视频:
https://www.bilibili.com/video/BV1x54y1B7RE?from=search&seid=10948197841954912425
比较好的博客:
https://juejin.cn/post/6844903569200513037
https://juejin.cn/post/6844904007526252558
名词解释:
https://www.cnblogs.com/caiyy/p/10406934.html
js解释:
https://juejin.cn/post/6844904190993514503
核心流程:
1 浏览器进程 (1 网络线程 2 UI线程(创建渲染器进程(1主线程: dom树。css 树(样式)。-》 layout布局。 绘制表。layer treee。 ))2 合成器线程 (合成器帧)3 栅格线程(制造帧))
用户层
浏览器引擎。 数据持久层(cookies)。
渲染引擎。 网络,js解析器。
进程 和 线程。
进程(映射到内存空间),进程(映射到内存空间)。
进程间IPC管道通信。
之前浏览器是单进程,1 不稳定。2 不安全。3 不流程。
所以需要多进程,
- 1 浏览器进程: 负责标签控制。(地址栏,书签,前进后退)
- 2 网络进程: 发送,接受请求
- 3 缓存进程。
- 4 渲染器进程:(HTML所有的标签内容)
- 5 GPU进程:渲染。
- 6 插件进程(flash)
浏览器进程 的UI线程 如果是 请求网络进程。
1 网址:DNS进行域名解析。服务器数据。
2 关键字: 默认配置搜索引擎来查询。
safebrowsing。
UI线程。
渲染器继承。 html -dom数据结果。
html->tokenis 词法分析 ->Tree dom树构造。->dom
html引入:图片和css。网络下载和图片加载。
不会阻塞html解析。因为不会影响dom的生产。
当时当遇到JS,则会停止解析,加载执行js去。
document.wierter();->tokenins.
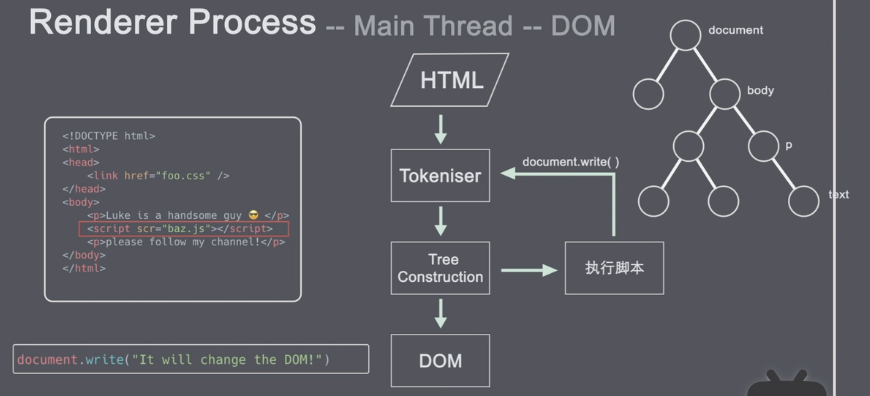
1 script标签放在合适的位置 2 asycn放在合适的位置。
h2 默认字体。
节点的坐标 以及节点占用多大面积。
Layout树。记录了x,y坐标和边框尺寸大小,
layout tree;
1 添加了 display:none 不会出现在layout tree上面
2 但是 添加了 div::before{content:“obj”}则只会在layout tree。
正确的 层级: 绘制表。绘制顺序。
像素点。 栅格化。 可视区的内容。延迟展示。
复杂的栅格化方式:合成。
Layer Tree。
合成器线程。
存储在GPU, 合成器镇。
主线桥 -> DOM->
合成器线程
栅格进程-》
重排:
颜色属性,重绘。
transform布局不会进行 重排和重绘(位置变换和宽高变换)。
为什么要大量的避免重绘和重排: