发现没有。我们知道 python 有 ord 函数,用来计算字符的 ascii 值,但是 C 语言没有,所以只有一种可能,代码中定义了 ord 函数,果然如此:
int __cdecl ord(unsigned __int8 a1)
{
if ( (char)a1 > 47 && (char)a1 <= 57 )
return a1 - 48;
if ( (char)a1 <= 64 || (char)a1 > 90 )
{
puts("Found Invalid Character!");
exit(0);
}
return a1 - 55;
}
对于字符,ord 的结果为 10 + 26,也就是36以内,对应 0x24,这下子就很简单了,上代码:
#coding=utf-8
def myord(data):
if data.isdigit():
return ord(data) - 48
elif data.isupper():
return ord(data) - 55
else:
return -1
for c in range(65, 91):
input = chr(c)*15
v2 = 0
## 假定前14个数字都为1
for i in range(0,15):
v2 += (myord(input[i]) + 1) * (i + 1)
#print v2
## 看看第15和16位应该是什么才能符合数字和大写字母
## range(48, 57) 都不行
v15 = v2 % 0x24
#print myord(v15)
if v15 > 9:
v15 += 55
else:
v15 += 48
print input + chr(v15)
可以构造出一堆的有效 key:
AAAAAAAAAAAAAAAO
BBBBBBBBBBBBBBB0
CCCCCCCCCCCCCCCC
DDDDDDDDDDDDDDDO
EEEEEEEEEEEEEEE0
FFFFFFFFFFFFFFFC
GGGGGGGGGGGGGGGO
HHHHHHHHHHHHHHH0
本地验证下:
giantbranch@ubuntu:~/rev/picoctf/keygen1$ ./activate AAAAAAAAAAAAAAAO
Product Activated Successfully: Flag File is Missing.
ssh 登录到服务器,获取 flag:
tiancai@pico-2018-shell:~$ cd /problems/keygen-me-1_0_2b06ee615c1b7021f1eff5829aae5006
tiancai@pico-2018-shell:/problems/keygen-me-1_0_2b06ee615c1b7021f1eff5829aae5006$ ls
activate flag.txt
tiancai@pico-2018-shell:/problems/keygen-me-1_0_2b06ee615c1b7021f1eff5829aae5006$ ./activate HHHHHHHHHHHHHHH0
Product Activated Successfully: picoCTF{k3yg3n5_4r3_s0_s1mp13_2243075891}
keygen-me-2
和 keygen-me-1 主体逻辑一样,重点看 validate_key 函数
_BOOL4 __cdecl validate_key(char *s)
{
strlen(s);
return key_constraint_01(s)
&& key_constraint_02((int)s)
&& key_constraint_03(s)
&& key_constraint_04(s)
&& key_constraint_05((unsigned __int8 *)s)
&& key_constraint_06((unsigned __int8 *)s)
&& key_constraint_07((unsigned __int8 *)s)
&& key_constraint_08((unsigned __int8 *)s)
&& key_constraint_09((unsigned __int8 *)s)
&& key_constraint_10((unsigned __int8 *)s)
&& key_constraint_11((unsigned __int8 *)s)
&& key_constraint_12((unsigned __int8 *)s);
}12 个判断函数,挑选几个打开看:
bool __cdecl key_constraint_01(char *a1)
{
int v1; // ebx
char v2; // al
v1 = (char)ord(*a1);
v2 = ord(a1[1]);
return mod(v1 + v2, 36) == 14;
}
bool __cdecl key_constraint_02(int a1)
{
int v1; // ebx
char v2; // al
v1 = (char)ord(*(_BYTE *)(a1 + 2));
v2 = ord(*(_BYTE *)(a1 + 3));
return mod(v1 + v2, 36) == 24;
}
bool __cdecl key_constraint_03(char *a1)
{
int v1; // ebx
char v2; // al
v1 = (char)ord(a1[2]);
v2 = ord(*a1);
return mod(v1 - v2, 36) == 6;
}运算逻辑也很简单,要解一个16元方程,正好可以拿来练习z3的用法:
#coding=utf-8
from z3 import *
def xmod(a, b):
'''
if a % b > 0: # Z3Exception("Symbolic expressions cannot be cast to concrete Boolean values.")
return a % b
else:
return a % b + b
'''
return a % b
# 根据index获取对应的字符
def xchr(index):
alphabet = []
for i in range(48,58):
alphabet.append(chr(i))
for i in range(65, 91):
alphabet.append(chr(i))
return alphabet[index]
input = []
solver = Solver()
input = [Int("input[%d]" % i) for i in range(16)] # 定义一个Int数组
solver.add(xmod(input[0] + input[1], 36) == 14) # con 1
solver.add(xmod(input[2] + input[3], 36) == 24) # con 2
solver.add(xmod(input[2] - input[0], 36) == 6) # con 3
solver.add(xmod(input[1] + input[3] + input[5], 36) == 4) # con 4
solver.add(xmod(input[2] + input[4] + input[6], 36) == 13) # con 5
solver.add(xmod(input[3] + input[4] + input[5], 36) == 22) # con 6
solver.add(xmod(input[6] + input[8] + input[10], 36) == 31) # con 7
solver.add(xmod(input[1] + input[4] + input[7], 36) == 7) # con 8
solver.add(xmod(input[9] + input[12] + input[15], 36) == 20) # con 9
solver.add(xmod(input[13] + input[14] + input[15], 36) == 12) # con 10
solver.add(xmod(input[8] + input[9] + input[10], 36) == 27) # con 11
solver.add(xmod(input[7] + input[12] + input[13], 36) == 23) # con 12
for i in range(16): # 为了缩小范围,将值限定在 0 到 35之间
solver.add(input[i] >= 0, input[i] <= 35)
if solver.check() == sat:
m = solver.model()
#print m.decls()
for d in m.decls():
print("%s = %s" % (d.name(), m[d]))
flag = []
for i in range(16):
index = m[input[i]]
index = int(index.as_string())
flag.append(xchr(index))
print ''.join(flag)
else:
print 'fail'
不到一分钟,就能解出结果:
input[13] = 28
input[3] = 19
input[14] = 7
input[4] = 33
input[2] = 5
input[11] = 0
input[6] = 11
input[1] = 15
input[0] = 35
input[15] = 13
input[8] = 0
input[7] = 31
input[5] = 6
input[10] = 20
input[9] = 7
input[12] = 0
ZF5JX6BV07K00S7D
验证一下:
giantbranch@ubuntu:~/rev/picoctf/keygen2$ ./activate ZF5JX6BV07K00S7D
Product Activated Successfully: Flag File is Missing.
同样的,ssh到服务器获取flag:
tiancai@pico-2018-shell:~$ cd /problems/keygen-me-2_2_5374d282dd09441ebd3055cb968eefff
tiancai@pico-2018-shell:/problems/keygen-me-2_2_5374d282dd09441ebd3055cb968eefff$ ./activate ZF5JX6BV07K00S7D
Product Activated Successfully: picoCTF{c0n5tr41nt_50lv1nG_15_W4y_f45t3r_2923966318}
使用z3过程中遇到一个问题,xmod 中不能使用if,如何解决呢?
原来z3 自带了 If 的三元函数:

修改 xmod 即可:
def xmod(a, b):
'''
if a % b >= 0: # Z3Exception("Symbolic expressions cannot be cast to concrete Boolean values.")
return a % b
else:
return a % b + b
'''
return If(a % b >= 0, a % b, a % b + b)
circut123
一个python文件和两个map.txt文件。
先按照题目示例运行一下:
giantbranch@ubuntu:~/rev/picoctf/circuit123$ python ./decrypt.py
Usage: ./decrypt.py <key> <map.txt>
Example: Try Running ./decrypt.py 11443513758266689915 map1.txt
giantbranch@ubuntu:~/rev/picoctf/circuit123$ ./decrypt.py 11443513758266689915 map1.txt
Attempting to decrypt map1.txt...
