全文搜索介绍
全文搜索两个最重要的方面是:
- 相关性(Relevance) 它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这 种计算方式可以是 TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法。
- 分词(Analysis) 它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了创建倒排索引以及 查询倒排索引。
数据准备
本例使用ES版本为7.6.1
1、创建索引
1 PUT /user 2 3 { 4 "settings": { 5 "index": { 6 "number_of_shards": "1", 7 "number_of_replicas": "0" 8 } 9 }, 10 "mappings": { 11 "properties": { 12 "name": { 13 "type": "text" 14 }, 15 "age": { 16 "type": "integer" 17 }, 18 "mail": { 19 "type": "keyword" 20 }, 21 "hobby": { 22 "type": "text", 23 "analyzer": "ik_max_word" 24 } 25 } 26 } 27 }
2、插入数据
1 POST /user/_bulk 2 3 {"index":{"_index":"user"} 4 {"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"} 5 {"index":{"_index":"user"} 6 {"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"} 7 {"index":{"_index":"user"} 8 {"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"} 9 {"index":{"_index":"user"} 10 {"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、篮球"} 11 {"index":{"_index":"user"} 12 {"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影、羽毛球"}
3、效果如下:
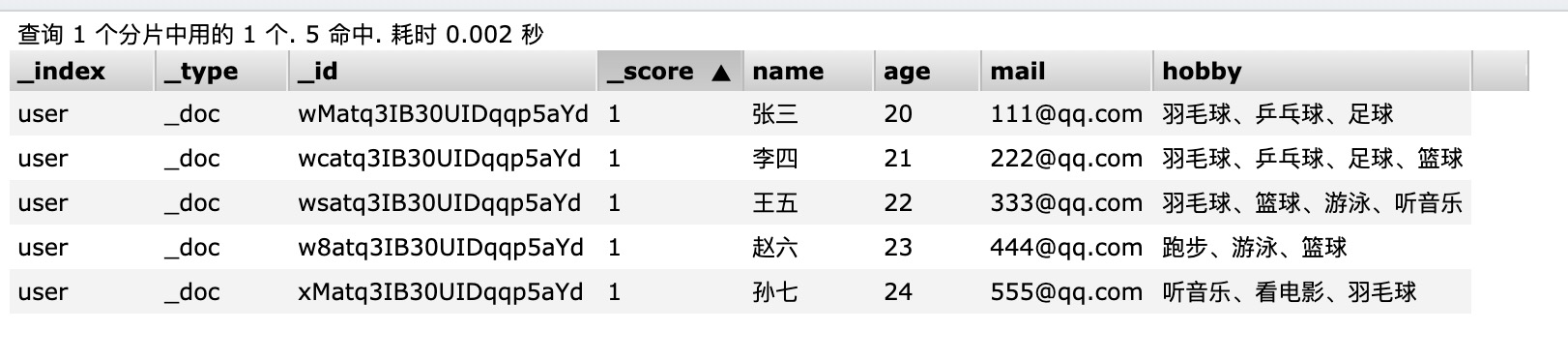
搜索
1、单词搜索
示例:
1 POST /user/_search 2 3 { 4 "query": { 5 "match": { 6 "hobby": "音乐" 7 } 8 }, 9 "highlight": { 10 "fields": { 11 "hobby": {} 12 } 13 } 14 }
效果如下:
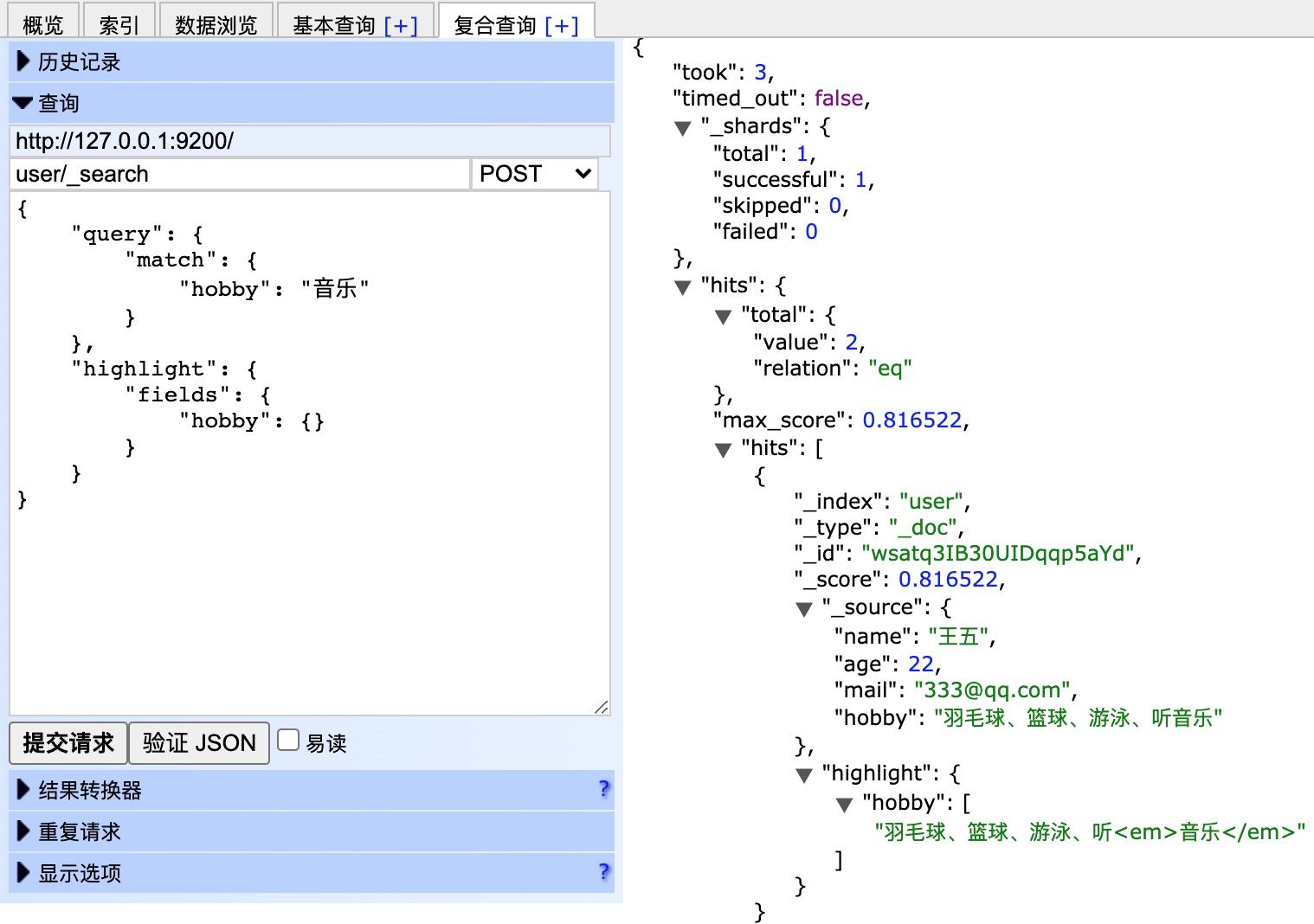
过程说明:
-
检查字段类型
爱好 hobby 字段是一个 text 类型( 指定了IK分词器),这意味着查询字符串本身也应该被分词。 -
分析查询字符串 。
将查询的字符串 “音乐” 传入IK分词器中,输出的结果是单个项 音乐。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。 -
查找匹配文档 。
用 term 查询在倒排索引中查找 “音乐” 然后获取一组包含该项的文档,本例的结果是文档:3 、5 。 -
为每个文档评分 。
