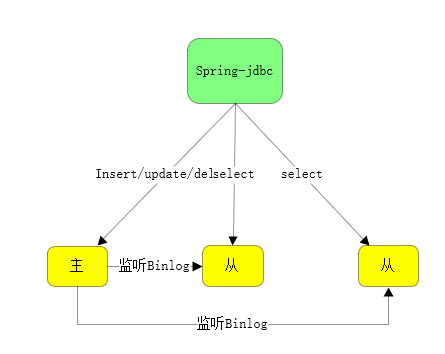
在本文中使用Spring Boot 2.4.1+MyBatis+Druid+Sharding-JDBC+MySQL进行读写分离的案件讲解。
1、数据库准备
1、192.168.8.162 test1主
2、192.168.8.134 test1从
3、192.168.8.176 test1从
2、上代码
1、pom.xml配置引入maven依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--springboot整合mybatis的依赖 --> <!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter --> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.4</version> </dependency> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>3.1.0.M1</version> </dependency>
2、在application.yml中配置使用mybatis及引用数据源
server.port: 8080 mybatis.config-location: classpath:META-INF/mybatis-config.xml spring: main: allow-bean-definition-overriding: true sharding: jdbc: dataSource: names: dbtest0,dbtest1,dbtest2 # 配置主库 dbtest0: #org.apache.tomcat.jdbc.pool.DataSource type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.8.162:3306/test1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: root #最大连接数 maxPoolSize: 20 dbtest1: # 配置第一个从库 type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.8.134:3306/test1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT username: root password: root maxPoolSize: 20 dbtest2: # 配置第二个从库 type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.8.176:3306/test1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT username: root password: root maxPoolSize: 20 config: masterslave: # 配置读写分离 name: ds_ms load-balance-algorithm-type: round-robin # 配置从库选择策略,提供轮询与随机,这里选择用轮询//random 随机 //round_robin 轮询 master-data-source-name: dbtest0 slave-data-source-names: dbtest1,dbtest2 props: sql: # 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志!!! show: true
sharding.jdbc.dataSource.names配置的是数据库的名称,就是多个数据源的名称。
sharding.jdbc.dataSource配置多个数据源。需要配置数据库名称,和上面配置的对应。以及数据的配置,包括连接池的类型、连接器、数据库地址、
数据库账户密码信息等。
sharding.jdbc.config.masterslave.load-balance-algorithm-type查询时的负载均衡算法,目前有2种算法,round_robin(轮询)和random(随机)。
sharding.jdbc.config.masterslave.master-data-source-name主数据源名称。
sharding.jdbc.config.masterslave.slave-data-source-names从数据源名称,多个用逗号隔开。
3、mybatis操作数据库配置
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <typeAliases> <package name="com.example.shardingjdbc.entity"/> </typeAliases> <mappers> <mapper resource="META-INF/mappers/User.xml"/> </mappers> </configuration>
User.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.shardingjdbc.mapper.UserMapper"> <resultMap id="baseResultMap" type="com.example.shardingjdbc.entity.User"> <result column="id" property="id" jdbcType="INTEGER" /> <result column="name" property="name" jdbcType="VARCHAR" /> <result column="sex" property="sex" jdbcType="VARCHAR" /> </resultMap> <insert id="addUser"> INSERT INTO t_user ( id, name, sex ) VALUES ( #{id,jdbcType=INTEGER}, #{name,jdbcType=VARCHAR}, #{sex,jdbcType=VARCHAR} ) </insert> <select id="list" resultMap="baseResultMap"> SELECT u.* FROM t_user u </select> </mapper>
实体类
package com.example.shardingjdbc.entity; import java.io.Serializable; public class User implements Serializable { private static final long serialVersionUID = -1205226416664488559L; private Integer id; private String name; private String sex; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public static long getSerialversionuid() { return serialVersionUID; } }
mapper层
package com.example.shardingjdbc.mapper; import java.util.List; import org.apache.ibatis.annotations.Mapper; import com.example.shardingjdbc.entity.User; @Mapper public interface UserMapper { Long addUser(User user); List<User> list(); }
service层
package com.example.shardingjdbc.service.impl; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import com.example.shardingjdbc.entity.User; import com.example.shardingjdbc.mapper.UserMapper; import com.example.shardingjdbc.service.UserService; @Service public class UserServiceImpl implements UserService { @Autowired private UserMapper userMapper; @Override public Long addUser(User user) { return userMapper.addUser(user); } @Override public List<User> list() { return userMapper.list(); } }
controller层
package com.example.shardingjdbc.controller; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import com.example.shardingjdbc.entity.User; import com.example.shardingjdbc.service.UserService; @RestController public class UserController { @Autowired private UserService userService; @GetMapping("/users") public Object list() { return userService.list(); } @GetMapping("/add") public Object add(@RequestParam Integer id,@RequestParam String name,@RequestParam String sex) { User user = new User(); user.setId(id); user.setName(name); user.setSex(sex); return userService.addUser(user); } }
完成。用Sharding-JDBC实现了数据库的读写分离,对192.168.8.162 test1中t_user的操作,对92.168.8.134 test1,92.168.8.134 test1中t_user的查询。
读写分离的好处就是在并发量比较大的情况下,将查询数据库的压力分担到多个从库中,能够满足高并发的要求。如下图