Congrats the flag for map1.txt is: not_a_flag{Real_flag_will_be_loooooooonger_than_me}
giantbranch@ubuntu:~/rev/picoctf/circuit123$
再来分析decrypt函数代码:
#!/usr/bin/python2
from hashlib import sha512
import sys
if __name__ == '__main__':
if len(sys.argv) < 3:
print 'Usage: ' + sys.argv[0] + ' <key> <map.txt>'
print 'Example: Try Running ' + sys.argv[0] + ' 11443513758266689915 map1.txt'
exit(1)
with open(sys.argv[2], 'r') as f:
cipher, chalbox = eval(f.read())
key = int(sys.argv[1]) % (1 << chalbox[0])
print 'Attempting to decrypt ' + sys.argv[2] + '...'
if verify(key, chalbox):
print 'Congrats the flag for ' + sys.argv[2] + ' is:', dec(key, cipher)
else:
print 'Wrong key for ' + sys.argv[2] + '.'
分析过程如下,首先是main函数
- main 函数中,从文件读取到了 cipher 和 chalbox
- 查看 map1.txt 可以看出, cipher 是一段密文,chalbox是一段很长的 list,暂时不知道作用
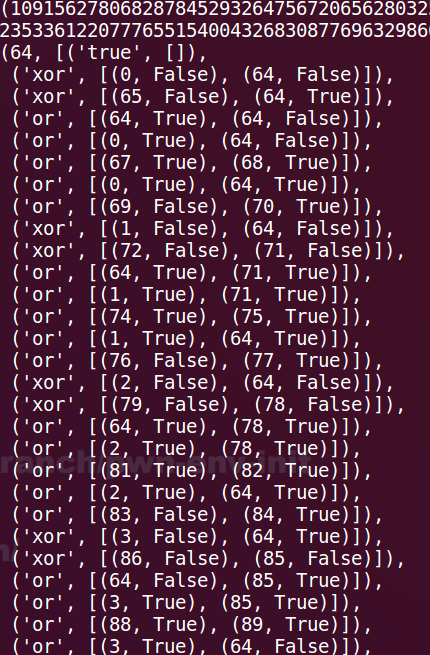
- key = int(sys.argv[1]) % (1 << chalbox[0]) # 确保 key 小于 2^64 次方,也就是长度不超过64位
接下来分析 verify 函数
def verify(x, chalbox):
length, gates, check = chalbox
b = [(x >> i) & 1 for i in range(length)]
for name, args in gates:
if name == 'true':
b.append(1)
else:
u1 = b[args[0][0]] ^ args[0][1]
u2 = b[args[1][0]] ^ args[1][1]
if name == 'or':
b.append(u1 | u2)
elif name == 'xor':
b.append(u1 ^ u2)
return b[check[0]] ^ check[1]
主要做了以下工作:
- x: 代表key,也就是我们要求的值
- length, gates, check = chalbox # 分别代表长度,gates还不知道是啥,check 猜测是校验位
- return b[check[0]] ^ check[1] # 可以确认,chalbox最后一个tuple的两个元素用来做校验
- b = [(x >> i) & 1 for i in range(length)] 初始化一个64个元素的数组,将key 展开为64bit,从高往低逐位与1进行&运算,然后存储到数组b中。也就是二进制展开,从高往低映射到数组b中
- 接下来是一个大循环
- for name, args in gates: # 'xor', [(0, False), (64, False)]
- name 有三种 true/or/xor
- args[x][y] 分别代表了四个元素
- 根据 name 的值,进行计算,计算结果放到 b 数组中
- 查看check tuple:(570, True) ,表明最后b的长度至少为570+1,且b[570] ^ True 结果要为 True
- 查看下gates中 tuple的个数,一共 507 个, 加上 64 个根据 k 初始化的元素,正好571
- 所以解密逻辑是:
- 将key按照64位二进制展开,逐位映射到数组b中,获得b[0] - b[63]
- 根据每一个 gates 中的tuple计算一个b元素,获得 b[64]-b[570]
- 最后,b[570] ^ True 结果为true
b[0] - b[63] 未知,后面的 570 次运算相当于解64元方程的算式,所以这只是个变种的z3题型。
根据以上分析写出计算key的代码:
#!/usr/bin/python2
#coding=utf-8
from hashlib import sha512
import sys
from z3 import *
def deverify(chalbox):
length, gates, check = chalbox
solver = Solver()
b = [Bool("b[%d]" % i) for i in range(check[0] + 1)]
i = length
for name, args in gates:
if name == 'true':
solver.add(b[i] == True)
else:
u1 = Xor(b[args[0][0]], args[0][1])
u2 = Xor(b[args[1][0]], args[1][1])
#print "[{0},{1}]".format(u1, u2)
if name == 'or':
solver.add(b[i] == Or(u1, u2))
elif name == 'xor':
solver.add(b[i] == Xor(u1, u2))
i += 1
solver.add(Xor(b[check[0]], check[1]) == True)
#print solver
if solver.check() == sat:
m = solver.model()
for d in m.decls():
print("%s = %s" % (d.name(), m[d]))
flag = ''
for i in range(length):
index = m[b[i]]
#index = str(index.as_string())
print "k=>v,{0}=>{1}".format(i, index)
if m[b[i]] == True:
flag += '1'
else:
flag += '0'
print int(flag[::-1],2)
else:
print 'fail'
if __name__ == '__main__':
if len(sys.argv) < 2:
print 'Usage: ' + sys.argv[0] + ' <map.txt>'
print 'Example: Try Running ' + sys.argv[0] + ' map1.txt'
exit(1)
with open(sys.argv[1], 'r') as f:
cipher, chalbox = eval(f.read())
#key = int(sys.argv[1]) % (1 << chalbox[0])
print 'Attempting to decrypt ' + sys.argv[1] + '...'
deverify(chalbox)
说明如下:
- 读取数据的过程,直接服用题目代码,但是key未知,所以argv要少一个
- 自己编写 deverfiy 函数进行解密
- b = [Bool("b[%d]" % i) for i in range(check[0] + 1)] # 先初始化一个 Bool 数组,作为64个变量
u1 = Xor(b[args[0][0]], args[0][1])由于在z3的solver中无法直接使用^预算,所以改用Xor(a,b)的形式。(这条参见了文档 z3py.pdf,位置:file:///E:/Downloads/Documents/z3py.pdf)
- 在循环中添加算式 solver.add(b[i] == Or(u1, u2)) 和 solver.add(b[i] == Xor(u1, u2))
- 因为是Bool型,计算速度飞快。先拿map1 进行验证,可以很快得到key
- 计算map2就只需要更换参数了,很快拿到128bit的key
k=>v,122=>True
k=>v,123=>False
k=>v,124=>False
k=>v,125=>True
k=>v,126=>False
k=>v,127=>True
219465169949186335766963147192904921805 - 获得flag:
giantbranch@ubuntu:~/rev/picoctf/circuit123$ python decrypt.py 219465169949186335766963147192904921805 map2.txt
Attempting to decrypt map2.txt...
Congrats the flag for map2.txt is: picoCTF{36cc0cc10d273941c34694abdb21580d__aw350m3_ari7hm37ic__}
giantbranch@ubuntu:~/rev/picoctf/circuit123$
special-pw
安装32bit的编译环境:
sudo apt-get install build-essential module-assistant
sudo apt-get install gcc-multilib g++-multilib
对下载的文件进行编译:
gcc demo.s -m32 -o demo运行程序会爆出段错误,因为地址内容不存在:
giantbranch@ubuntu:~/rev/picoctf/special-pw$ ./demo
Segmentation fault (core dumped)
丢到 IDA 里面,F5查看伪代码:
int __cdecl main(int argc, const char **argv, const char **envp)
{
char *v3; // ST0C_4
_BYTE *k; // [esp+0h] [ebp-10h]
int v6; // [esp+4h] [ebp-Ch]
int j; // [esp+8h] [ebp-8h]
const char *i; // [esp+Ch] [ebp-4h]
const char *v9; // [esp+Ch] [ebp-4h]
v6 = 0;
for ( i = argv[1]; *i; ++i )
++v6;
for ( j = 0; v6 - 3 > j; ++j )
{
v3 = (char *)&argv[1][j];
*v3 ^= 0x9Du;
*(_WORD *)v3 = __ROR2__(*(_WORD *)v3, 5);
*(_DWORD *)v3 = __ROL4__(*(_DWORD *)v3, 11);
}
v9 = argv[1];
for ( k = (_BYTE *)0x14890BA; *k; ++k )
{
if ( *v9 != *k )
return 0;
++v9;
}
return argv[1][(_DWORD)(k - 21532858)] == 0;
}
程序逻辑非常简单:
- 先利用循环计算字符串长度 v6
- 第二个循环,循环次数 v6 - 3
- 依次获取用户输入的指针放入 v3,每循环一次,向后指一个字符
- v3第一个字节的值 ^ 0x9D
- 取出 v3 前两个字节,循环右移5位
- 取出 v3 前4个字节,循环左移11位
直接写代码,感觉快做出来了:
#coding=utf-8
from ctypes import *
# 字符的循环移位
def rol(v, k, bit = 8):
'''
8bit char 的按位循环左移
:param v: 要进行移位的整数
:param k: 要移动几位?
:param bit: 位数,默认为8,对应8为整数。
:return:
'''
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[:k] + bin_value[k:]
ret = int(bin_value, 2)
return ret
def ror(v, k, bit = 8):
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[-k:] + bin_value[:-k]
ret = int(bin_value, 2)
return ret
cipher = '7b 18 a6 36 da 3b 2b a6 fe cb 82 ae 96 ff 9f 46 8f 36 a7 af fe 93 8e 3f 46 a7 ff 82 cf ce b3 97 17 1a a7 36 ef 2b 8a ed'.split(' ')
for i in reversed(range(len(cipher)-3)):
a = cipher[i:i+4]
a = a[::-1]
tmp = ''.join(a)
print tmp
c = ror(c_uint32(int('0x' + tmp, 16)).value, 11, 32)
#c = ror(int('0x' + tmp, 16), 11, 32)
c1 = str(hex(c))[2:10]
c = rol(c_uint16(c).value, 5, 16)
#c = rol(c, 5, 16)
c2 = str(hex(c))[2:6]
c = c_uint8(c).value ^ 0x9D
#c = c ^ 0x9D
c3 = str(hex(c))[2:4]
print "[{3}] c1:{0}, c2:{1}, c3:{2}".format(c1, c2, c3, i)
cipher[i:i+4] = [c1[j:j+2] for j in xrange(0, len(c1), 2)][::-1]
cipher[i:i+2] = [c2[j:j+2] for j in xrange(0, len(c2), 2)][::-1]
cipher[i] = c3
print cipher[i:i+4]
ret = ''
for c in cipher:
ret += chr(int('0x' + c, 16))
print ret
# RdcO��F[geT•YpuR�ShQft�•R�gh�•pYy��#�m}
# 看起来第6位正确,结尾的 } 也正确,是中间某个位置计算错误
仔细检查了下,发现 rol 写错了,赶紧改过来:
bin_value = bin_value[:k] + bin_value[k:]
====>
bin_value = bin_value[k:] + bin_value[:k]
# picoCTF;gEt••p�•_s�qF•U•rqG�••0YY�•b4f}
flag 还是不对,但是前7个字符 picoCTF 正确,看来离答案很近了,不禁陷入了沉思……
没办法,把别人 wp 的代码直接拿来跑了一遍,输出中间数据,终于发现了问题:
[34] c1:34fbf405, c2:80be, c3:23
['23', '80', 'fb', '34', '66', '7d']
[33] c1:635f7004, c2:8e, c3:13
['13', '5f', '63', '34', '66', '7d']
可以看到,i = 33和34时,cipher的长度一致!
原因在 C2 = 8e,实际上是 008e,但是 str(hex(c2))[2:6] 将 00 丢弃了。 ([2:6] 中6超过了list长度,但不会报错)
所以,要对所有的数值高位补零。这就要用到 zfill(n) 函数:
c1 = str(hex(c))[2:10].zfill(6)
c2 = str(hex(c))[2:6].zfill(4)
c3 = str(hex(c))[2:4].zfill(2)
最终代码如下:
#coding=utf-8
from ctypes import *
# 字符的循环移位
def rol(v, k, bit = 8):
'''
8bit char 的按位循环左移
:param v: 要进行移位的整数
:param k: 要移动几位?
:param bit: 位数,默认为8,对应 8 位整数。
:return:
'''
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[k:] + bin_value[:k]
ret = int(bin_value, 2)
return ret
def ror(v, k, bit = 8):
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[-k:] + bin_value[:-k]
ret = int(bin_value, 2)
return ret
'''
014890BA: 7b 18 a6 36 da 3b 2b a6 fe cb 82 ae 96 ff 9f 46 |{..6.;+........F|
014890CA: 8f 36 a7 af fe 93 8e 3f 46 a7 ff 82 cf ce b3 97 |.6.....?F.......|
014890DA: 17 1a a7 36 ef 2b 8a ed 00 |...6.+...|
'''
cipher = '7b 18 a6 36 da 3b 2b a6 fe cb 82 ae 96 ff 9f 46 8f 36 a7 af fe 93 8e 3f 46 a7 ff 82 cf ce b3 97 17 1a a7 36 ef 2b 8a ed'.split(' ')
for i in reversed(range(len(cipher)-3)):
a = cipher[i:i + 4]
a = a[::-1]
tmp = ''.join(a)
#print tmp
c = ror(c_uint32(int('0x' + tmp, 16)).value, 11, 32)
c1 = str(hex(c))[2:10].zfill(6)
c = rol(c_uint16(c).value, 5, 16)
c2 = (str(hex(c))[2:6]).zfill(4)
c = (c_uint8(c).value ^ 0x9D)
c3 = str(hex(c))[2:4].zfill(2)
print "[{3}] c1:{0}, c2:{1}, c3:{2}".format(c1, c2, c3, i)
cipher[i:i + 4] = [c1[j:j + 2] for j in xrange(0, len(c1), 2)][::-1]
cipher[i:i + 2] = [c2[j:j + 2] for j in xrange(0, len(c2), 2)][::-1]
cipher[i] = c3
print cipher[i:]
ret = ''
for c in cipher:
ret += chr(int('0x' + c, 16))
print ret
# 输出:picoCTF{gEt_y0Ur_sH1fT5_r1gHt_09962bc4f}
这段代码有几点要加强学习的:
- rol/ror 函数的原理,用到了简单的切片拼接: [k:] + [:k] 和 [-k:] + [:-k],以及 '{:032b}'.format(32) 这种字符串转换形式
print '{0:032}'.format(10)
00000000000000000000000000000010
print '{0:032b}'.format(10)
00000000000000000000000000001010
print '{0:032x}'.format(16)
00000000000000000000000000000010 - 小端存储时,如何对 a = ['de','ad','be','ef'] 进行反转:
a = a[::-1]
b = '0x' + ''.join(a) - 利用 zfill 对字符串的高位补0
- 如何对字符串按照定长分割为list,比如 c1 要转换为 4 个hex字符,而且逆序,用到了列表推导式以及反转:
cipher[i:i+4] = [c1[j:j+2] for j in xrange(0, len(c1), 2)][::-1] - c_uintN 真好用,能够直接按照字节取数
from struct import unpack, pack
# https://gist.github.com/c633/a7a5cde5ce1b679d3c0a
rol = lambda val, r_bits, max_bits:
(val << r_bits%max_bits) & (2**max_bits-1) |
((val & (2**max_bits-1)) >> (max_bits-(r_bits%max_bits)))
ror = lambda val, r_bits, max_bits:
((val & (2**max_bits-1)) >> r_bits%max_bits) |
(val << (max_bits-(r_bits%max_bits)) & (2**max_bits-1))
data = 'b1d3324cfce6ef5eede466cd57f5e17fcd7f55f6e964e7c97f75e954e64df779fcfc5171f93e18d900'.decode('hex')
data = data[:-1]
for i in range(len(data)-3-1, -1, -1):
v, = unpack('<I', data[i:i+4])
data = data[:i] + pack('<I', ror(v, 15, 4*8)) + data[i+4:]
v, = unpack('<H', data[i:i+2])
data = data[:i] + pack('<H', rol(v, 13, 2*8)) + data[i+2:]
v, = unpack('<B', data[i:i+1])
data = data[:i] + pack('<B', v ^ 0xde) + data[i+1:]
print data # picoCTF{gEt_y0Ur_sH1fT5_r1gHt_0cb381c60}
简要分析如下:
- rol 和 ror 采用lambda表达式。采用最直观的逻辑,比如rol,将字符串拆分位两端进行拼接:
- 先左移 r_bits 位,低位置0
- 再右移 (max_bits - r_bits)位,将高位置0
- 最后利用 | 运算,进行拼接
- 其实不如我的代码直观,所以不借鉴了
- 利用 data[:-1]丢掉尾部的 00
- 导入了 struct 库的 unpack和pack函数,这个需要重点学习,因为省去了 c_uintN/zfill/反转 操作
- 参考文章:https://www.cnblogs.com/gala/archive/2011/09/22/2184801.html
- data = 'xxxx'.decode('hex')直接将data转换为字节流
- unpack(fmt, string) 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple
- unpack的fmt有三个: <I <H <B ,其中 < 表示小端存储,I => unsigned int/ H=>unsigned short/B=>unsigned char
- unpack的返回值为tuple,所以为了获得数据,需要用 v, = unpack(xxx)的形式
- pack(fmt, v1, v2, ...) 按照给定的格式(fmt),把数据封装成字符串(实际上是类似于c结构体的字节流)
- pack('<I', ror(xxxx)),表示将 ror 的结果按照小端存储为 unsigned int
使用struct 重写自己的代码如下:
#coding=utf-8
from struct import pack, unpack
# 字符的循环移位
def rol(v, k, bit = 8):
'''
8bit char 的按位循环左移
:param v: 要进行移位的整数
:param k: 要移动几位?
:param bit: 位数,默认为8,对应 8 位整数。
:return:
'''
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[k:] + bin_value[:k]
ret = int(bin_value, 2)
return ret
def ror(v, k, bit = 8):
bit_string = '{:0%db}' % bit
bin_value = bit_string.format(v)
bin_value = bin_value[-k:] + bin_value[:-k]
ret = int(bin_value, 2)
return ret
'''
014890BA: 7b 18 a6 36 da 3b 2b a6 fe cb 82 ae 96 ff 9f 46 |{..6.;+........F|
014890CA: 8f 36 a7 af fe 93 8e 3f 46 a7 ff 82 cf ce b3 97 |.6.....?F.......|
014890DA: 17 1a a7 36 ef 2b 8a ed 00 |...6.+...|
'''
cipher = '7b 18 a6 36 da 3b 2b a6 fe cb 82 ae 96 ff 9f 46 8f 36 a7 af fe 93 8e 3f 46 a7 ff 82 cf ce b3 97 17 1a a7 36 ef 2b 8a ed'.replace(' ', '').decode('hex') # cipher 为 str 类型
for i in reversed(range(len(cipher)-3)):
v1, = unpack('<I', cipher[i:i+4]) # 按照小端存储获得4byte内容
#cipher[i:i+4] = pack('<I', ror(v, 11, 32)) # 'str' object does not support item assignment
cipher = cipher[:i] + pack('<I', ror(v1, 11, 32)) + cipher[i+4:]
v2, = unpack('<H', cipher[i:i+2])
cipher = cipher[:i] + pack('<H', rol(v2, 5, 16)) + cipher[i+2:]
v3, = unpack('<B', cipher[i])
cipher = cipher[:i] + pack('<B', v3 ^ 0x9D) + cipher[i+1:]
print cipherstruct 的类型列表:
| Format | C Type | Python | 字节数 |
|---|---|---|---|
x | pad byte | no value | 1 |
c | char | string of length 1 | 1 |
b | signed char | integer | 1 |
B | unsigned char | integer | 1 |
? | _Bool | bool | 1 |
h | short | integer | 2 |
H | unsigned short | integer | 2 |
i | int | integer | 4 |
I | unsigned int | integer or long | 4 |
l | long | integer | 4 |
L | unsigned long | long | 4 |
q | long long | long | 8 |
Q | unsigned long long | long | 8 |
f | float | float | 4 |
d | double | float | 8 |
s | char[] | string | 1 |
p | char[] | string | 1 |
P | void * | long |
注1.q和Q只在机器支持64位操作时有意思
注2.每个格式前可以有一个数字,表示个数
注3.s格式表示一定长度的字符串,4s表示长度为4的字符串,但是p表示的是pascal字符串
注4.P用来转换一个指针,其长度和机器字长相关
注5.最后一个可以用来表示指针类型的,占4个字节
为了同c中的结构体交换数据,还要考虑有的c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下:
| Character | Byte order | Size and alignment |
|---|---|---|
@ | native | native 凑够4个字节 |
= | native | standard 按原字节数 |
< | little-endian | standard 按原字节数 |
> | big-endian | standard 按原字节数 |
! | network (= big-endian) |