大数据实战项目--中国移动运行分析
1、项目背景
中国移动公司旗下拥有很多的子机构,基本可以按照省份划分. 而各省份旗下的充值机构也非常的多.
目前要想获取整个平台的充值情况,需要先以省为单元,进行省份旗下的机构统计,然后由下往上一层一层的统计汇总,过程太过繁琐,且统计周期太长,且充值过程中会涉及到中国移动信息系统内部各个子系统之间的接口调用,接口故障监控也成为了重点监控的内容之一,为此建设一个能够实时监控全国的充值情况的平台,掌控全网的实时充值,各接口调用情况意义重大。
2、技术选型
2.1、难点分析
1、移动公司旗下子充值机构众多, 充值数据量大.
2、数据实时性要求高
2.2、可用技术选型
2.2.1、实时流式计算框架 Storm
2.2.2、实时流式计算框架 Spark Streaming
2.2.3、实时流式计算框架 Flink
2.3、对比分析
Storm、Spark streaming、Flink 都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的 API 来简化底层实现的复杂程度。
2.3.1、Apache Storm
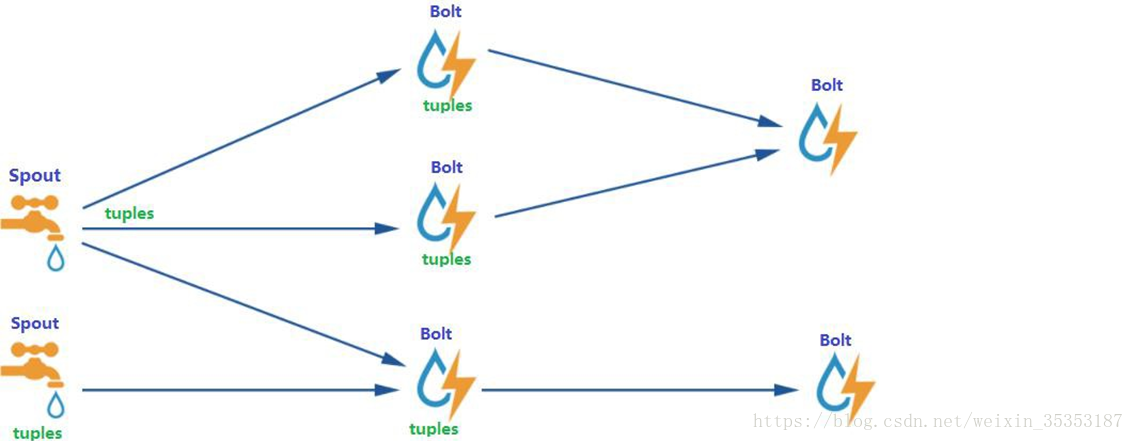
在 Storm 中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括 spout 和 bolt 两种角色,其中 spout 发送消息,
负责将数据流以 tuple 元组的形式发送出去;而 bolt 则负责转换这些数据流,在 bolt 中可以完成计算、过滤等操作,bolt 自身也可以随机将数据发送给其他 bolt。由 spout 发射出的 tuple是不可变数组,对应着固定的键值对。
2.3.2、Apache Spark
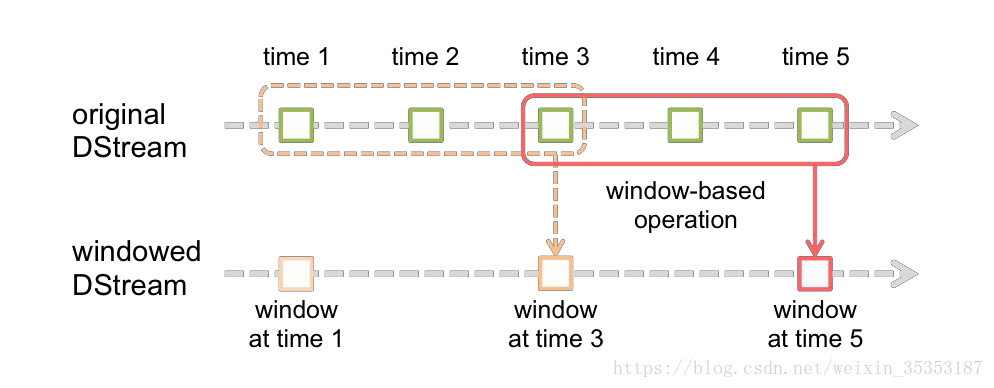
Spark Streaming 是核心 Spark API 的一个扩展,它并不会像 Storm 那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark 针对持续性数据流的抽象称为 DStream(DiscretizedStream),一个 DStream 是一个微批处理(micro-batching)的 RDD(弹性分布式数据集);而 RDD 则是一种分布式数据集,能够以两种方式并行运作, 分别是任意函数和滑动窗口数据的转换
2.3.3、Apache Flink
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与Storm。
3、项目架构
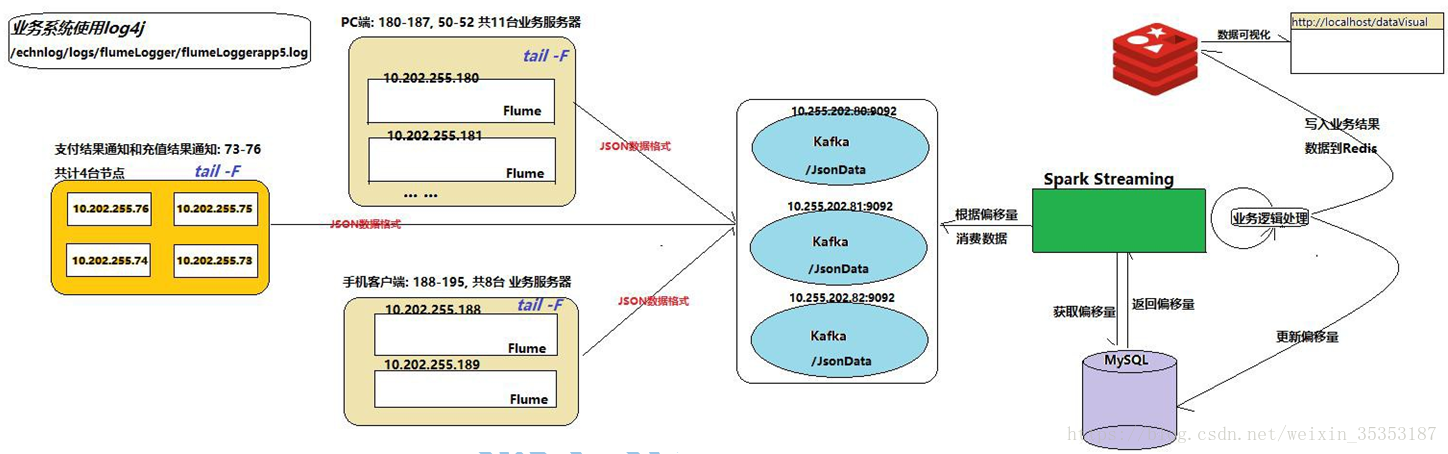
73 到 76 主机,每台主机上面部署了 6 个 server, 2 个负责支付结果通知,2 个负责发起充值请求,2 个负责充值结果通知.目前退费没有监控
4、集群规模--Flume
4.1、业务节点分为 PC 端和手机端:
PC 端一共有 11 台, flume 会监控每台节点生成的日志文件, 一共有 11 个 Flume 节点手机端一共有 8 台,flume 会监控每台节点生成的日志文件, 一共有 8 个 Flume 节点.
4.2、支付结果通知和充值结果通知:
该业务有 4 台节点, flume 会监控每台节点生成的日志文件, 一共有 4 个 Flume 节点. 机器配置?
5、项目数据量
数据量每天大概 2000 到 3000 万笔的下单量, 每条数据大概在 0.5KB 左右,下单量数据大概在 15GB 左右.
最后充值成功的大概 500 到 1000 万,平时充值成功的大概五六百万笔.
月初和月末量比较大
6、项目需求
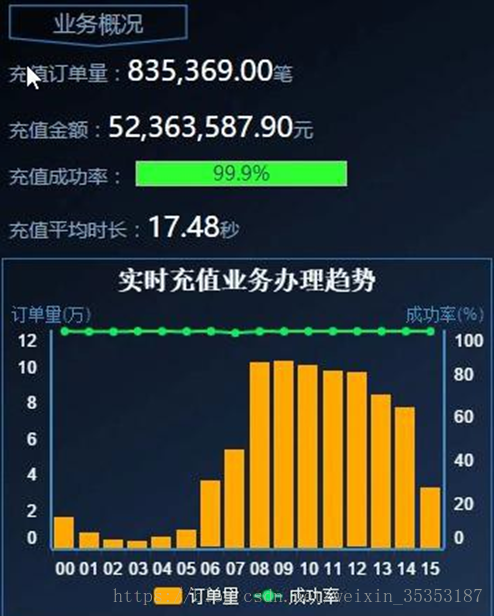
6.1、业务概况
统计全网的充值成功订单量, 充值金额, 充值成功率及充值平均时长.
实时充值业务办理趋势, 主要统计全网的订单量数据和成功率.
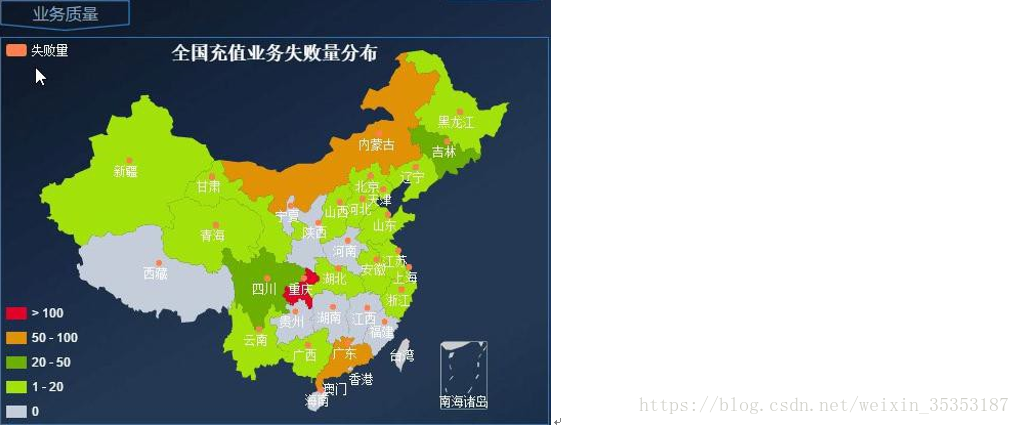
6.2、业务质量
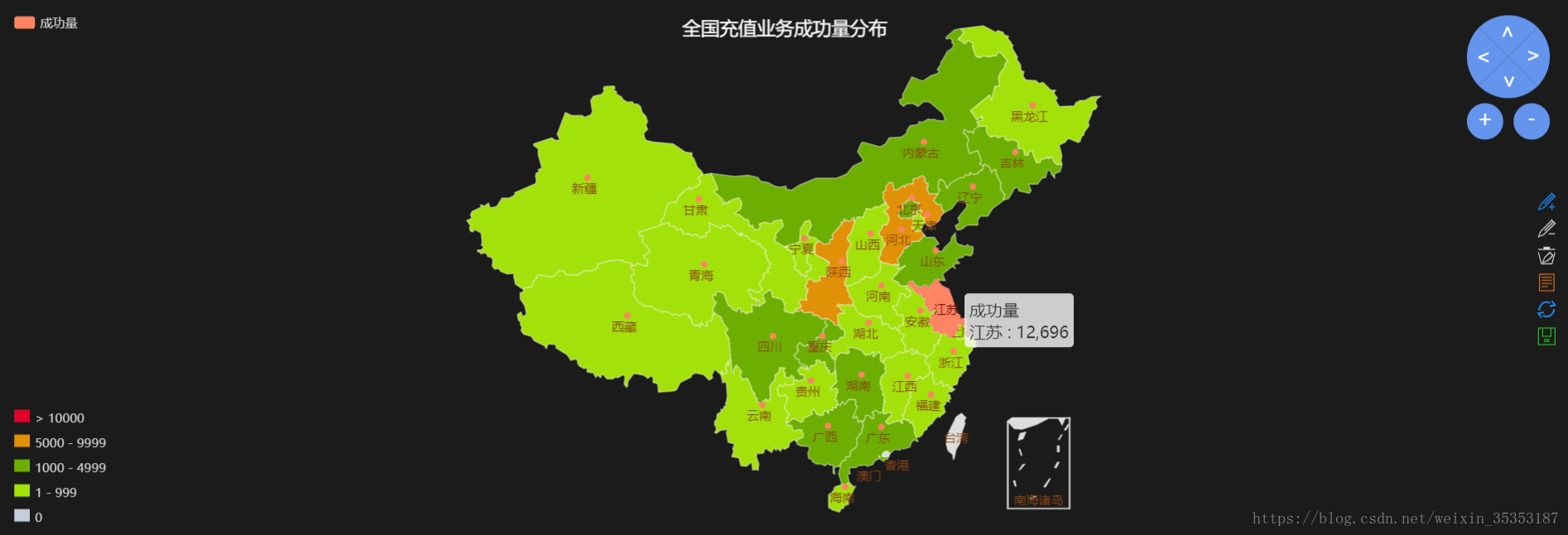
6.2.1、全国各省充值业务失败量分布
统计每个省份的充值失败数据量, 并以地图的方式显示分布情况.
6.3、业务体验
6.3.1、支付
6.3.1.1、最大时长---统计支付订单的最大时长.
6.3.2.2、最小时长---统计支付订单的最小时长.
6.3.2、充值
6.3.2.1、平均时长---统计充值订单的平均时长.
6.3.2.2、最大时长---统计充值订单的最大时长.
6.3.2.3、最小时长---统计充值订单的最小时长.
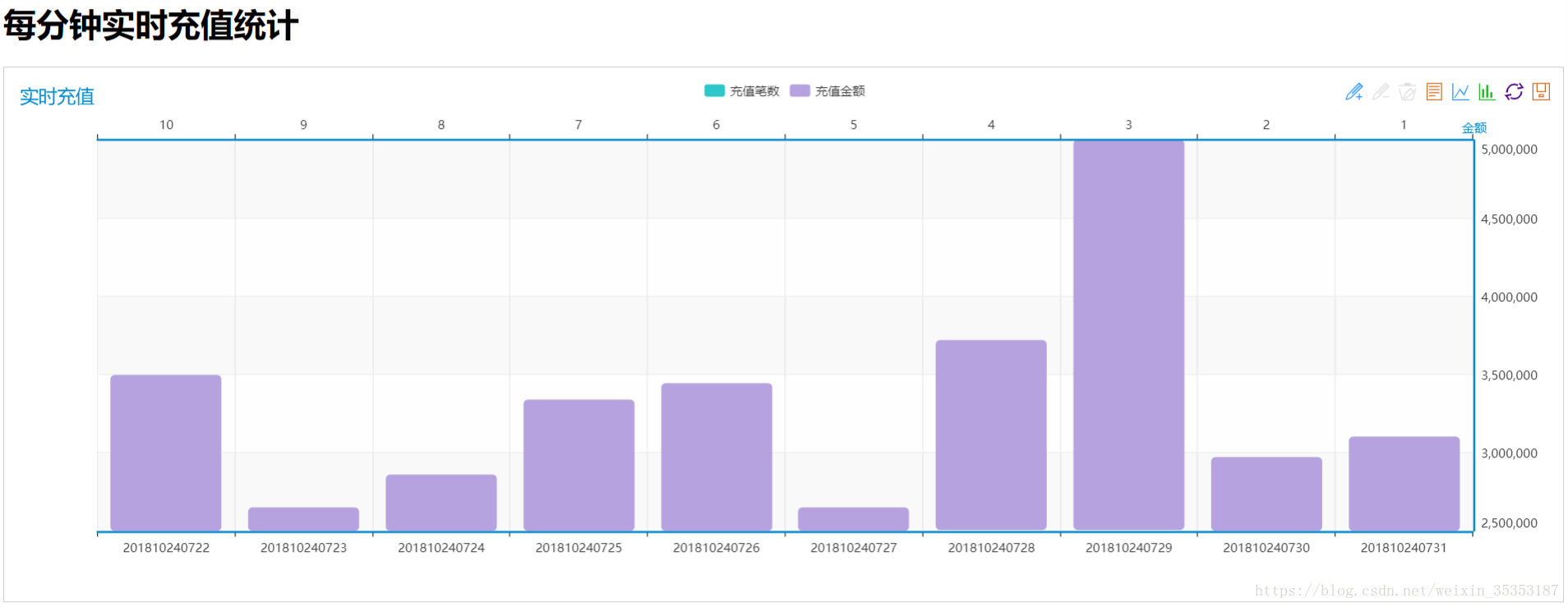
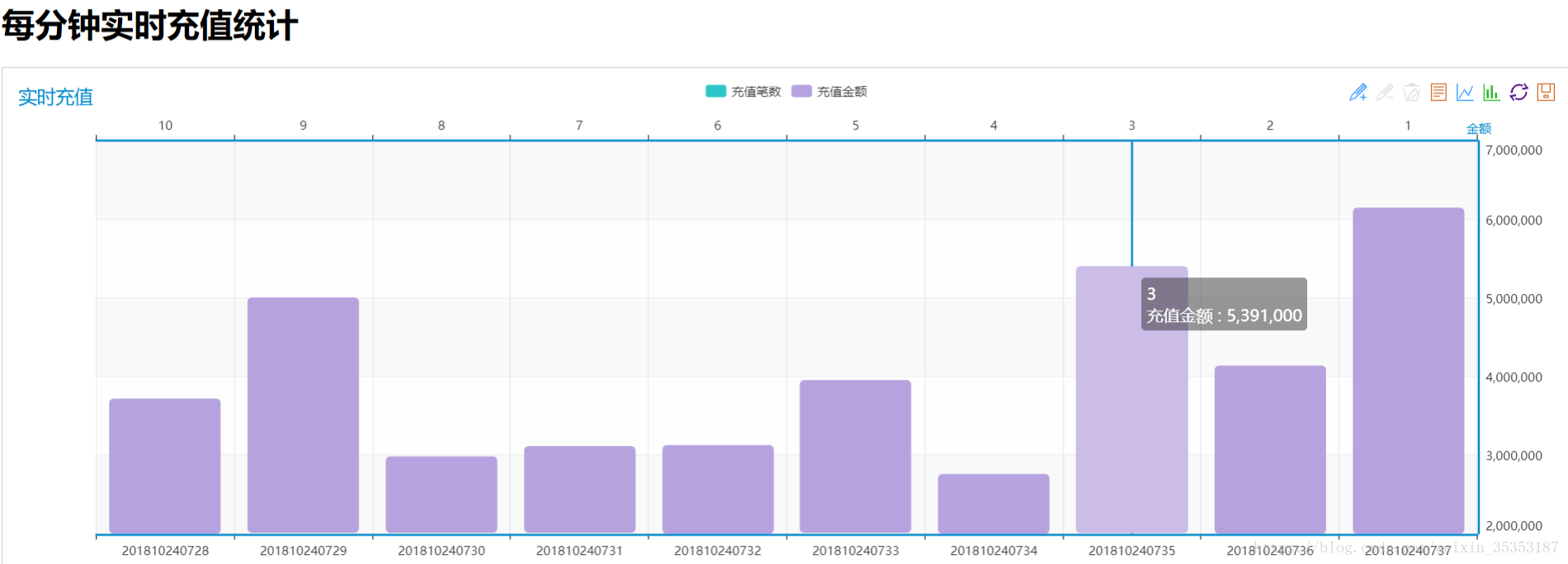
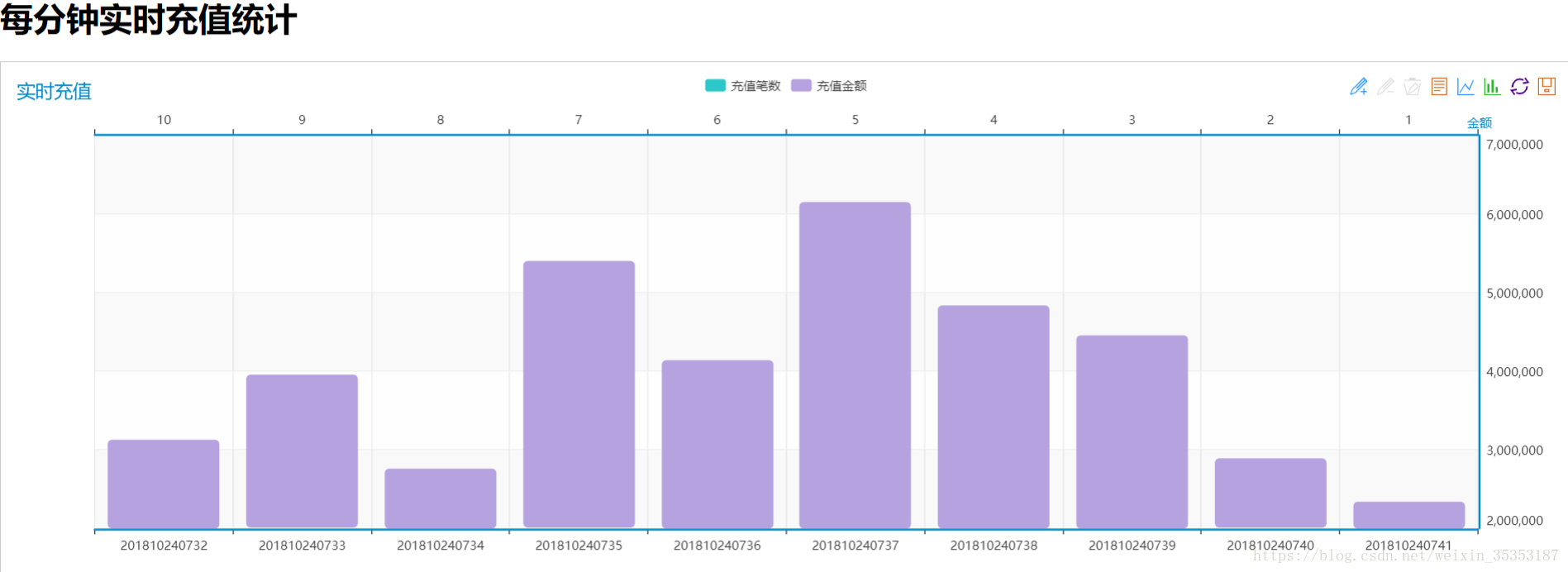
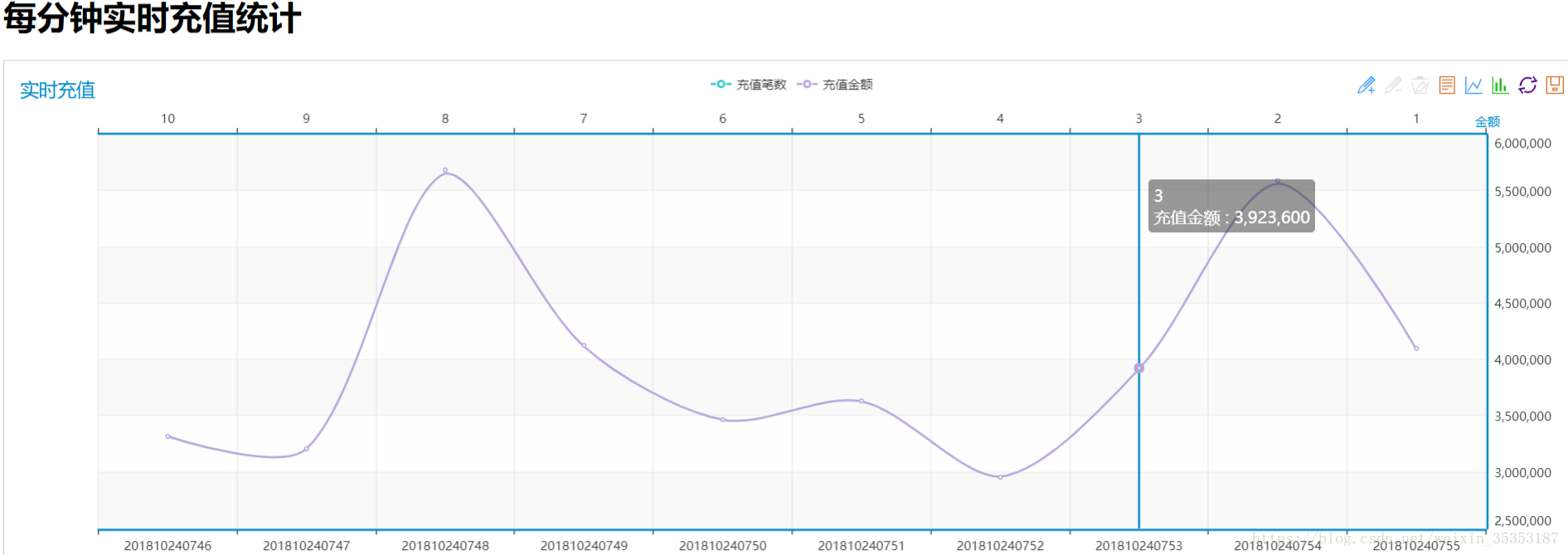
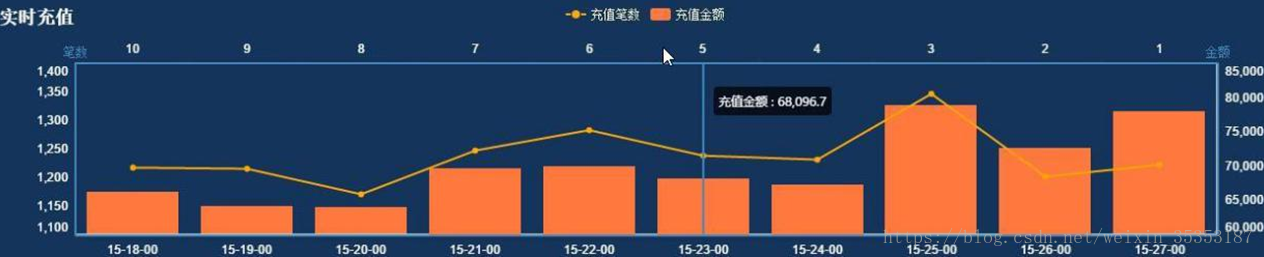
6.4、实时充值情况分布
实时统计每分钟的充值笔数和充值金额
7、数据说明:
充值的整个过程是包括:
订单创建->支付请求->支付通知->充值请求->充值通知
而我们需要处理的就是充值通知部分的数据。而我们的数据中是包含上面这五种类型的数据的。
那么我们如何从那么多数据中确定哪条数据是充值通知的数据呢?
我们可以通过serviceName字段来确定,如果该字段是reChargeNotifyReq则代表该条数据是充值通知部分的数据。
数据展示:

单条数据所有字段:
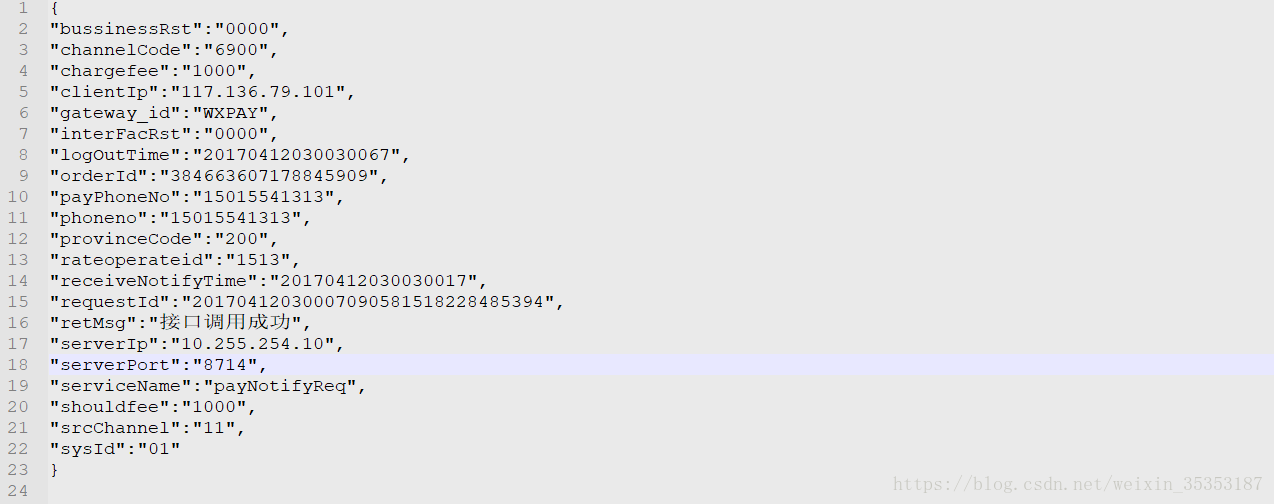
8、业务需求分析
充值订单量我们只需要通过有多少行数就可以确定有多少笔。
对于充值金额,我们首先需要确定到充值成功的订单数(字段bussinessRst如果为0000则代表成功)
找到充值成功的订单之后,我们可以将该数据的chargefee字段进行累加。就可以得到总金额。
充值成功率:我们只要知道总交易笔数和成功的笔数即可求。
充值平均时长:首先我们需要知道开始时间和结束时间,我们才能知道充值所花费的时间。
开始时间:对于开始时间,这里有一个RequestId字段,它是由时间戳+随机数生成的。
结束时间:即为接到充值通知的时间,为字段(receiveNotifyTime)
对于业务失败量的分布,首先我们需要知道在哪个省份,哪个地区。
我们可以根据provinceCode字段来确定省份
对于失败的订单我们可以通过统计bussinessRst为不是0000的情况来确定。
9、具体实现
9.1、Flume采集数据到Kafka
Flume的搭建以及原理参见文章:https://blog.csdn.net/weixin_35353187/article/details/83038297
Kafka的搭建以及原理参见文章:https://blog.csdn.net/weixin_35353187/article/details/82991626
首先创建Flume的配置文件,将采集到的数据下沉到Kafka
在myconf文件夹下新建file-kafka.conf文件,具体配置如下:
-
# 定义这个agent中各组件的名字
-
a1.sources = r1
-
a1.sinks = k1
-
a1.channels = c1
-
-
# 描述和配置source组件:r1
-
a1.sources.r1.type = spooldir
-
a1.sources.r1.spoolDir = /root/flumedata/
-
-
-
# 描述和配置sink组件:k1
-
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
-
a1.sinks.k1.kafka.topic = JsonData5
-
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092,hadoop04:9092
-
a1.sinks.k1.kafka.flumeBatchSize = 20
-
a1.sinks.k1.kafka.producer.acks = 1
-
a1.sinks.k1.kafka.producer.linger.ms = 1
-
a1.sinks.k1.kafka.producer.compression.type = snappy
-
-
-
# 描述和配置channel组件,此处使用是内存缓存的方式
-
a1.channels.c1.type = memory
-
a1.channels.c1.capacity = 1000
-
a1.channels.c1.transactionCapacity = 100
-
-
# 描述和配置source channel sink之间的连接关系
-
a1.sources.r1.channels = c1
-
a1.sinks.k1.channel = c1
启动Kafka,注:启动Kafka之前必须保证zookeeper是启动的。
kafka-server-start.sh -daemon /usr/local/kafka_2.11-0.10.2.1/config/server.properties
启动Flume去采集日志文件:
bin/flume-ng agent -c conf -f myconf/file-kafka.conf -n a1 -Dflume.root.logger=INFO,console
因为我们监控的是一个文件夹,所以将文件丢到所监控的文件夹/root/flumedata/下,这时Flume就会自动采集日志到Kafka,并且Topic的主题我们设置的是JsonData5
接下来我们在kafka中消费数据,查看是否写入成功
kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --from-beginning --topic JsonData5
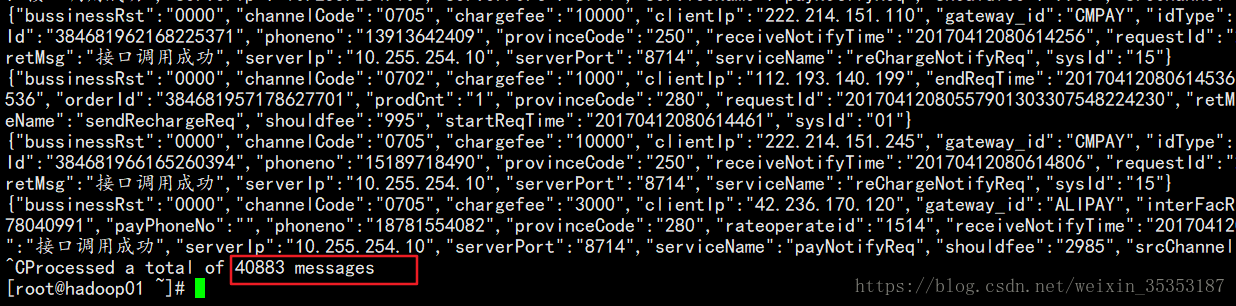
我们可以看到消费了40883条数据,说明我们全部写入成功。至此,我们已经完成了将数据写入到Kafka的工作。
9.2、从Kafka中拉取数据
为了方便代码的修改,以及代码分离,我们利用配置文件进行配置开发
application.conf放在resources下面:
kafka的相关配置如下:
-
# kafka相关参数
-
kafka.topic = "JsonData5"
-
kafka.broker.list = "hadoop01:9092,hadoop02:9092,hadoop03:9092,hadoop04:9092"
-
kafka.group.id = "day2_001"
AppParams:
-
package cn.sheep.cmcc.utils
-
-
import com.typesafe.config.{Config, ConfigFactory}
-
import org.apache.kafka.common.serialization.StringDeserializer
-
-
/**
-
* ZhangJunJie
-
* 2018/10/16 9:58
-
* Describe:
-
**/
-
-
object AppParams {
-
-
/**
-
* 解析application.conf配置文件
-
* 加载resource下面的配置文件,默认规则:application.conf->application.json->application.properties
-
*/
-
private lazy val config: Config = ConfigFactory.load()
-
-
/**
-
* 返回订阅的主题
-
*/
-
val topic = config.getString("kafka.topic").split(",")
-
-
/**
-
* kafka集群所在的主机和端口
-
*/
-
val borkers = config.getString("kafka.broker.list")
-
-
/**
-
* 消费者的ID
-
*/
-
val groupId = config.getString("kafka.group.id")
-
-
/**
-
* kafka的相关参数
-
*/
-
val kafkaParams = Map[String, Object](
-
"bootstrap.servers" -> borkers,
-
"key.deserializer" -> classOf[StringDeserializer],
-
"value.deserializer" -> classOf[StringDeserializer],
-
"group.id" -> groupId,
-
