作为运维工程师,我们每天需要对服务器进行故障排除,那么最先能帮助我们定位问题的就是查看服务器日志,通过日志可以快速的定位问题。
目前我们说的日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常需要分析日志可以了解服务器的负荷。性能安全性,从而及时采取措施纠正错误。而且日志被分散的存储在不同的设备上
(每台服务器创建开发普通用户权限,只运行查看日志、查看进程,运维、开发通过命令tail、head、cat、more、find、awk、grep、sed统计分析)
如果你管理数上百台服务器,我们登录到每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理系统,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用find、grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
今天给大家分享的开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kibana三个开源工具组成,不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少。
适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。
1) Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等,ELK官网:https://www.elastic.co/
2) Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。工作方式为C/S架构,Client端安装在需要收集日志的主机上,Server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch服务器。
3) Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志;
4) FileBeat是一个轻量级日志采集器,Filebeat属于Beats家族的6个成员之一,早期的ELK架构中使用Logstash收集、解析日志并且过滤日志,但是Logstash对CPU、内存、IO等资源消耗比较高,相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计;
5) Logstash和Elasticsearch是用Java语言编写,而Kibana使用node.js框架,在配置ELK环境要保证系统有JAVA JDK开发库;
1、 ELK架构原理深入剖析
1) ELK工作流程;
客户端安装Logstash日志收集工具,通过logstash收集客户端APP的日志数据,将所有的日志过滤出来,存入Elasticsearch 搜索引擎里,然后通过Kibana GUI在WEB前端展示给用户,用户需要可以进行查看指定的日志内容。同时也可以加入redis通信队列:
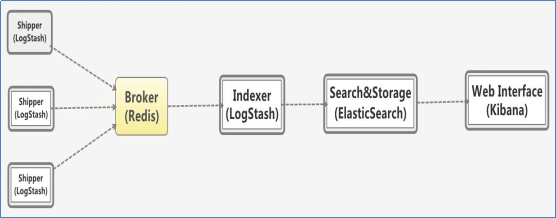
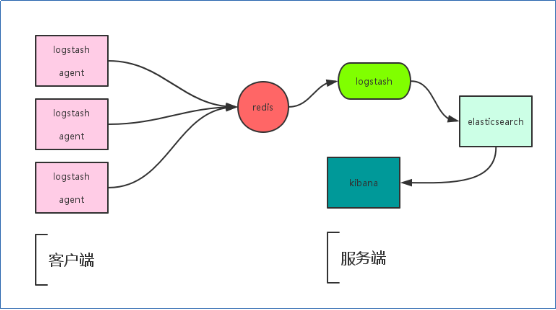
1) 加入Redis队列后工作流程;
Logstash包含Index和Agent(shipper) ,Agent负责客户端监控和过滤日志,而Index负责收集日志并将日志交给ElasticSearch,ElasticSearch将日志存储本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息。
2) ELFK工作流程;
使用FileBeat获取Linux服务器上的日志。当启动Filebeat时,它将启动一个或多个Prospectors (检测者),查找服务器上指定的日志文件,作为日志的源头等待输出到Logstash。
Logstash从FileBeat获取日志文件。Filebeat作为Logstash的输入input将获取到的日志进行处理,Logstash将处理好的日志文件输出到Elasticsearch进行处理。
Elasticsearch得到Logstash的数据之后进行相应的搜索存储操作。将写入的数据可以被检索和聚合等以便于搜索操作,最后Kibana通过Elasticsearch提供的API将日志信息可视化的操作。