三、课堂目标
1. 掌握hbase的客户端API操作
2. 掌握hbase集成MapReduce
3. 掌握hbase集成hive
4. 掌握hbase表的rowkey设计
5. 掌握hbase表的热点
6. 掌握hbase表的数据备份
7. 掌握hbase二级索引
四、知识要点
1. hbase客户端API操作
- 创建Maven工程,添加依赖
<dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
- hbase表的增删改查操作
具体操作详细见==《hbase表的增删改查操作.md》==文档
1、初始化一个init方法
2、创建一个表
3、修改表属性
4、put添加数据
5、get查询单条数据
6、scan批量查询数据
7、delete删除表中的列数据
8、删除表
9、过滤器的使用
- 过滤器的类型很多,但是考科一分为两大类--比较过滤器,专用过滤器
- 过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
9.1、hbase过滤器的比较运算符
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
9.2、hbase过滤器的比较器(指定比较机制)
BinaryComparator 按字节索引顺序比较指定字节数组
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator 判断提供的子串是否出现在value中。
9.3、过滤器使用实战
9.3.1、针对行键的前缀过滤器
- PrefixFilter
public void testFilter1() throws Exception { // 针对行键的前缀过滤器 Filter pf = new PrefixFilter(Bytes.toBytes("liu"));//"liu".getBytes() testScan(pf); } //定义一个方法,接受一个过滤器,返回结果数据 public void testScan(Filter filter) throws Exception { Table table = conn.getTable(TableName.valueOf("t_user_info")); Scan scan = new Scan(); //设置过滤器 scan.setFilter(filter); ResultScanner scanner = table.getScanner(scan); Iterator<Result> iter = scanner.iterator(); //遍历所有的Result对象,获取结果 while (iter.hasNext()) { Result result = iter.next(); List<Cell> cells = result.listCells(); for (Cell c : cells) { //获取行键 byte[] rowBytes = CellUtil.cloneRow(c); //获取列族 byte[] familyBytes = CellUtil.cloneFamily(c); //获取列族下的列名称 byte[] qualifierBytes = CellUtil.cloneQualifier(c); //列字段的值 byte[] valueBytes = CellUtil.cloneValue(c); System.out.print(new String(rowBytes)+" "); System.out.print(new String(familyBytes)+":"); System.out.print(new String(qualifierBytes)+" "); System.out.println(new String(valueBytes)); } System.out.println("-----------------------"); } }
9.3.2 行过滤器
RowFilter
public void testFilter2() throws Exception { // 行过滤器 需要一个比较运算符和比较器 RowFilter rf1 = new RowFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("user002"))); testScan(rf1); RowFilter rf2 = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("01"));//rowkey包含"01"子串的 testScan(rf2); }
9.3.3 列族过滤器
FamilyFilter
public void testFilter3() throws Exception { //针对列族名的过滤器 返回结果中只会包含满足条件的列族中的数据 FamilyFilter ff1 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("base_info"))); FamilyFilter ff2 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base"))); testScan(ff2); }
9.3.4 列名过滤器
QualifierFilter