"auto.offset.reset" -> "earliest",
-
"enable.auto.commit" -> "false"
-
)
接下来读取Kafka中的数据:
-
package cn.sheep.cmcc.app
-
-
import java.text.SimpleDateFormat
-
-
import cn.sheep.cmcc.utils.{AppParams, Jpools}
-
import com.alibaba.fastjson.JSON
-
import org.apache.kafka.clients.consumer.ConsumerRecord
-
import org.apache.spark.SparkConf
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
-
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
import com.alibaba.fastjson.JSON
-
import com.alibaba.fastjson.JSONObject
-
import com.alibaba.fastjson.JSONArray
-
import com.alibaba.fastjson.JSONException
-
import redis.clients.jedis.JedisPool;
-
-
/**
-
* ZhangJunJie
-
* 2018/10/16 15:58
-
* Describe:
-
**/
-
-
object BootStarpApp {
-
-
def main(args: Array[String]): Unit = {
-
-
val sparkConf = new SparkConf()
-
sparkConf.setAppName("中国移动运营实时监控平台-Monitor")
-
//如果在集群上运行的话,需要去掉:sparkConf.setMaster("local[*]")
-
sparkConf.setMaster("local[*]")
-
//将rdd以序列化格式来保存以减少内存的占用
-
//默认采用org.apache.spark.serializer.JavaSerializer
-
//这是最基本的优化
-
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
-
//rdd压缩
-
sparkConf.set("spark.rdd.compress", "true")
-
//batchSize = partitionNum * 分区数量 * 采样时间
-
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "100")
-
//优雅的停止
-
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
-
val ssc = new StreamingContext(sparkConf, Seconds(2))
-
-
/** 获取kafka的数据
-
* LocationStrategies:位置策略,如果kafka的broker节点跟Executor在同一台机器上给一种策略,不在一台机器上给另外一种策略
-
* 设定策略后会以最优的策略进行获取数据
-
* 一般在企业中kafka节点跟Executor不会放到一台机器的,原因是kakfa是消息存储的,Executor用来做消息的计算,
-
* 因此计算与存储分开,存储对磁盘要求高,计算对内存、CPU要求高
-
* 如果Executor节点跟Broker节点在一起的话使用PreferBrokers策略,如果不在一起的话使用PreferConsistent策略
-
* 使用PreferConsistent策略的话,将来在kafka中拉取了数据以后尽量将数据分散到所有的Executor上
-
*/
-
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
-
LocationStrategies.PreferConsistent,
-
ConsumerStrategies.Subscribe[String, String](AppParams.topic, AppParams.kafkaParams))
写到这里我们就已经获取了kafka中的数据了。接下来就是对他进行处理:
9.3、计算充值成功笔数
我们首先做的是计算充值成功的笔数:
由于我们的数据是json的所以要想对数据进行分析的话,就要使用json解析工具:
我们导入json解析工具的依赖:
-
<!-- 导入json依赖包-->
-
<dependency>
-
<groupId>com.alibaba</groupId>
-
<artifactId>fastjson</artifactId>
-
<version>${fastjson.version}</version>
-
</dependency>
各配置文件的版本号如下:
-
<properties>
-
<spark.version>2.2.1</spark.version>
-
<mysql.version>5.1.40</mysql.version>
-
<jedis.version>2.9.0</jedis.version>
-
<config.version>1.3.3</config.version>
-
<fastjson.version>1.2.51</fastjson.version>
-
<scalikejdbc.version>3.3.1</scalikejdbc.version>
-
</properties>
我们的思路是:过滤出serviceName字段为reChargeNotifyReq的数据,这些数据就是和充值通知有关的,我们需要处理的数据。
在过滤出来的这些数据中,有成功的,也有失败的。
过滤完数据之后我们对数据操作,将成功的数据设为1,失败的设为0,并且从requestId中截取出前8位和标志位组成一个元组返回。
然后使用reduceByKey就可以统计出当天交易成功的数量了。
代码如下:
-
/**
-
* 数据处理
-
*/
-
stream.foreachRDD(rdd=>{
-
//取得所有充值通知日志
-
val baseData: RDD[JSONObject] = rdd.map(cr => JSON.parseObject(cr.value()))
-
.filter(obj=> obj.getString("serviceName").equalsIgnoreCase("reChargeNotifyReq")).cache()
-
/**
-
* 获取到充值成功的订单笔数
-
* 回忆:
-
* wordcount flatMap->map->reduceByKey
-
* hadoop spark hadoop
-
*/
-
val totalSucc = baseData.map(obj=>{
-
val reqId = obj.getString("requestId")
-
//获取日期
-
val day = reqId.substring(0, 8)
-
//取出该条充值是否成功的标志
-
val result = obj.getString("bussinessRst")
-
val flag = if(result.equals("0000")) 1 else 0
-
(day, flag)
-
}).reduceByKey(_+_)
-
totalSucc.foreach(println)
-
})
运行结果:

9.4、计算当天充值成功的总金额
现在我们需要做的是统计出当天的交易成功的总金额,我们只要对上面的程序进行修改一下就好了。
之前的代码中如果交易成功返回的是1,而现在我们只要返回交易金额就好了。
代码如下:
-
/**
-
* 获取充值成功的订单金额
-
*/
-
val totalMoney = baseData.map(obj=>{
-
val reqId = obj.getString("requestId")
-
//获取日期
-
val day = reqId.substring(0, 8)
-
//取出该条充值是否成功的标志
-
val result = obj.getString("bussinessRst")
-
val fee = if(result.equals("0000")) obj.getString("chargefee").toDouble else 0
-
(day, fee)
-
}).reduceByKey(_+_)
-
totalMoney.foreach(println)
运行结果:

9.5、计算充值成功率
到现在为止我们已经充值成功的订单量和充值金额写好了。接下来就要算充值成功率了。
充值成功率 = 成功订单数 / 总订单数
总订单量只要使用count就可以得出。而充值成功的订单我们前面已经算出来了。
