优化算法系列之模拟退火算法(1)——基本原理枯燥版本
推荐书籍-->《智能优化算法及其MATLAB实例(第二版)》
知乎上的形象描述:
一个锅底凹凸不平有很多坑的大锅,晃动这个锅使得一个小球使其达到全局最低点。一开始晃得比较厉害,小球的变化也就比较大,在趋于全局最低的时候慢慢减小晃锅的幅度,直到最后不晃锅,小球达到全局最低。
1.历史(不感兴趣可以跳过)
著名的模拟退火算法,它是一种基于蒙特卡洛思想设计的近似求解最优化问题的方法。
美国物理学家 N.Metropolis 和同仁在1953年发表研究复杂系统、计算其中能量分布的文章,他们使用蒙特卡罗模拟法计算多分子系统中分子的能量分布。这相当于是本文所探讨之问题的开始,事实上,模拟退火中常常被提到的一个名词就是Metropolis准则,后面我们还会介绍。
美国IBM公司物理学家 S.Kirkpatrick、C. D. Gelatt 和 M. P. Vecchi 于1983年在《Science》上发表了一篇颇具影响力的文章:《以模拟退火法进行最优化(Optimization by Simulated Annealing)》。他们借用了Metropolis等人的方法探讨一种旋转玻璃态系统(spin glass system)时,发觉其物理系统的能量和一些组合最优(combinatorial optimization)问题(著名的旅行推销员问题TSP即是一个代表例子)的成本函数相当类似:寻求最低成本即似寻求最低能量。由此,他们发展出以 Metropolis 方法为本的一套算法,并用其来解决组合问题等的寻求最优解。
几乎同时,欧洲物理学家 V.Carny 也发表了几乎相同的成果,但两者是各自独立发现的;只是Carny“运气不佳”,当时没什么人注意到他的大作;或许可以说,《Science》杂志行销全球,“曝光度”很高,素负盛名,而Carny却在另外一本发行量很小的专门学术期刊《J.Opt.Theory Appl.》发表其成果因而并未引起应有的关注。
Kirkpatrick等人受到Metropolis等人用蒙特卡罗模拟的启发而发明了“模拟退火”这个名词,因为它和物体退火过程相类似。寻找问题的最优解(最值)即类似寻找系统的最低能量。因此系统降温时,能量也逐渐下降,而同样意义地,问题的解也“下降”到最值。
固体退火:
1.先将固体加热至溶化然后徐徐冷却。
2.退火要徐徐进行使得系统在每一温度下都达到平衡。
3.冷却时不能急剧减温。
模拟退火算法:
1、从某个初始解i0出发,经过L次解的变换(每次根据Metropoils算法求解),求得在给定温度下的相对最优解。
2、减小控制参数T,重新变换解(如上)
3、求得在控制参数T趋于0时的最优解
2.什么是退火——物理上的由来
在热力学上,退火(annealing)现象指物体逐渐降温的物理现象,温度愈低,物体的能量状态会低;够低后,液体开始冷凝与结晶,在结晶状态时,系统的能量状态最低。大自然在缓慢降温(亦即,退火)时,可“找到”最低能量状态:结晶。但是,如果过程过急过快,快速降温(亦称「淬炼」,quenching)时,会导致不是最低能态的非晶形。
如下图所示,首先(左图)物体处于非晶体状态。我们将固体加温至充分高(中图),再让其徐徐冷却,也就退火(右图)。加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小(此时物体以晶体形态呈现)。
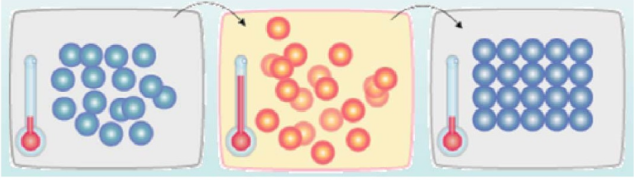
似乎,大自然知道慢工出细活:缓缓降温,使得物体分子在每一温度时,能够有足够时间找到安顿位置,则逐渐地,到最后可得到最低能态,系统最安稳。
3.Metropolis(蒙特卡洛)准则
1953年Metropolis提出了这样一个重要性采样的方法,即设从当前状态i生成新状态j,若新状态的内能小于状态i的内能即(Ej<Ei),则接受新状态j作为新的当前状态;否则,以概率 exp[-(Ej-Ei)/kT] 接受状态j,其中k为Boltzmann常数,这就是通常所说的Metropolis准则。
根据Metropolis(蒙特卡洛)准则,粒子在温度T时趋于平衡的概率为exp(-ΔE/(kT)),其中E为温度T时的内能,ΔE为其改变数,k为Boltzmann常数。Metropolis准则常表示为
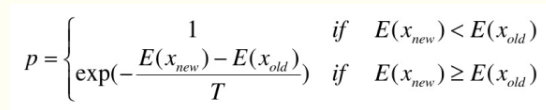
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
根据热力学的原理,在温度为T时,出现能量差为dE的降温的概率为p(dE),表示为:
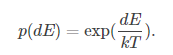
其中: k是波尔兹曼常数,值为k=1.3806488(13)×10−23,
exp表示自然指数,
dE<0
dE/kT<0
p(dE)函数的取值范围是(0,1)。
满足概率密度函数的定义。
其实这条公式更直观意思就是:温度越高,出现一次能量差为p(dE)的降温的概率就越大;温度越低,则出现降温的概率就越小。
在实际问题中,这里的“一定的概率”的计算参考了金属冶炼的退火过程。假定当前可行解为x,迭代更新后的解为x_new,那么对应的“能量差”定义为:
Δf=f(x_new)−f(x).
其对应的“一定概率”为:
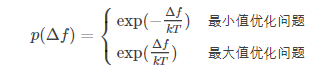
注:在实际问题中,可以设定k=1。因为kT可以等价于一个参数 T。如设定k=2、T=1000,等于直接设定T=2000的效果。
4.引入模拟退火(Simulate Anneal)
想象一下如果我们现在有下面这样一个函数,现在想求函数的(全局)最优解。如果采用Greedy策略,那么从A点开始试探,如果函数值继续减少,那么试探过程就会继续。而当到达点B时,显然我们的探求过程就结束了(因为无论朝哪个方向努力,结果只会越来越大)。最终我们只能找打一个局部最后解B。
模拟退火其实也是一种Greedy贪心算法,但是它的搜索过程引入了随机因素。在迭代更新可行解时,以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。以下图为例,假定初始解为左边蓝色点A,模拟退火算法会快速搜索到局部最优解B,但在搜索到局部最优解后,不是就此结束,而是会以一定的概率接受到左边的移动。也许经过几次这样的不是局部最优的移动后会到达全局最优点D,于是就跳出了局部最小值。
有趣的比喻
爬山算法:兔子朝着比现在高的地方跳去。它找到了不远处的最高山峰。但是这座山不一定是珠穆朗玛峰。这就是爬山算法,它不能保证局部最优值就是全局最优值。
(非常懒,一开始看到比现在高的就接受)
模拟退火:兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向高处,也可能踏入平地。但是,它渐渐清醒了并朝最高方向跳去。这就是模拟退火。
(一开始很激动,到处试探,变化大。后面心累了,逐渐减缓了步伐,朝向此时此刻的最高点爬去) 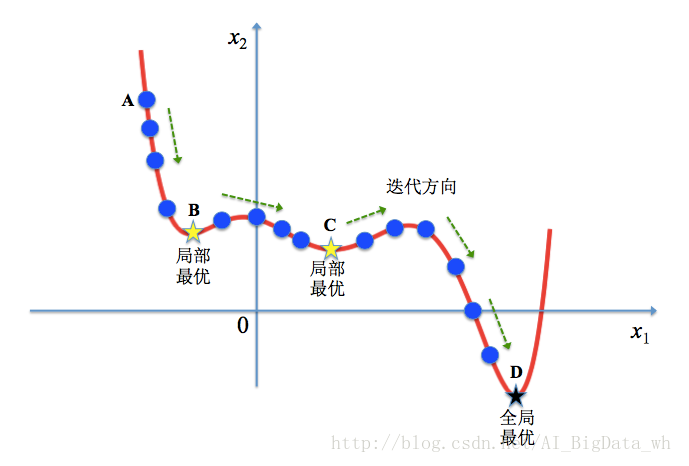
5.模拟退火原理
模拟退火算法(Simulate Anneal Arithmetic,SAA)是一种通用概率演算法,用来在一个大的搜寻空间内找寻命题的最优解。
模拟退火的原理也和金属退火的原理近似:将热力学的理论套用到统计学上,将搜寻空间内每一点想像成空气内的分子;分子的能量,就是它本身的动能;而搜寻空间内的每一点,也像空气分子一样带有“能量”,以表示该点对命题的合适程度。演算法先以搜寻空间内一个任意点作起始:每一步先选择一个“邻居”,然后再计算从现有位置到达“邻居”的概率。
6.模拟退火算法模型
模拟退火算法可以分解为解空间、目标函数和初始解三部分。
-
- 模拟退火的基本思想:
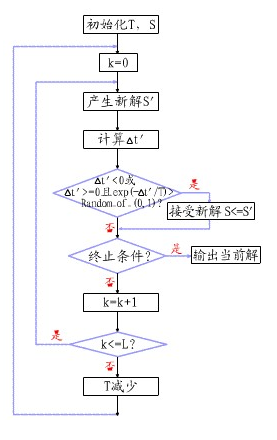
- (1) 初始化:初始温度T(充分大),初始解状态S(是算法迭代的起点), 每个T值的迭代次数L
- (2) 对k=1,……,L做第(3)至第6步:
- (3) 产生新解S′
- (4) 计算增量Δt′=C(S′)-C(S),其中C(S)为评价函数||优化目标
- (5) 若Δt′<0则接受S′作为新的当前解,否则以概率exp(-Δt′/T)接受S′作为新的当前解.
- (6) 如果满足终止条件则输出当前解作为最优解,结束程序。终止条件通常取为连续若干个新解都没有被接受时终止算法。
- (7) T逐渐减少,且T->0,然后转第2步。
- 模拟退火的基本思想:
算法对应动态演示图:
-
- 模拟退火算法新解的产生和接受可分为如下四个步骤:
- 第一步是由一个产生函数从当前解产生一个位于解空间的新解;为便于后续的计算和接受,减少算法耗时,通常选择由当前新解经过简单地变换即可产生新解的方法,如对构成新解的全部或部分元素进行置换、互换等,注意到产生新解的变换方法决定了当前新解的邻域结构,因而对冷却进度表的选取有一定的影响。
- 第二步是计算与新解所对应的目标函数差。因为目标函数差仅由变换部分产生,所以目标函数差的计算最好按增量计算。事实表明,对大多数应用而言,这是计算目标函数差的最快方法。
- 第三步是判断新解是否被接受,判断的依据是一个接受准则,最常用的接受准则是Metropolis准则: 若Δt′<0则接受S′作为新的当前解S,否则以概率exp(-Δt′/T)接受S′作为新的当前解S。
- 第四步是当新解被确定接受时,用新解代替当前解,这只需将当前解中对应于产生新解时的变换部分予以实现,同时修正目标函数值即可。此时,当前解实现了一次迭代。可在此基础上开始下一轮试验。而当新解被判定为舍弃时,则在原当前解的基础上继续下一轮试验。
- 模拟退火算法新解的产生和接受可分为如下四个步骤:
模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率l 收敛于全局最优解的全局优化算法;模拟退火算法具有并行性。
7.模拟退火基本要素
2)状态产生函数(邻域函数)应尽可能保证产生的候选解遍布全部解空间。通常由两部分组成,即产生候选解的方式和候选解产生的概率分布。
3)候选解一般采用按照某一概率密度函数对解空间进行随机采样来获得。
4)概率分布可以是均匀分布、正态分布、指数分布等。
2)通俗的理解是接受一个新解为当前解的概率。
3)它与当前的温度参数T有关,随温度下降而减小。
4)一般采用Metropolis准则。
2)连续若干步的目标值变化较小。
3)按一定的步数抽样。
2)设置外循环迭代次数。
3)算法搜索到的最优值连续若干步保持不变。
4)检验系统熵是否稳定。
8.参数说明
退火过程由一组初始参数,即冷却进度表控制,它的核心是尽量使系统达到转平衡,以使算法在有限的时间内逼近最优解。冷却进度表包括:
(1)控制参数的初值T0:冷却开始的温度。
(2)控制参数T的衰减函数:因计算机能够处理的都是离散数据,因此把连续的降温过程离散化成降温过程中的一系列温度点,衰减函数即计算这一系列温度的表达式。
(3)控制参数T的终值Tf (停止准则)。
(4)Markov链的长度Lk:任一温度T 的迭代次数。
9.参数设置
模拟退火算法的应用很广泛,可以求解NP完全问题,但其参数难以控制,其主要问题有以下三点:
(1)控制参数T的初值T0
求解全局优化问题的随机搜索算法一般都采用大范围的粗略搜索与局部的精细搜索相结合的搜索策略。
只有在初始的大范围搜索阶段找到全局最优解所在的区域,才能逐步缩小搜索的范围,最终求出全局最优解。
模拟退火算法是通过控制参数T的初值T0和气衰减变化过程来实现大范围的粗略搜索与局部的精细搜索。
在问题规模较大时,过小的T0往往导致算法难以跳出局部陷阱而达不到全局最优。一般为100℃。
【初始温度高,则搜索到全局最优解的可能性大,但因此要花费大量的计算时间;反之,则可节约计算时间,但全局搜索性能可能受到影响。实际应用过程中,初始温度一般需要依据实验结果进行若干次调整。】
(2)控制参数 T 的衰减函数
衰减函数可以有多种形式,一个常用的衰减函数是


其中,k为降温的次数,α 是一个常数,可以取为0.5~0.99,它的取值决定了降温过程的快慢。
【为了保证较大的搜索空间,a一般取接近于1的值,如0.95、0.9】
(3)退火速度:Markov链长度
Markov链长度的选取原则是:在控制参数T的衰减函数已经选定的前提下,Lk应能使在控制参数T的每一取值上达到准平衡。
从经验上说,对简单的情况可以令Lk=100n,n为问题规模。
【循环次数增加必定带来计算开销的增大,实际应用中,要针对具体问题的性质和特征设置合理的退火平衡条件。】
(4)控制参数T的终值Tf (停止准则)。或者若干个相继的Mapkob链解没有产生变化,就是连续好多个解都没变化。
算法停止准则:对Metropolis准则中的接受函数
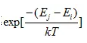
分析可知,在T比较大的高温情况,指数上的分母比较大,而这是一个负指数,所以整个接受函数可能会趋于1,即比当前解 xi 更差的新解 xj 也可能被接受因此就有可能跳出局部极小而进行广域搜索,去搜索解空间的其他区域;而随着冷却的进行,T减小到一个比较小的值时,接收函数分母小了整体也小了,即难于接受比当前解更差的解,也就不太容易跳出当前的区域。如果在高温时,已经进行了充分的广域搜索,找到了可能存在的最好解的区域,而在低温再进行足够的局部搜索,则可能最终找到全局最优了。因此,一般终止温度 Tj 应设为足够小的正数,比如0.01~5。
【一般终止温度 Tj 应设为足够小的正数,比如0.01~5。】
10.优缺点及改进
模拟退火算法(simulated annealing,SA)是一种通用概率算法,用来在一个大的搜寻空间内寻找问题的最优解。
优点:能够有效解决NP难问题、避免陷入局部最优解。
计算过程简单,通用,鲁棒性强,适用于并行处理,可用于求解复杂的非线性优化问题。
模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;
模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率收敛于全局最优解的全局优化算法;
模拟退火算法具有并行性
缺点:收敛速度慢,执行时间长,算法性能与初始值有关及参数敏感等缺点。
由于要求较高的初始温度、较慢的降温速率、较低的终止温度,以及各温度下足够多次的抽样,因此优化过程较长。
(1)如果降温过程足够缓慢,多得到的解的性能会比较好,但与此相对的是收敛速度太慢;
(2)如果降温过程过快,很可能得不到全局最优解。
适用环境:组合优化问题。
改进:
(1)设计合适的状态产生函数,使其根据搜索进程的需要表现出状态的全空间分散性或局部区域性。
(2)设计高效的退火策略。
(3)避免状态的迂回搜索。
(4)采用并行搜索结构。
(5)为避免陷入局部极小,改进对温度的控制方式。
(6)选择合适的初始状态。
(7)设计合适的算法终止准则。
-------------------------------------------------------------------------------------------------------------------------------
(8)增加升温或重升温过程。在算法进程的适当时机,将温度适当提高,从而可激活各状态的接受概率,以调整搜索进程中的当前状态,避免算法在局部极小解处停滞不前。
(9)增加记忆功能。为避免搜索过程中由于执行概率接受环节而遗失当前遇到的最优解,可通过增加存储环节,将一些在这之前好的态记忆下来。
(10)增加补充搜索过程。即在退火过程结束后,以搜索到的最优解为初始状态,再次执行模拟退火过程或局部性搜索。
(11)对每一当前状态,采用多次搜索策略,以概率接受区域内的最优状态,而非标准SA的单次比较方式。
(12)结合其他搜索机制的算法,如遗传算法、混沌搜索等。
(13)上述各方法的综合应用。
11.总结
以爬山算法为代表的局部搜索算法仅仅适用于某类组合优化问题并且解的质量也不是很理想。于是为了克服这些缺点,人们通过一些自然物理过程寻找解决办法模拟退火算法源于对固体的退火过程的模拟,通过采用Metropolis接受准则,并用一组称为冷却表的参数控制算法进程,使得我们可以在多项式时间内求出一个近似最优解。
模拟退火算法(simulated annealing,SA)是一种通用概率算法,用来在一个大的搜寻空间内寻找问题的最优解。由于它能够有效解决NP难问题、避免陷入局部最优解等优点,已经在生产调度、控制工程、机器学习、神经网络、图像处理等领域获得了广泛应用。
12.摘录网站
1. https://mp.weixin.qq.com/s?__biz=MzI5OTU4NTMwNQ==&mid=2247483792&idx=1&sn=c92c179896cecc45c8efc614863e2bf9&chksm=ec951be6dbe292f0027ddc877ecd3f910df724d9b6be336e0f5b07b70c9cb55920518994ed7b&scene=21#wechat_redirect
3. https://blog.csdn.net/AI_BigData_wh/article/details/77943787?locationNum=2&fps=1
4.https://www.cnblogs.com/GuoJiaSheng/p/4192301.html
5.https://wiki.mbalib.com/wiki/%E6%A8%A1%E6%8B%9F%E9%80%80%E7%81%AB%E7%AE%97%E6%B3%95