public void testFilter4() throws Exception { //针对列名的过滤器 返回结果中只会包含满足条件的列的数据 QualifierFilter qf1 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("password"))); QualifierFilter qf2 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("user"))); testScan(qf2); }
9.3.5 列值的过滤器
SingleColumnValueFilter
public void testFilter4() throws Exception { //针对指定一个列的value的比较器来过滤 ByteArrayComparable comparator1 = new RegexStringComparator("^zhang"); //以zhang开头的 ByteArrayComparable comparator2 = new SubstringComparator("si"); //包含"si"子串 SingleColumnValueFilter scvf = new SingleColumnValueFilter("base_info".getBytes(), "username".getBytes(), CompareFilter.CompareOp.EQUAL, comparator2); testScan(scvf); }
9.3.6 多个过滤器同时使用
public void testFilter4() throws Exception { //多个过滤器同时使用 select * from t1 where id >10 and age <30 //构建一个列族的过滤器 FamilyFilter cfff1 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base"))); //构建一个列的前缀过滤器 ColumnPrefixFilter cfff2 = new ColumnPrefixFilter("password".getBytes()); //指定多个过滤器是否同时都要满足条件 FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ONE); filterList.addFilter(cfff1); filterList.addFilter(cfff2); testScan(filterList); }
2 hbase集成MapReduce
HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,并且MR可以将处理后的结果直接存储到HBase表中。
2.1 实战一
需求
- ==读取hbase某张表中的数据,然后把结果写入到另外一张hbase表==
package com.kaikeba; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import java.io.IOException; public class HBaseMR { public static class HBaseMapper extends TableMapper<Text,Put>{ @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { //获取rowkey的字节数组 byte[] bytes = key.get(); String rowkey = Bytes.toString(bytes); //构建一个put对象 Put put = new Put(bytes); //获取一行中所有的cell对象 Cell[] cells = value.rawCells(); for (Cell cell : cells) { // f1列族 if("f1".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){ // name列名 if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } // age列名 if("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } } } if(!put.isEmpty()){ context.write(new Text(rowkey),put); } } } public static class HbaseReducer extends TableReducer<Text,Put,ImmutableBytesWritable>{ @Override protected void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException { for (Put put : values) { context.write(null,put); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Scan scan = new Scan(); Job job = Job.getInstance(conf); job.setJarByClass(HBaseMR.class); //使用TableMapReduceUtil 工具类来初始化我们的mapper TableMapReduceUtil.initTableMapperJob(TableName.valueOf(args[0]),scan,HBaseMapper.class,Text.class,Put.class,job); //使用TableMapReduceUtil 工具类来初始化我们的reducer TableMapReduceUtil.initTableReducerJob(args[1],HbaseReducer.class,job); //设置reduce task个数 job.setNumReduceTasks(1); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
打成jar包提交到集群中运行
hadoop jar hbase_java_api-1.0-SNAPSHOT.jar com.kaikeba.HBaseMR t1 t2
2.2 实战二
需求
- ==读取HDFS文件,把内容写入到HBase表中==
hdfs上数据文件 user.txt
0001 xiaoming 20
0002 xiaowang 30
0003 xiaowu 40
代码开发
package com.kaikeba; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import java.io.IOException; public class Hdfs2Hbase { public static class HdfsMapper extends Mapper<LongWritable,Text,Text,NullWritable> { protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } } public static class HBASEReducer extends TableReducer<Text,NullWritable,ImmutableBytesWritable> { protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { String[] split = key.toString().split(" "); Put put = new Put(Bytes.toBytes(split[0])); put.addColumn("f1".getBytes(),"name".getBytes(),split[1].getBytes()); put.addColumn("f1".getBytes(),"age".getBytes(), split[2].getBytes()); context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])),put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(Hdfs2Hbase.class); job.setInputFormatClass(TextInputFormat.class); //输入文件路径 TextInputFormat.addInputPath(job,new Path(args[0])); job.setMapperClass(HdfsMapper.class); //map端的输出的key value 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); //指定输出到hbase的表名 TableMapReduceUtil.initTableReducerJob(args[1],HBASEReducer.class,job); //设置reduce个数 job.setNumReduceTasks(1); System.exit(job.waitForCompletion(true)?0:1); } }
创建hbase表 t3
create 't3','f1'
打成jar包提交到集群中运行
hadoop jar hbase_java_api-1.0-SNAPSHOT.jar com.kaikeba.Hdfs2Hbase /data/user.txt t3
2.3 实战三
需求
- ==通过bulkload的方式批量加载数据到HBase表中==
把hdfs上面的这个路径/input/user.txt的数据文件,转换成HFile格式,然后load到user这张表里面中
知识点描述
加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,但是这些方式不是慢就是在导入的过程的占用Region资料导致效率低下,我们也可以通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
HBase数据正常写流程回顾
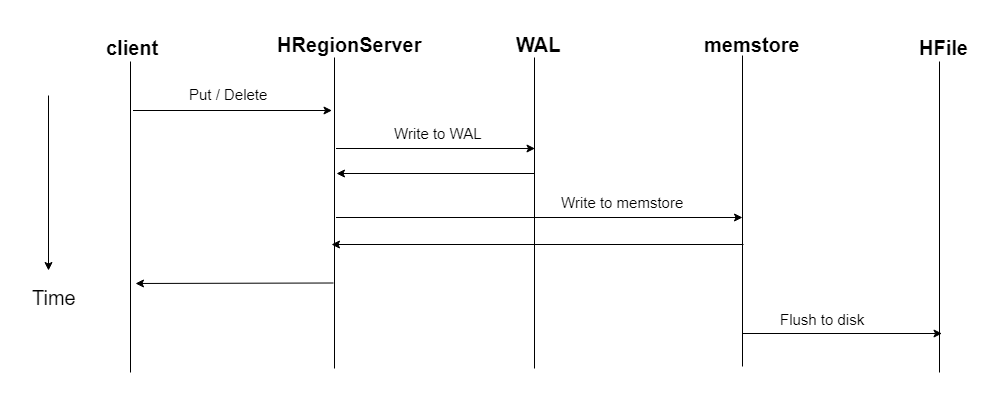
bulkload方式的处理示意图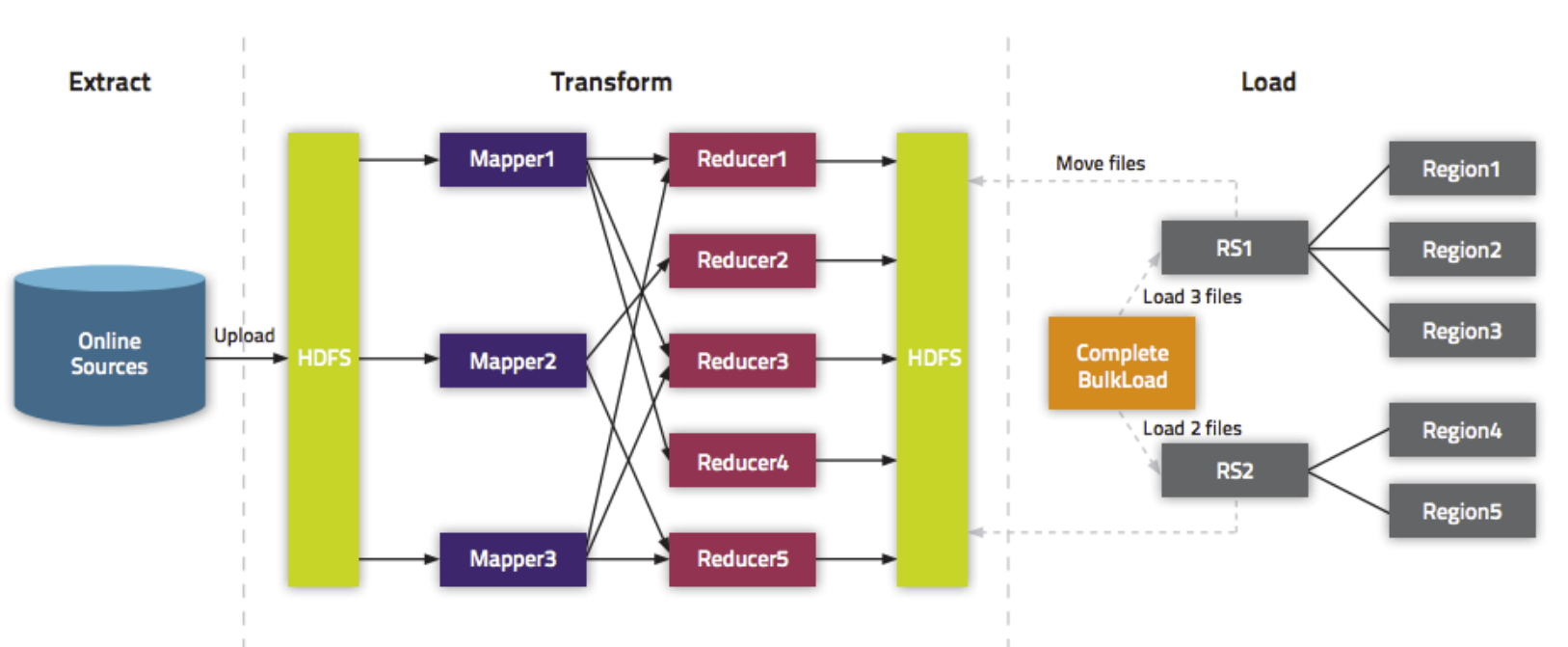
好处
(1).导入过程不占用Region资源
(2).能快速导入海量的数据
(3).节省内存
==1、开发生成HFile文件的代码==
package com.kaikeba; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class HBaseLoad { public static class LoadMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put> { @Override protected void map(LongWritable key, Text value, Mapper.Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); Put put = new Put(Bytes.toBytes(split[0])); put.addColumn("f1".getBytes(),"name".getBytes(),split[1].getBytes()); put.addColumn("f1".getBytes(),"age".getBytes(), split[2].getBytes()); context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])),put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { final String INPUT_PATH= "hdfs://node1:9000/input"; final String OUTPUT_PATH= "hdfs://node1:9000/output_HFile"; Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf("t4")); Job job= Job.getInstance(conf); job.setJarByClass(HBaseLoad.class); job.setMapperClass(LoadMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); //指定输出的类型HFileOutputFormat2 job.setOutputFormatClass(HFileOutputFormat2.class); HFileOutputFormat2.configureIncrementalLoad(job,table,connection.getRegionLocator(TableName.valueOf("t4"))); FileInputFormat.addInputPath(job,new Path(INPUT_PATH)); FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true)?0:1); } }
==2、打成jar包提交到集群中运行==
hadoop jar hbase_java_api-1.0-SNAPSHOT.jar com.kaikeba.HBaseLoad
==3、观察HDFS上输出的结果==
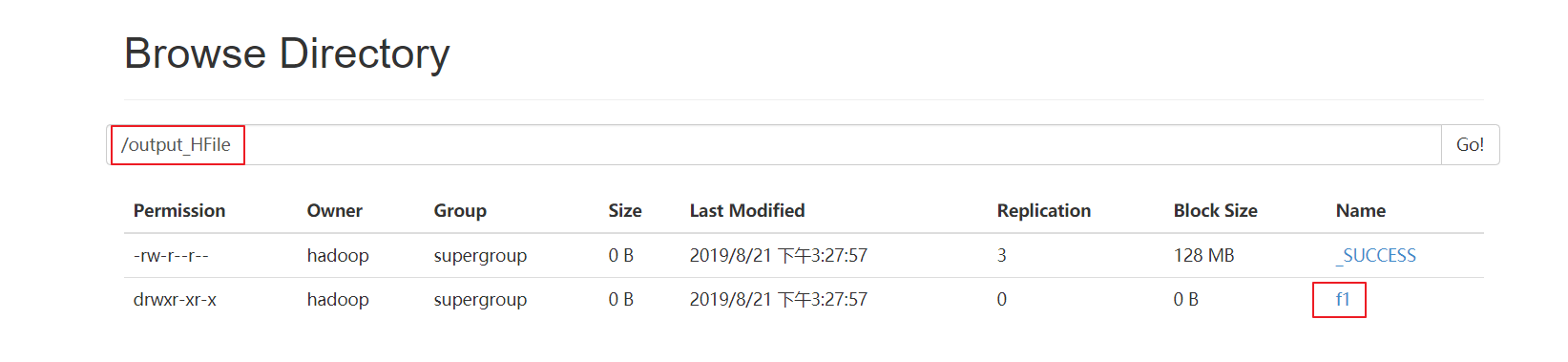
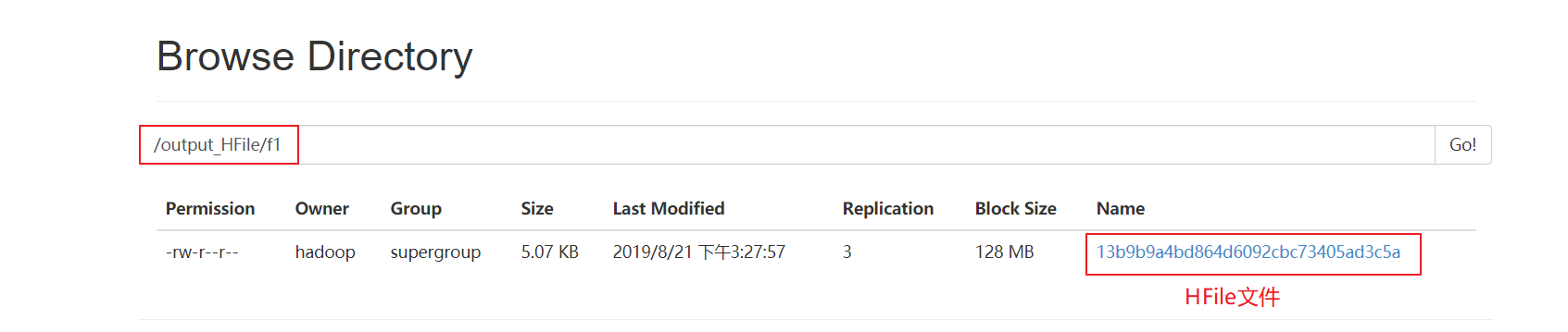
==4、加载HFile文件到hbase表中==
代码加载
package com.kaikeba; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles; public class LoadData { public static void main(String[] args) throws Exception { Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.quorum", "node1:2181,node2:2181,node3:2181"); //获取数据库连接 Connection connection = ConnectionFactory.createConnection(configuration); //获取表的管理器对象 Admin admin = connection.getAdmin(); //获取table对象 TableName tableName = TableName.valueOf("t4"); Table table = connection.getTable(tableName); //构建LoadIncrementalHFiles加载HFile文件 LoadIncrementalHFiles load = new LoadIncrementalHFiles(configuration); load.doBulkLoad(new Path("hdfs://node1:9000/output_HFile"), admin,table,connection.getRegionLocator(tableName)); } }
命令加载
命令格式
hadoop jar hbase-server-VERSION.jar completebulkload [-c /path/to/hbase/config/hbase-site.xml] /user/todd/myoutput mytable
先将hbase的jar包添加到hadoop的classpath路径下
export HBASE_HOME=/opt/bigdata/hbase
export HADOOP_HOME=/opt/bigdata/hadoop
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
命令加载演示
hadoop jar /opt/bigdata/hbase/lib/hbase-server-1.2.1.jar completebulkload /output_HFile t5