总订单量计算代码:
-
//总订单量
-
val total = baseData.count()
9.6、计算充值成功的充值时长:
如果是交易成功的则用结束时间(即通知充值成功的时间)- 开始时间(即requestId的前17位)
如果是交易失败的话,则返回0
代码如下:
-
/**
-
* 获取充值成功的充值时长
-
*/
-
val totalTime = baseData.map(obj=>{
-
var reqId = obj.getString("requestId")
-
//获取日期
-
val day = reqId.substring(0, 8)
-
//取出该条充值是否成功的标志
-
val result = obj.getString("bussinessRst")
-
//时 间 格 式 为: yyyyMMddHHmissSSS(( 年月日时分秒毫秒)
-
//获取起始时间与结束时间
-
val endTime = obj.getString("receiveNotifyTime")
-
val startTime = reqId.substring(0, 17)
-
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
-
val cost = if(result.equals("0000")) format.parse(endTime).getTime - format.parse(startTime).getTime else 0
-
(day, cost)
-
}).reduceByKey(_+_)
9.7、将充值成功的订单数写入redis
我们首先在application.conf中添加redis的一些配置:
-
# redis
-
redis.host="hadoop04"
-
redis.db.index=12
接下来在AppParams中添加,对redis参数的访问:
-
/**
-
* redis服务器地址
-
*/
-
val redisHost = config.getString("redis.host")
-
-
/**
-
* 将数据写入到哪个库
-
*/
-
val selectDBIndex = config.getInt("redis.db.index")
然后写一个从连接池获取连接的方法:
-
package cn.sheep.cmcc.utils
-
-
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
-
import redis.clients.jedis.JedisPool
-
-
/**
-
* ZhangJunJie
-
* 2018/10/16 14:32
-
* Describe:
-
**/
-
object Jpools {
-
-
private val poolConfig = new GenericObjectPoolConfig()
-
poolConfig.setMaxIdle(5) //最大的空闲连接数,连接池中最大的空闲连接数,默认是8
-
poolConfig.setMaxTotal(2000) //只支持最大的连接数,连接池中最大的连接数,默认是8
-
-
//连接池是私有的不能对外公开访问
-
private lazy val jedisPool = new JedisPool(poolConfig, AppParams.redisHost)
-
-
def getJedis={
-
val jedis = jedisPool.getResource
-
jedis.select(AppParams.selectDBIndex)
-
jedis
-
}
-
}
接下来写入数据库:
-
totalSucc.foreachPartition(itr =>{
-
val jedis = Jpools.getJedis
-
itr.foreach(tp=>{
-
jedis.incrBy("CMCC-"+tp._1, tp._2)
-
})
-
})
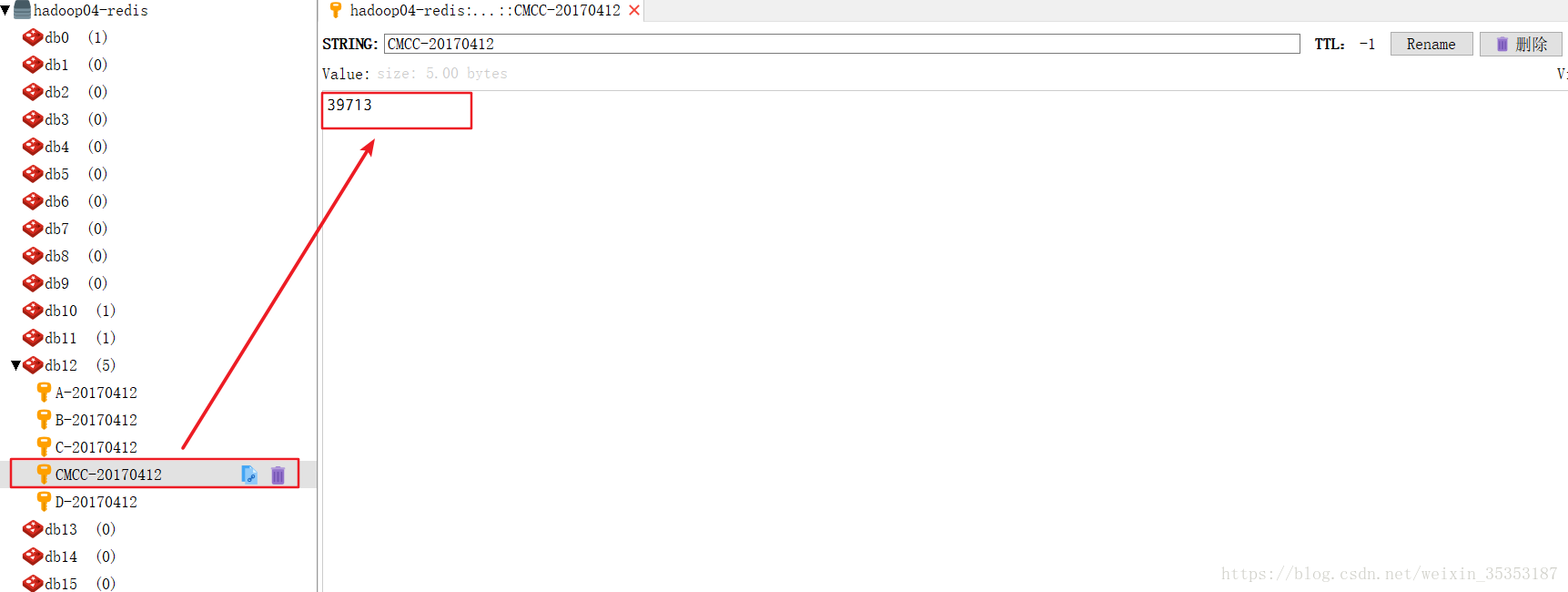
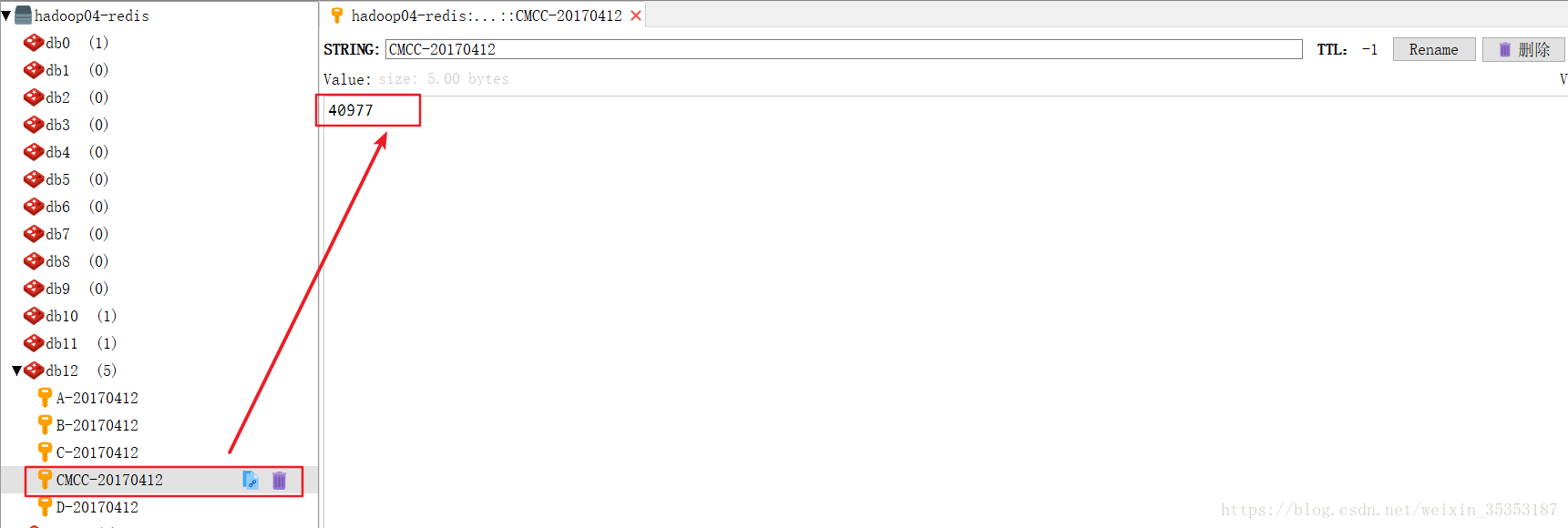
我们可以看到数据在不断的被刷新,在不停的读数据,处理数据,然后做累加
但是这样的写法很不好,而且存在很多的问题,比如频繁的使用reduceByKey,会不停的产生shuffle,这样对性能会有影响。
此时我们的程序还不够优化,我们的各项指标都是单独计算,每次计算都会产生shuffle,这样性能是非常低的,所以我们针对现有的程序进行一个改造。
9.8、优化
以下为优化方案:
接下来进行优化,首先我们将计算时间差的功能提取出来
-
package com.sheep.cmcc.utils
-
-
import java.text.SimpleDateFormat
-
-
object CaculateTools {
-
//非线程安全的
-
private val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
-
def caculateTime(startTime:String,endTime:String):Long = {
-
val start = startTime.substring(0,17)
-
format.parse(endTime).getTime - format.parse(start).getTime
-
}
-
}
可是这样做是有问题的,因为他是非线程安全的。如果想要线程安全,那么我们最好每次调用的时候都new一下那个SimpleDateFormat
所以我们就使用另一个方法,他是线程安全的。
-
package cn.sheep.cmcc.utils
-
-
import java.text.SimpleDateFormat
-
-
import org.apache.commons.lang3.time.FastDateFormat
-
-
/**
-
* ZhangJunJie
-
* 2018/10/16 17:41
-
* Describe:中国移动实时监控平台(优化版)
-
**/
-
object CaculateTools {
-
-
// 非线程安全的
-
//private val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
-
// 线程安全的DateFormat
-
private val format: FastDateFormat = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
-
-
/**
-
* 计算时间差
-
* @param startTime
-
* @param endTime
-
* @return
-
*/
-
def caculateTime(startTime:String, endTime:String):Long = {
-
val start = startTime.substring(0, 17)
-
format.parse(endTime).getTime - format.parse(start).getTime
-
}
-
}
代码实现:
-
package com.sheep.cmcc.app
-
-
import java.lang
-
-
import com.alibaba.fastjson.{JSON, JSONObject}
-
import com.sheep.cmcc.utils.{AppParams, CaculateTools, Jpools}
-
import org.apache.kafka.clients.consumer.ConsumerRecord
-
import org.apache.log4j.{Level, Logger}
-
import org.apache.spark.SparkConf
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
import org.apache.spark.streaming.dstream.InputDStream
-
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
-
import redis.clients.jedis.Jedis
-
-
/**
-
* 中国移动监控平台优化版
-
*/
-
object BootStrapAppV2 {
-
def main(args: Array[String]): Unit = {
-
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
-
val conf: SparkConf = new SparkConf()
-
.setAppName("中国移动运营实时监控平台-Monitor")
-
//如果是在集群上运行的话需要去掉setMaster
