tbody问题:
在爬去某些网站一些信息的时候,xpath工具上显示类容是正确的,但是在scrapy代码中一直返回空列表
Scrapy的部分代码:
class LotteryspiderSpider(scrapy.Spider):
#爬虫名字
name = 'LotterySpider'
#允许的域名
allowed_domains = ['www.lottery.gov.cn']
#入口URL,扔到调度器
start_urls = ['http://www.lottery.gov.cn']
def parse(self, response):
print(response.text)
lottery_list = response.xpath('//div[@class="b11_06"]//tbody')
网页上显示:
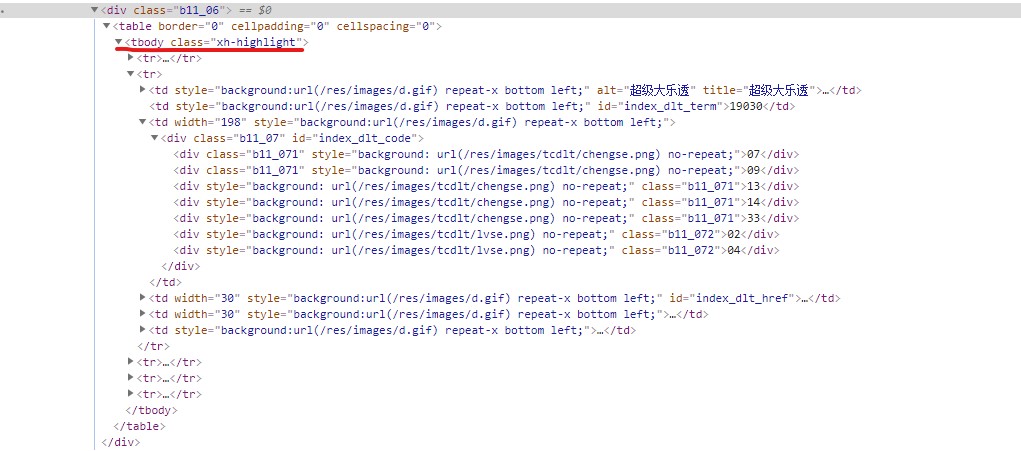
爬到本地全部类容中 //div[@class="b11_06"]少了tbody
<div class="b11_06"> <table border="0" cellpadding="0" cellspacing="0"> <tr><td width="45" style="background:#ECECEC; line-height:30px; height:24px;">玩法</td>
经查询得知原因是:浏览器会对html文本进行一定的规范化,所以会自动在路径中加入tbody,导致读取失败,在此处直接在路径中去除tbody即可。