好久不见了,今天给大家整点福利!

先上一个截图镇镇场子!

兄弟们学Python如果不是为了爬小姐姐,那将毫无意义!
而且爬图片有什么意思,咱们要爬就爬视频,话不多说,开整!
1、动态数据抓包演示
2、json数据解析方法
3、视频数据保存这是今天的大概方法,给大家介绍一下爬虫项目抓取的一般策略(步骤)
1、找数据对应的地址<链接地址>
2、发送地址请求
3、数据提取(解析)<提取想要的数据>
4、数据保存页面加载形式
ajax异步加载技术(前端技术)
在不需要加载整个页面的情况下, 对页面实现局部刷新代码不多,其实挺简单。
用到的模块
import requests # 数据请求模块, 第三方模块
import pprint # 格式化输出模块
import re # 正则表达式模块, 匹配查询, 替换字符串,匹配非法字符, 替换
def change_title(title): pattern = re.compile('[\/:*?"<>|]') new_title = re.sub(pattern, '_', title) return new_title
f 正在抓取第{page}页数据
for page in range(2, 11): print
1、找数据对应的地址<链接地址>
1 url = f'https://v.6.cn/minivideo/getMiniVideoList.php?act=recommend&page={page}&pagesize=30'
浏览器的身份标识 host 域名 referer 防盗链<标识你是哪里来的> origin 资源的起始地址 cookies 用户身份标识。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
2、发送地址请求
response = requests.get(url=url, headers=headers)
json_data = response.json()
3、数据提取(解析)<提取想要的数据>
data_list = json_data['content']['list'] for data in data_list: video_title = data['title'] + '.mp4' # 视频的标题(文明名) 尾缀 avi rmvb flv video_url = data['playurl'] # 视频的地址 # print(video_title, video_url)
请求视频地址数据 视频 图片 音频 都是二进制
1 print('正在下载:', video_title) 2 video_data = requests.get(url=video_url, headers=headers).content # 视频数据 3 4 new_title = change_title(video_title)
4、数据保存
1 with open('video\' + new_title, mode='wb') as f: 2 f.write(video_data) 3 print('下载完成:', video_title + ' ')
好了,是真的简单,就这几行代码,模块没安装的话,先把模块安装一下。
安装方法:win+r 打开运行框,输入cmd 打开命令提示符窗口,pip install ***(***改成你要安装的的模块名)
最后给你们看下我的硬盘装满了没有,免得说我欺骗感情,我爬的都是正经的小姐姐,不要骂我,不正经的咱也过不了审,建议各位也不要爬不正经的,身体要紧!
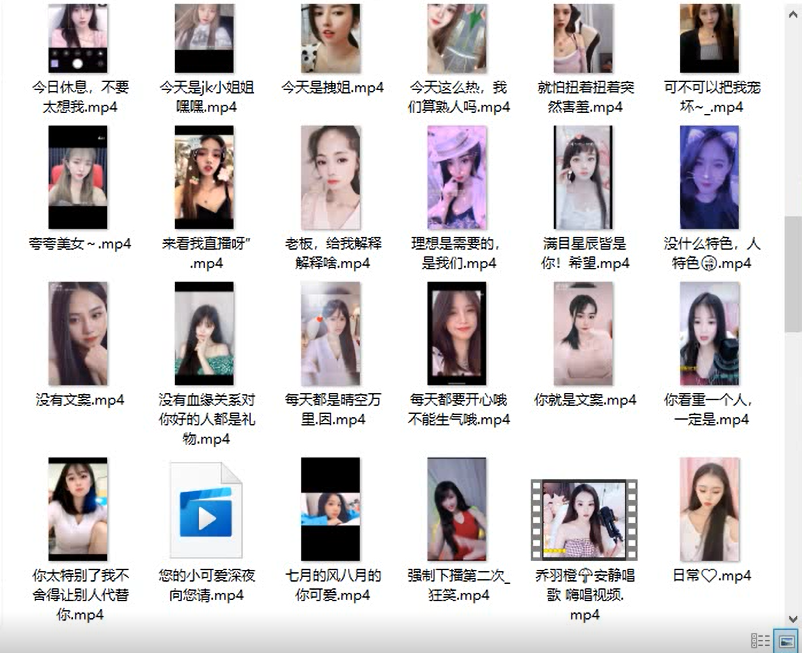
记得点赞关注,不然下次我都没动力更新这种福利了~