-
.setMaster("local[*]")
-
//SparkStreaming传输的是离散流,离散流是由RDD组成的
-
//数据传输的时候可以对RDD进行压缩,压缩的目的是减少内存的占用
-
//默认采用org.apache.spark.serializer.JavaSerializer
-
//这是最基本的优化
-
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
-
//rdd压缩
-
conf.set("spark.rdd.compress","true")
-
//设置每次拉取的数量,为了防止一下子拉取的数据过多,系统处理不过来
-
//这里并不是拉取100条,是有公式的。
-
//batchSize = partitionNum * 分区数量 * 采样时间
-
conf.set("spark.streaming.kafka.maxRatePerPartition","100")
-
//设置优雅的结束,这样可以避免数据的丢失
-
conf.set("spark.streaming.stopGracefullyOnShutdown","true")
-
val ssc: StreamingContext = new StreamingContext(conf,Seconds(2))
-
//获取kafka的数据
-
/**
-
* 指定kafka数据源
-
* ssc:StreamingContext的实例
-
* LocationStrategies:位置策略,如果kafka的broker节点跟Executor在同一台机器上给一种策略,不在一台机器上给另外一种策略
-
* 设定策略后会以最优的策略进行获取数据
-
* 一般在企业中kafka节点跟Executor不会放到一台机器的,原因是kakfa是消息存储的,Executor用来做消息的计算,
-
* 因此计算与存储分开,存储对磁盘要求高,计算对内存、CPU要求高
-
* 如果Executor节点跟Broker节点在一起的话使用PreferBrokers策略,如果不在一起的话使用PreferConsistent策略
-
* 使用PreferConsistent策略的话,将来在kafka中拉取了数据以后尽量将数据分散到所有的Executor上
-
* ConsumerStrategies:消费者策略(指定如何消费)
-
*
-
*/
-
val directStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
-
LocationStrategies.PreferConsistent,
-
ConsumerStrategies.Subscribe[String,String](AppParams.topic,AppParams.kafkaParams)
-
)
-
//serviceName为reChargeNotifyReq的才被认为是充值通知
-
directStream.foreachRDD(rdd =>{
-
//取得所有充值通知日志
-
val baseData= rdd.map(cr =>JSON.parseObject(cr.value()))
-
.filter(obj => obj.getString("serviceName").equalsIgnoreCase("reChargeNotifyReq"))
-
.map(obj => {
-
//判断这条日志是否是充值成功的日志
-
val result = obj.getString("bussinessRst")
-
//获取充值金额
-
val fee: lang.Double = obj.getDouble("chargefee")
-
//充值发起的时间和结束时间
-
val requestId: String = obj.getString("requestId")
-
//数据当前时间
-
val day = requestId.substring(0,8)
-
val receiveTime: String = obj.getString("receiveNotifyTime")
-
//取得充值时长
-
val costTime = CaculateTools.caculateTime(requestId,receiveTime)
-
val succAndFeeAndTime: (Double, Double, Double) = if(result.equals("0000")) (1,fee,costTime) else(0,0,0)
-
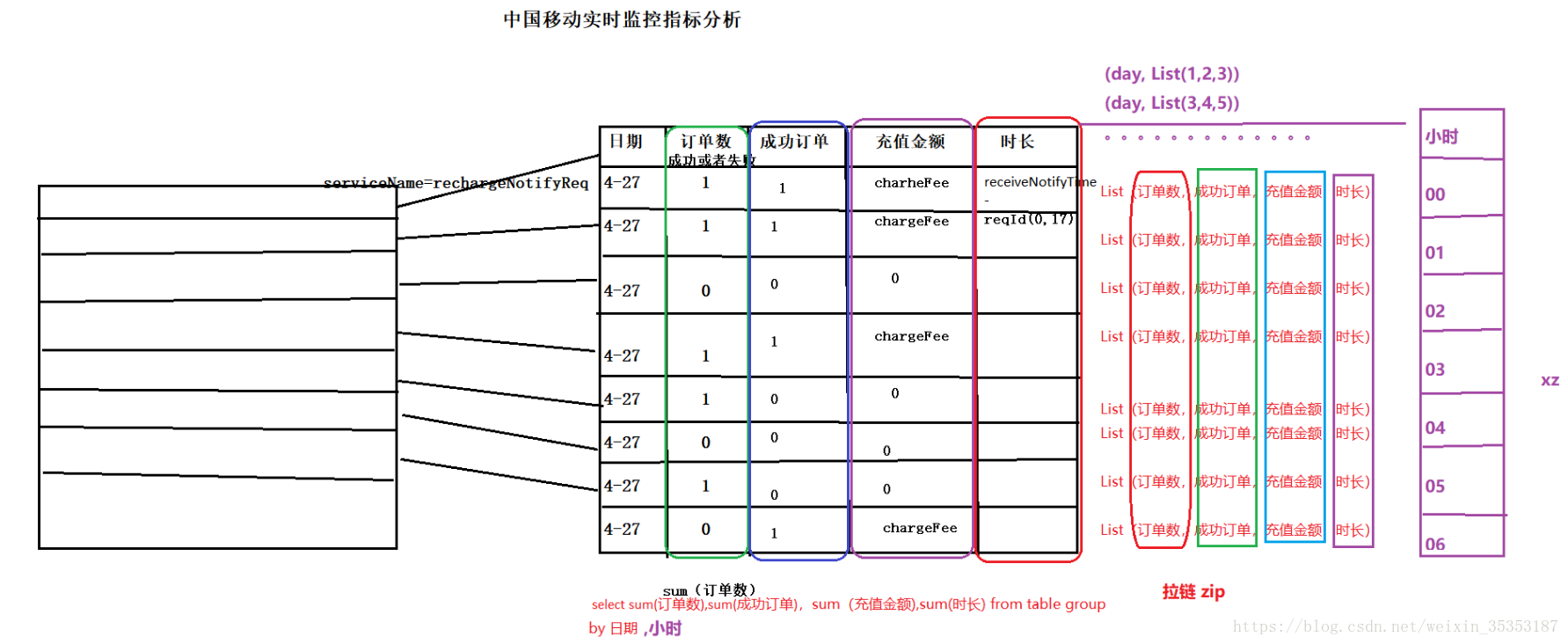
//(日期,List(订单数,成功订单,订单金额,充值时长))
-
(day,List[Double](1,succAndFeeAndTime._1,succAndFeeAndTime._2,succAndFeeAndTime._3))
-
}).cache()
-
-
baseData.reduceByKey(_.zip(_).map(tp => {tp._1+tp._2}))
-
.foreachPartition(partition =>{
-
val jedis: Jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
jedis.hincrBy("A-"+tp._1,"total",tp._2(0).toLong)
-
jedis.hincrBy("A-"+tp._1,"succ",tp._2(1).toLong)
-
jedis.hincrByFloat("A-"+tp._1,"money",tp._2(2))
-
jedis.hincrBy("A-"+tp._1,"cost",tp._2(3).toLong)
-
//设置key的过期时间
-
jedis.expire("A-"+tp._1,60*60*48)
-
})
-
jedis.close()
-
})
-
})
-
ssc.start()
-
ssc.awaitTermination()
-
-
}
-
}
运行结果如下:
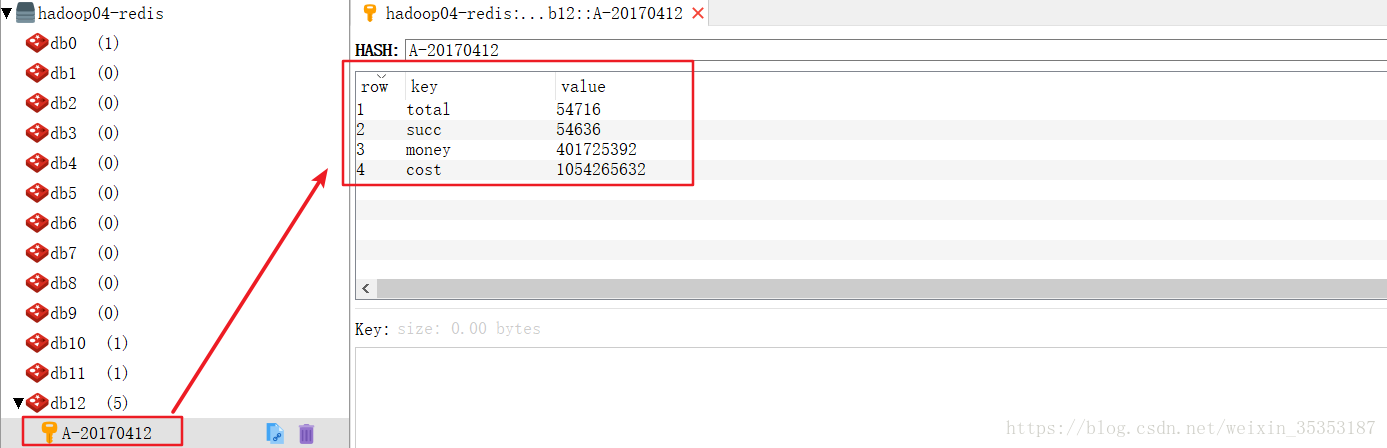
到此,我们的整体业务就算做完了
9.9、实时业务办理趋势
上面的业务是按照天统计的,下面的业务是按照小时统计的。
这里我们需要的是两个计算维度:按小时计算:
计算内容:充值成功订单量,成功率
其实我们只需要统计出来某时的总订单量和充值成功的订单量,而充值成功率可以根据这两个值推算出来。
我们之前的表维度都是按照日期进行划分的,现在用日期肯定不行了,所以我们就用日期加小时数做一个维度。
改了维度之后我们就需要在原来返回的元组之上再加一个小时维度。
-
// (日期, 小时, Kpi(充值成功和失败订单数,成功订单,订单金额,订单时长))
-
(day, hour, List[Double](1, succAndFeeAndTime._1, succAndFeeAndTime._2, succAndFeeAndTime._3), provinceCode, minute)
而现在由于返回的元组已经不是对偶元组了,对于之前按天统计的业务,不能进行reduceByKey,所以需要重构一下。
-
/**
-
* 业务概况(总订单量、成功订单量、充值成功总金额、时长)
-
* @param baseData
-
*/
-
def kpi_general(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => (tp._1, tp._3)).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
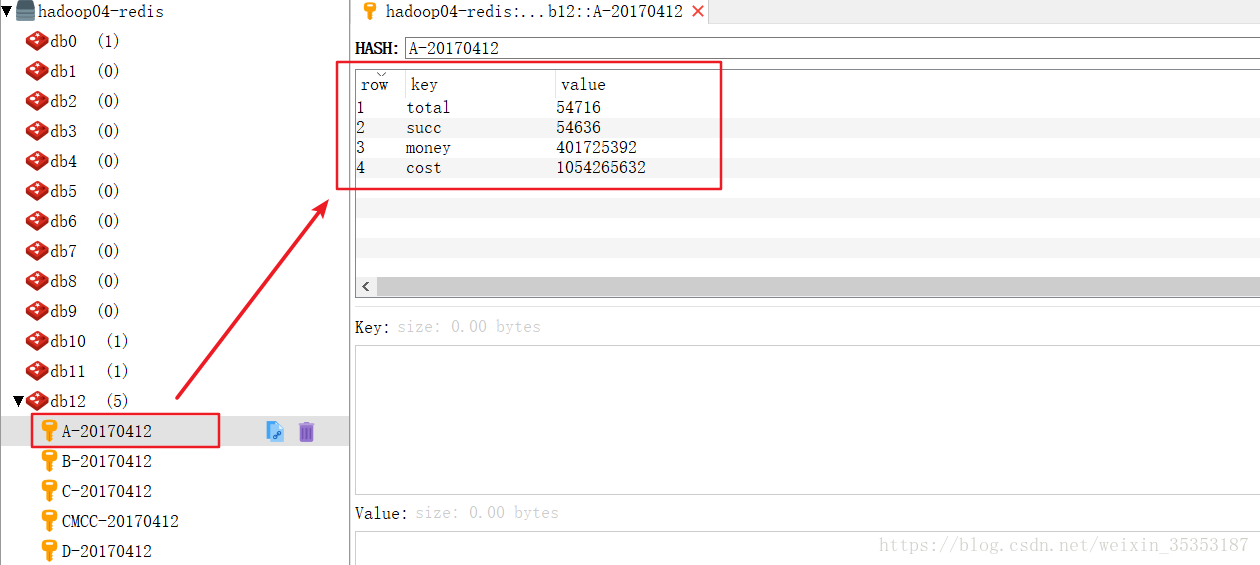
jedis.hincrBy("A-" + tp._1, "total", tp._2(0).toLong)
-
jedis.hincrBy("A-" + tp._1, "succ", tp._2(1).toLong)
-
jedis.hincrByFloat("A-" + tp._1, "money", tp._2(2))
-
jedis.hincrBy("A-" + tp._1, "cost", tp._2(3).toLong) // key的有效期
-
jedis.expire("A-" + tp._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
运行结果:
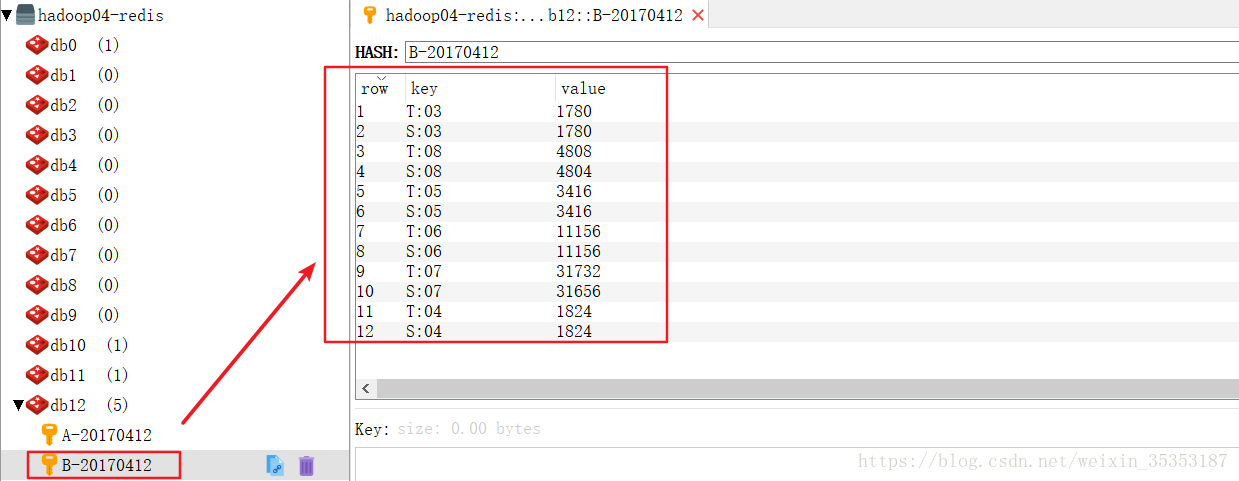
而之后我们要写的按小时统计的业务,我们需要将key变为日期和小时的集合,因为如果不加上日期的话会出现日期混淆的情况。
-
/**
-
* 业务概述-(每小时的充值总订单量,每小时的成功订单量)
-
* @param baseData
-
*/
-
def kpi_general_hour(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => ((tp._1, tp._2), List(tp._3(0), tp._3(1)))).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
//总的充值成功和失败订单数量
-
jedis.hincrBy("B-" + tp._1._1, "T:" + tp._1._2, tp._2(0).toLong) //充值成功的订单数量
-
jedis.hincrBy("B-" + tp._1._1, "S:" + tp._1._2, tp._2(1).toLong) // key的有效期
-
jedis.expire("B-" + tp._1._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
运行结果:
接下来我们还要进行优化,因为我们可以看到随着指标的增多,我们的代码很凌乱。
所以我们就可以将所有关于指标的函数和方法都封装起来
封装类:
-
package cn.sheep.cmcc.utils
-
-
import com.alibaba.fastjson.JSON
-
import org.apache.kafka.clients.consumer.ConsumerRecord
-
import org.apache.spark.broadcast.Broadcast
-
import org.apache.spark.rdd.RDD
-
-
/**
-
* ZhangJunJie
-
* 2018/10/17 8:40
-
* Describe:
-
**/
-
object KpiTools {
-
-
/**
-
* 业务概况(总订单量、成功订单量、充值成功总金额、时长)
-
* @param baseData
-
*/
-
def kpi_general(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => (tp._1, tp._3)).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
jedis.hincrBy("A-" + tp._1, "total", tp._2(0).toLong)
-
jedis.hincrBy("A-" + tp._1, "succ", tp._2(1).toLong)
-
jedis.hincrByFloat("A-" + tp._1, "money", tp._2(2))
-
jedis.hincrBy("A-" + tp._1, "cost", tp._2(3).toLong) // key的有效期
-
jedis.expire("A-" + tp._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
-
-
/**
-
* 业务概述-(每小时的充值总订单量,每小时的成功订单量)
-
* @param baseData
-
*/
-
def kpi_general_hour(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => ((tp._1, tp._2), List(tp._3(0), tp._3(1)))).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
//总的充值成功和失败订单数量
-
jedis.hincrBy("B-" + tp._1._1, "T:" + tp._1._2, tp._2(0).toLong) //充值成功的订单数量
-
jedis.hincrBy("B-" + tp._1._1, "S:" + tp._1._2, tp._2(1).toLong) // key的有效期
-
jedis.expire("B-" + tp._1._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
-
-
-
/**
-
* 整理基础数据
-
* @param rdd
-
* @return
-
*/
-
def baseDataRDD(rdd: RDD[ConsumerRecord[String, String]]) = {
-
rdd // ConsumerRecord => JSONObject
-
.map(cr => JSON.parseObject(cr.value())) // 过滤出充值通知日志
-
.filter(obj => obj.getString("serviceName").equalsIgnoreCase("reChargeNotifyReq")).map(obj => {
-
// 判断该条日志是否是充值成功的日志
-
val result = obj.getString("bussinessRst")
-
val fee = obj.getDouble("chargefee")
-
-
// 充值发起时间和结束时间
-
val requestId = obj.getString("requestId")
-
// 数据当前日期
-
val day = requestId.substring(0, 8)
-
val hour = requestId.substring(8, 10)
-
val minute = requestId.substring(10, 12)
-
val receiveTime = obj.getString("receiveNotifyTime")
-
-
//省份Code
-
val provinceCode = obj.getString("provinceCode")
-
val costTime = CaculateTools.caculateTime(requestId, receiveTime)
-
val succAndFeeAndTime: (Double, Double, Double) = if (result.equals("0000")) (1, fee, costTime) else (0, 0, 0)
-
-
// (日期, 小时, Kpi(充值成功和失败订单数,成功订单,订单金额,订单时长))
-
(day, hour, List[Double](1, succAndFeeAndTime._1, succAndFeeAndTime._2, succAndFeeAndTime._3), provinceCode, minute)
-
}).cache()
-
}
-
}
封装之后的主代码:
-
package cn.sheep.cmcc.app
-
-
import cn.sheep.cmcc.utils.{AppParams, KpiTools, OffsetManager}
-
import org.apache.kafka.clients.consumer.ConsumerRecord
-
import org.apache.spark.SparkConf
-
import org.apache.spark.broadcast.Broadcast
-
import org.apache.spark.streaming.dstream.InputDStream
-
import org.apache.spark.streaming.kafka010._
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
-
/**
-
* ZhangJunJie
-
* 2018/10/16 17:58
-
* Describe:中国移动实时监控平台(优化版)
-
**/
-
-
object BootStarpAppV2 {
-
def main(args: Array[String]): Unit = {
-
-
val sparkConf = new SparkConf()
-
sparkConf.setAppName("中国移动运营实时监控平台-Monitor") //如果在集群上运行的话,需要去掉:sparkConf.setMaster("local[*]")
-
sparkConf.setMaster("local[*]") //将rdd以序列化格式来保存以减少内存的占用
-
//默认采用org.apache.spark.serializer.JavaSerializer
-
//这是最基本的优化
-
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") //rdd压缩
-
sparkConf.set("spark.rdd.compress", "true") //batchSize = partitionNum * 分区数量 * 采样时间
-
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "10000") //优雅的停止
-
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
-
val ssc = new StreamingContext(sparkConf, Seconds(2))
-
-
/**
-
* 提取数据库中存储的偏移量
-
*/
-
val currOffset = OffsetManager.getMydbCurrentOffset
-
-
/**
-
* 广播省份映射关系
-
*/
-
val pcode2PName: Broadcast[Map[String, AnyRef]] = ssc.sparkContext.broadcast(AppParams.pCode2PName)
-
-
/** 获取kafka的数据
-
* LocationStrategies:位置策略,如果kafka的broker节点跟Executor在同一台机器上给一种策略,不在一台机器上给另外一种策略
-
* 设定策略后会以最优的策略进行获取数据
-
* 一般在企业中kafka节点跟Executor不会放到一台机器的,原因是kakfa是消息存储的,Executor用来做消息的计算,
-
* 因此计算与存储分开,存储对磁盘要求高,计算对内存、CPU要求高
-
* 如果Executor节点跟Broker节点在一起的话使用PreferBrokers策略,如果不在一起的话使用PreferConsistent策略
-
* 使用PreferConsistent策略的话,将来在kafka中拉取了数据以后尽量将数据分散到所有的Executor上 */
-
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
-
LocationStrategies.PreferConsistent,
-
ConsumerStrategies.Subscribe[String, String](AppParams.topic, AppParams.kafkaParams, currOffset)
-
)
-
-
/**
-
* 数据处理
-
*/
-
stream.foreachRDD(rdd=>{
-
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
-
-
val baseData = KpiTools.baseDataRDD(rdd)
-
-
/**
-
* 计算业务概况
-
*/
-
KpiTools.kpi_general(baseData)
-
KpiTools.kpi_general_hour(baseData)
-
-
/**
-
* 业务质量
-
*/
-
KpiTools.kpi_quality(baseData, pcode2PName)
-
-
/**
-
* 实时充值情况分析
-
*/
-
KpiTools.kpi_realtime_minute(baseData)
-
-
/**
-
* 存储偏移量
-
*/
-
OffsetManager.saveCurrentOffset(offsetRanges)
-
})
-
-
ssc.start()
-
ssc.awaitTermination()
-
}
-
}
接下来开始写我们的下一个业务:由于我们这里的数据基本上都是充值成功的,所以我们这里就不统计充值失败的了。我们这里统计充值成功的全国分布。
9.10、计算充值成功的全国分布
计算维度:日期+地区
计算内容:充值成功的订单量
这样我们就需要将之前的代码进行修改增加一个字段:
-
package cn.sheep.cmcc.utils
-
-
import com.alibaba.fastjson.JSON
-
import org.apache.kafka.clients.consumer.ConsumerRecord
-
import org.apache.spark.broadcast.Broadcast
-
import org.apache.spark.rdd.RDD
-
-
/**
-
* ZhangJunJie
-
* 2018/10/17 8:40
-
* Describe:
-
**/
-
object KpiTools {
-
-
/**
-
* 业务概况(总订单量、成功订单量、充值成功总金额、时长)
-
* @param baseData
-
*/
-
def kpi_general(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => (tp._1, tp._3)).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
jedis.hincrBy("A-" + tp._1, "total", tp._2(0).toLong)
-
jedis.hincrBy("A-" + tp._1, "succ", tp._2(1).toLong)
-
jedis.hincrByFloat("A-" + tp._1, "money", tp._2(2))
-
jedis.hincrBy("A-" + tp._1, "cost", tp._2(3).toLong) // key的有效期
-
jedis.expire("A-" + tp._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
-
-
/**
-
* 业务概述-(每小时的充值总订单量,每小时的成功订单量)
-
* @param baseData
-
*/
-
def kpi_general_hour(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => ((tp._1, tp._2), List(tp._3(0), tp._3(1)))).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp => tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
//总的充值成功和失败订单数量
-
jedis.hincrBy("B-" + tp._1._1, "T:" + tp._1._2, tp._2(0).toLong) //充值成功的订单数量
-
jedis.hincrBy("B-" + tp._1._1, "S:" + tp._1._2, tp._2(1).toLong) // key的有效期
-
jedis.expire("B-" + tp._1._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
-
-
/**
-
* 业务质量
-
* @param baseData
-
*/
-
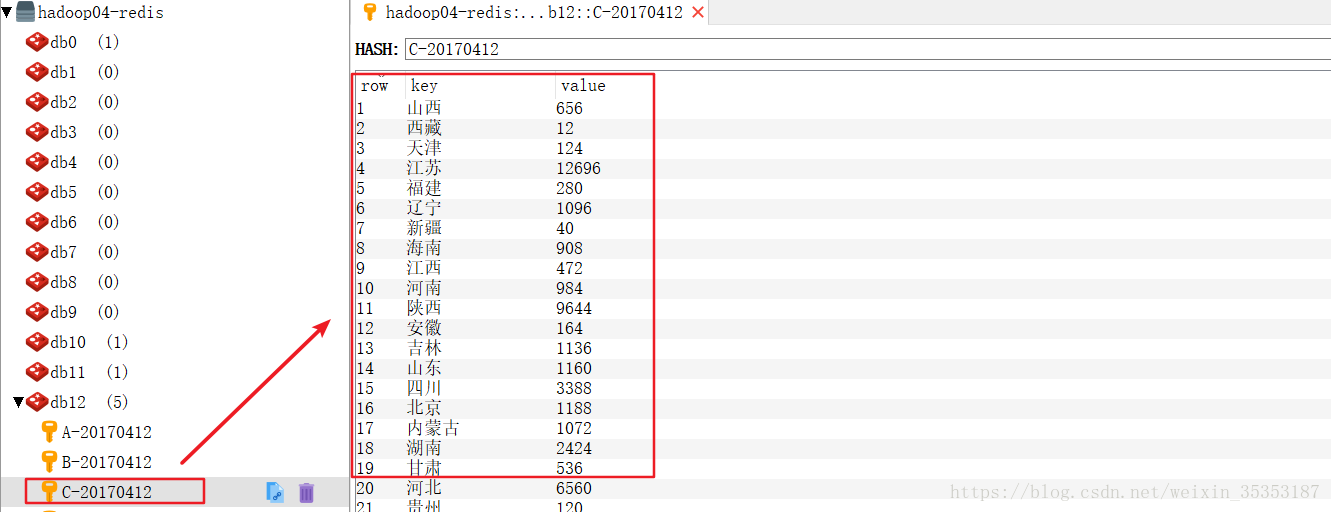
def kpi_quality(baseData: RDD[(String, String, List[Double], String, String)], p2p: Broadcast[Map[String, AnyRef]]) = {
-
baseData.map(tp => ((tp._1, tp._4), tp._3(1))).reduceByKey(_+_).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
//总的充值成功和失败订单数量
-
jedis.hincrBy("C-" + tp._1._1, p2p.value.getOrElse(tp._1._2, tp._1._2).toString , tp._2.toLong) //充值成功的订单数量
-
jedis.expire("C-" + tp._1._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
-
-
/**
-
* 整理基础数据
-
* @param rdd
-
* @return
-
*/
-
def baseDataRDD(rdd: RDD[ConsumerRecord[String, String]]) = {
-
rdd // ConsumerRecord => JSONObject
-
.map(cr => JSON.parseObject(cr.value())) // 过滤出充值通知日志
-
.filter(obj => obj.getString("serviceName").equalsIgnoreCase("reChargeNotifyReq")).map(obj => {
-
// 判断该条日志是否是充值成功的日志
-
val result = obj.getString("bussinessRst")
-
val fee = obj.getDouble("chargefee")
-
-
// 充值发起时间和结束时间
-
val requestId = obj.getString("requestId")
-
// 数据当前日期
-
val day = requestId.substring(0, 8)
-
val hour = requestId.substring(8, 10)
-
val minute = requestId.substring(10, 12)
-
val receiveTime = obj.getString("receiveNotifyTime")
-
-
//省份Code
-
val provinceCode = obj.getString("provinceCode")
-
val costTime = CaculateTools.caculateTime(requestId, receiveTime)
-
val succAndFeeAndTime: (Double, Double, Double) = if (result.equals("0000")) (1, fee, costTime) else (0, 0, 0)
-
-
// (日期, 小时, Kpi(充值成功和失败订单数,成功订单,订单金额,订单时长))
-
(day, hour, List[Double](1, succAndFeeAndTime._1, succAndFeeAndTime._2, succAndFeeAndTime._3), provinceCode, minute)
-
}).cache()
-
}
-
}
运行结果:
9.11、计算每分钟实时充值情况
接下来我们要写的就是每分钟实时充值情况的分布
计算维度:日期+小时+分钟
计算内容:充值笔数,充值金额
这样我们又要增加一个分钟字段:
-
/**
-
* 实时统计每分钟的充值金额和订单量
-
* @param baseData
-
*/
-
def kpi_realtime_minute(baseData: RDD[(String, String, List[Double], String, String)]) = {
-
baseData.map(tp => ((tp._1, tp._2, tp._5), List(tp._3(1), tp._3(2)))).reduceByKey((list1, list2) => {
-
list1.zip(list2).map(tp=> tp._1 + tp._2)
-
}).foreachPartition(partition => {
-
val jedis = Jpools.getJedis
-
partition.foreach(tp => {
-
//每分钟充值成功笔数和充值金额
-
jedis.hincrBy("D-" + tp._1._1, "C:"+ tp._1._2+tp._1._3, tp._2(0).toLong)
-
jedis.hincrByFloat("D-" + tp._1._1, "M:"+ tp._1._2+tp._1._3, tp._2(1))
-
-
jedis.expire("D-" + tp._1._1, 48 * 60 * 60)
-
})
-
jedis.close()
-
})
-
}
之前我们在做业务质量的时候只是将省份编号写进去了,并没有将省份编号和省份名称对应起来,对应如下:
在配置文件application.conf中加入省份与省份编号的对应
-
#映射配置
-
pcode2pname{
-
100="北京"
-
200="广东"
-
210="上海"
-
220="天津"
-
230="重庆"
-
240="辽宁"
-
250="江苏"
-
270="湖北"
-
280="四川"
-
290="陕西"
-
311="河北"
-
351="山西"
-
371="河南"
-
431="吉林"
-
451="黑龙江"
-
471="内蒙古"
-
531="山东"
-
551="安徽"
-
571="浙江"
-
591="福建"
-
731="湖南"
-
771="广西"
-
791="江西"
-
851="贵州"
-
871="云南"
-
891="西藏"
-
898="海南"
-
931="甘肃"
-
951="宁夏"
-
971="青海"
-
991="新疆"
-
}
在AppParams加入省份code和省份名称的映射关系
-
/**
-
* 省份code和省份名称的映射关系
-
*/
-
import scala.collection.JavaConversions._
-
val pCode2PName = config.getObject("pcode2pname").unwrapped().toMap
然后在主代码中将这些对应广播出去:
-
/**
-
* 广播省份映射关系
-
*/
-
val pcode2PName: Broadcast[Map[String, AnyRef]] = ssc.sparkContext.broadcast(AppParams.pCode2PName)
9.12、维护偏移量
到现在我们已经把所有指标都分析完了。可是我们还有一件事没有做,就是维护偏移量。
接下来我们要将偏移量,存储到mysql
首先我们来了解一下这个类库
9.12.1、什么是ScalikeJDBC
ScalikeJDBC是一款给Scala开发者使用的简洁DB访问类库,它是基于SQL的,使用者只需要关注SQL逻辑的编写,所有的数据库操作都交给ScalikeJDBC。这个类库内置包含了JDBC API,并且给用户提供了简单易用并且非常灵活的API。并且,QueryDSL(通用查询查询框架)使你的代码类型安全的并且可重复使用。我们可以在生产环境大胆地使用这款DB访问类库。
添加依赖:
-
<dependency>
-
<groupId>org.scalikejdbc</groupId>
-
<artifactId>scalikejdbc_2.11</artifactId>
-
<version>3.3.1</version>
-
</dependency>
-
<dependency>
-
<groupId>org.scalikejdbc</groupId>
-
<artifactId>scalikejdbc-core_2.11</artifactId>
-
<version>3.3.1</version>
-
</dependency>
我们先写一个demo来看看怎么用:
数据库配置文件:
-
# MySQL example
-
db.default.driver="com.mysql.jdbc.Driver"
-
db.default.url="jdbc:mysql://127.0.0.1:3306/bigdata?characterEncoding=utf-8"
-
db.default.user="root"
-
db.default.password="123456"
Demo:
-
package com.sheep.cmcc.app
-
-
import scalikejdbc.config._
-
import scalikejdbc._
-
-
/***
-
* scalike 访问mysql测试
-
*/
-
object ScalikeJdbcDemo {
-
def main(args: Array[String]): Unit = {
-
//读取mysql的配置 application.conf -> application.json -> application.properties
-
DBs.setup()
-
//查询数据(只读)
-
DB.readOnly(
-
implicit session =>{
-
SQL("select * from wordcount").map(rs=>{
-
(rs.string("words"),
-
rs.int(2))
-
}).list().apply()
-
}.foreach(println)
-
)
-
//删除数据
-
DB.autoCommit(
-
implicit session => {
-
SQL("delete from wordcount where words='shabi'").update().apply()
-
}
-
)
-
//事务
-
DB.localTx(implicit session =>{
-
SQL("insert into wordcount values(?,?)").bind("hadoop",10).update().apply()
-
var r = 1 / 0
-
SQL("insert into wordcount values(?,?)").bind("php",20).update().apply()
-
})
-
}
-
}
经过上次的准备我们现在来实现将偏移量存入mysql
为了在mysql中存储偏移量我们首先要在mysql中创建表:

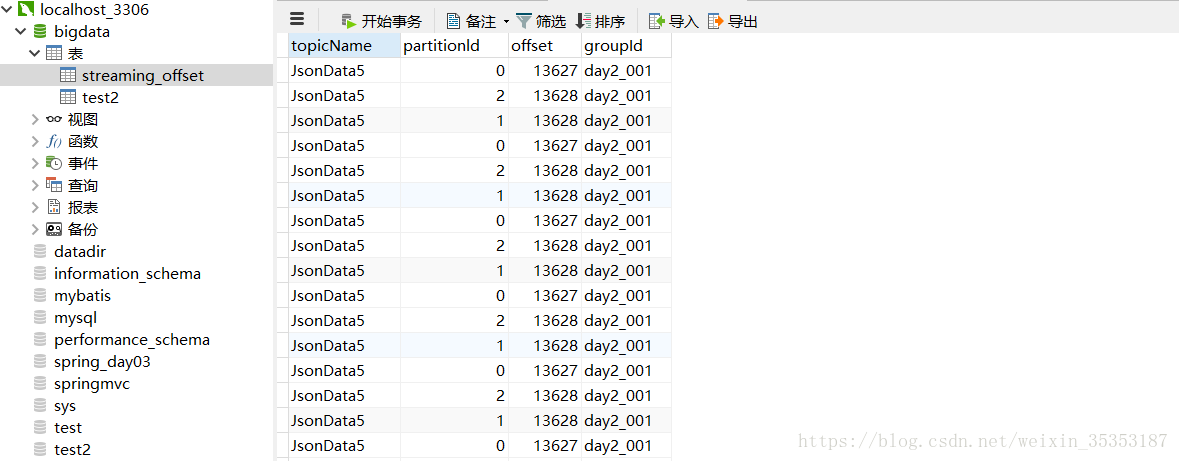
当我们第一次执行这个代码的时候,就会将偏移量记录到mysql,当我们第二次执行的时候,就不会再存储原来的数据了。
其实这样写的话,是不太好的,因为将偏移量和数据存储到两个地方不好做事务,其实我们应该都存储到这样就可以做事务。