用 term 查询计算每个文档相关度评分 _score ,这是种将 词频(term frequency,即词 “音乐” 在相关文档的 hobby 字段中出现的频率)和
反向文档频率(inverse document frequency,即词 “音乐” 在所有文档的 hobby 字段中出现的频率),
以及字段的长度(即字段越短相关度越高)相结合的计算方式。
2、多词搜索
示例:
1 POST /user/_search 2 3 { 4 "query": { 5 "match": { 6 "hobby": "音乐 篮球" 7 } 8 }, 9 "highlight": { 10 "fields": { 11 "hobby": {} 12 } 13 } 14 }
效果如下:
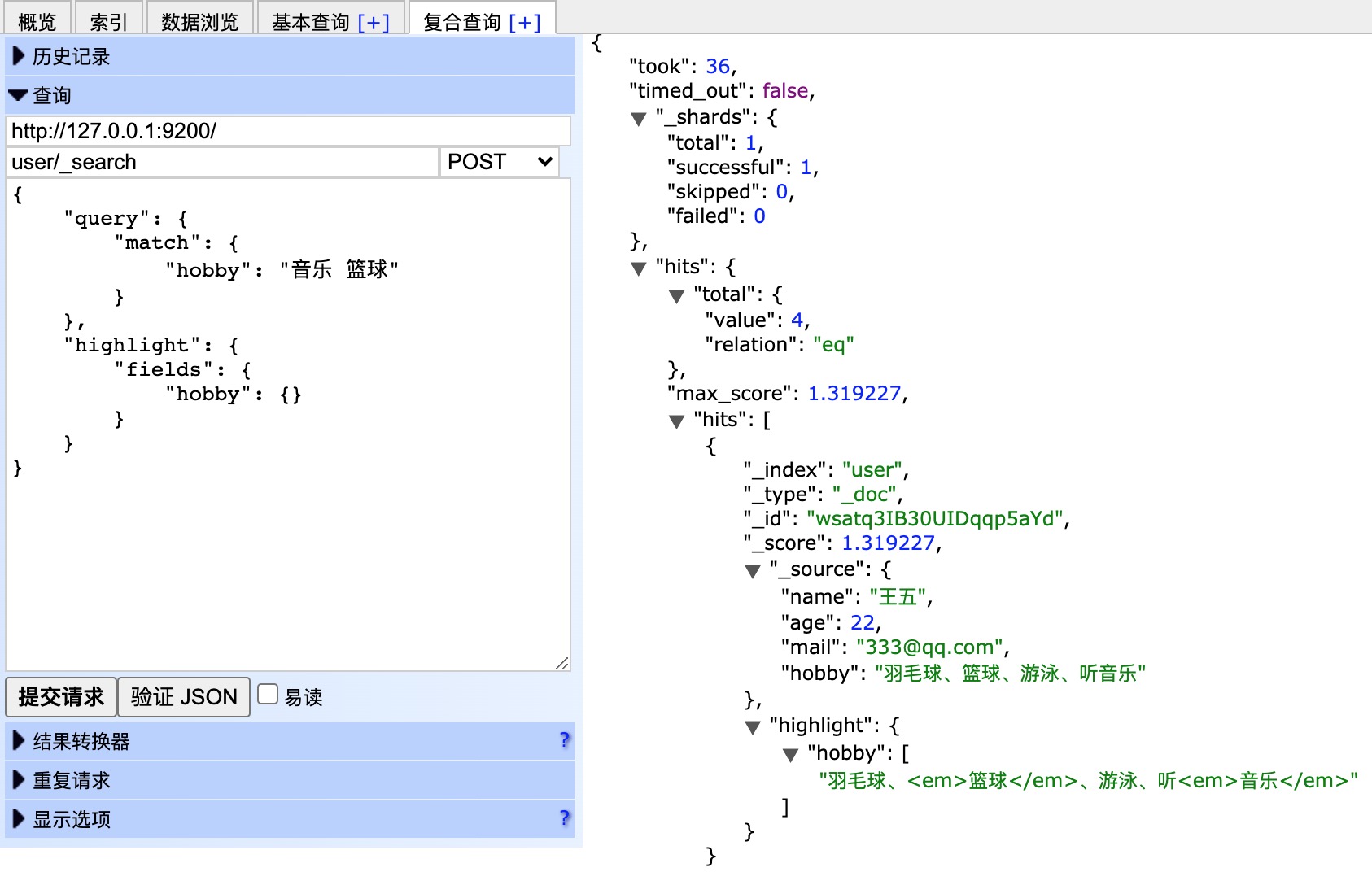
可以看到,包含了“音乐”、“篮球”的数据都已经被搜索到了。 可是,搜索的结果并不符合我们的预期,因为我们想搜索的是既包含“音乐”又包含“篮球”的用户,显然结果返回
的“或”的关系。
在Elasticsearch中,可以指定词之间的逻辑关系,如下:
and关系示例:
1 POST /user/_search 2 3 { 4 "query": { 5 "match": { 6 "hobby": { 7 "query": "音乐 篮球", 8 "operator": "and" 9 } 10 } 11 }, 12 "highlight": { 13 "fields": { 14 "hobby": {} 15 } 16 } 17 }
or关系示例:
1 POST /user/_search 2 3 { 4 "query": { 5 "match": { 6 "hobby": { 7 "query": "音乐 篮球", 8 "operator": "or" 9 } 10 } 11 }, 12 "highlight": { 13 "fields": { 14 "hobby": {} 15 } 16 } 17 }
前面我们测试了“OR” 和 “AND”搜索,这是两个极端,其实在实际场景中,并不会选取这2个极端,更有可能是选取这 种,或者说,只需要符合一定的相似度就可以查询到数据,在Elasticsearch中也支持这样的查询,通过 minimum_should_match来指定匹配度,如:70%;
minimum_should_match关系示例
1 POST /user/_search 2 3 { 4 "query": { 5 "match": { 6 "hobby": { 7 "query": "音乐 篮球", 8 "minimum_should_match": "80%" 9 } 10 } 11 }, 12 "highlight": { 13 "fields": { 14 "hobby": {} 15 } 16 } 17 }
相似度应该多少合适,需要在实际的需求中进行反复测试,才可得到合理的值。
3、组合搜索
在搜索时,也可以使用过滤器中讲过的bool组合查询,示例:
1 POST /user/_search 2 3 { 4 "query": { 5 "bool": { 6 "must": { 7 "match": { 8 "hobby": "篮球" 9 } 10 }, 11 "must_not": { 12 "match": { 13 "hobby": "音乐" 14 } 15 }, 16 "should": [ 17 { 18 "match": { 19 "hobby": "游泳" 20 } 21 } 22 ] 23 } 24 }, 25 "highlight": { 26 "fields": { 27 "hobby": {} 28 } 29 } 30 }
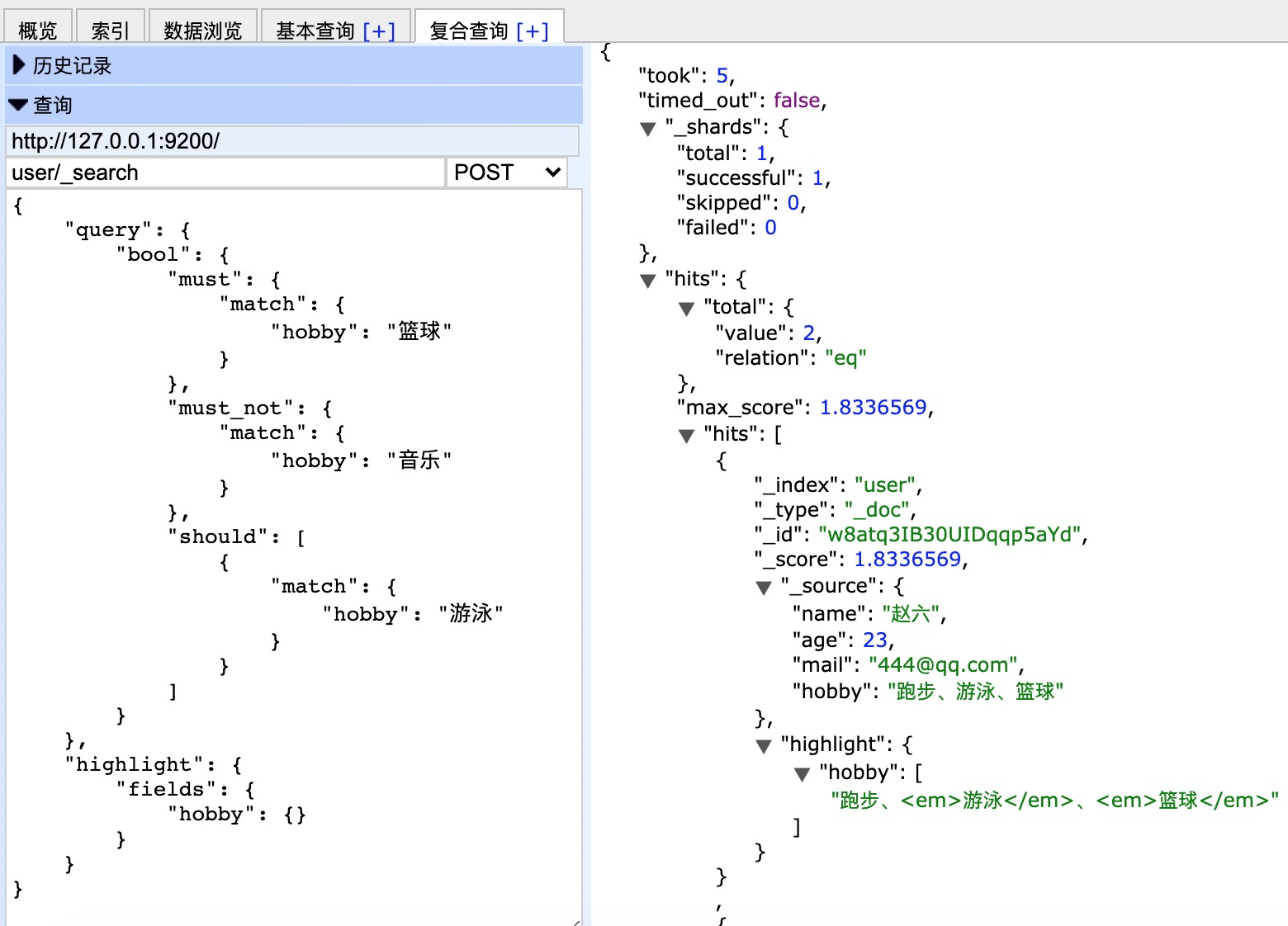
上面搜索的意思是:
搜索结果中必须包含篮球,不能包含音乐,如果包含了游泳,那么它的相似度更高。
效果如下:
评分的计算规则
bool 查询会为每个文档计算相关度评分 _score , 再将所有匹配的 must 和 should 语句的分数 _score 求和,最后除以 must 和 should 语句的总数。
must_not 语句不会影响评分; 它的作用只是将不相关的文档排除。
默认情况下,should中的内容不是必须匹配的,如果查询语句中没有must,那么就会至少匹配其中一个。
当然了, 也可以通过minimum_should_match参数进行控制,该值可以是数字也可以的百分比。
4、权重
有些时候,我们可能需要对某些词增加权重来影响该条数据的得分。如下:
搜索关键字为“游泳篮球”,如果结果中包含了“音乐”权重为10,包含了“跑步”权重为2。
1 POST /user/_search 2 3 { 4 "query": { 5 "bool": { 6 "must": { 7 "match": { 8 "hobby": { 9 "query": "游泳篮球", 10 "operator": "and" 11 } 12 } 13 }, 14 "should": [ 15 { 16 "match": { 17 "hobby": { 18 "query": "音乐", 19 "boost": 10 20 } 21 } 22 }, 23 { 24 "match": { 25 "hobby": { 26 "query": "跑步", 27 "boost": 2 28 } 29 } 30 } 31 ] 32 } 33 }, 34 "highlight": { 35 "fields": { 36 "hobby": {} 37 } 38 } 39 }
效果如下:
