一、CAP
1.1 CAP理论
第一版:any distributed System cannot guaranty C,A and P simultaneously.
对于一个分布式计算系统,不可能同时满足一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三个设计约束。
第二版:in a distruted sysytem,you can only have two out of the following three guarantees across a write/read pari: Consistency,Availabitity,and Partition Tolerance -one of them must be sacrificed.
在一个分布式系统中,当涉及读写操作时,只能保持一致性、可用性、分区容错性三者中的两个,两外一个必须被牺牲。
1.2 CAP应用
CAP理论定义三个要素只能取其二,但放到分布式环境下,必须选择P(分区容忍)要素,因为网络本身无法做到100%可靠,有可能出故障。
1.3 CAP关注点
CAP关注的粒度时数据,而不是整个系统;CAP是忽略网络延迟的(事务提交时,数据并不能瞬间复制到所有节点);放弃并不等于什么都不做 需要为分区恢复后做准备。
分区期间,记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到CA状态。举例:用户注册系统,采用CP,分区发生后,节点1可以继续注册,节点2无法注册(这里不符合A,节点2收到注册请求后会返回error),此时节点1可以将新注册但未同步到节点2的用户记录到日志中。当分区恢复后,节点1读取日志中的记录,同步给节点2,当同步完成后,节点1和2就达到了满足CA的状态。
如果采用了AP原则,节点1和2都可以修改数据,会发生数据不一致情况,分区恢复后,系统按照之情定的规则合并数据。如“最后修改原则”、“字数最多原则”,或者把数据冲突报高出来,由人工解决。
二、BASE
BASE:Basically Available(基本可用)、Soft State(软状态)和Eventually Consistency(最终一致性)。核心思想,即使无法做到强一致性,但可以采用合适的方式达到最终一致性。
基本可用:分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
软状态:允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是CAP理论中的数据不一致。
最终一致性:系统中的数据副本经过一定时间后,最终能够达到一致性的状态。
BASE理论本质上是对CAP的延伸和补充,是对AP方案的一个补充。AP方案中牺牲一致性只分区期间,而不是永远放弃一致性。这一点就是BASE理论延伸,分区期间牺牲一致性,但分区故障恢复后,系统应该达到最终一致性。
三、FMEA
FMEA(failure mode and effects analysis, 故障模式与影响分析),又称失效模式、后果分析、故障模式等。
架构设计领域,FMEA的具体分析方法如下:
(1)给出初始的架构设计图
(2)假设架构中某个部件发生故障
(3)分析此故障对系统功能造成的影响
(4)根据分析结果,判断机构是否需要进行优化。
四、存储高可用
本次主要讲解“分布式事务算法”
一些业务场景中需要事务来保证数据一致性,如果采用了数据集群的方案,那么这些数据可能分布在不同的集群节点上。由于与节点间只能通过消息进行通讯,因此分布式事务实现起来只能依赖消息通知。但消息本身并不可靠,消息可能会丢失,这就给分布式事务的实现带来了复杂性。
分布式事务算法中,常见的是“两阶段提交”(2PC)和“三阶段提交”(3PC)。
2PC:两阶段提交算法主要有:Commit请求阶段和Commit提交阶段。
两阶段算法成立基于如下假设:
① 在分布式系统,存在一个节点作为“协调者”,其他节点作为“参与者”,并且节点之间可以通过网络通讯
② 所有节点都采用预写式日志,且日志被写入后即保持在可靠的存储设备上,即使节点损坏,也不会导致节点日志数据的消失。
③所有节点不会永久性损坏,即使损坏,仍然可以恢复。
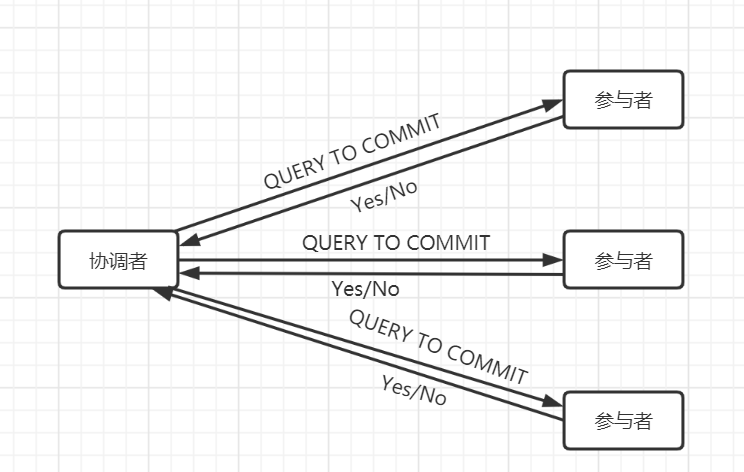
第一阶段提交(提交请求阶段):
协调者向所有参与者发送QUERY TO COMMIT 消息,询问是否可以执行提交事务,并开始等待各参与者的响应;
参与者执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志,返回Yes消息给协调者;如果参与者执行失败,则返回No消息给协调者。
示意图:
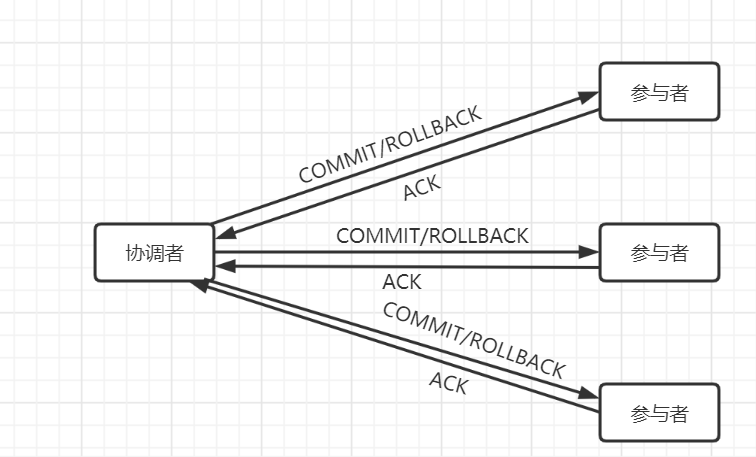
第二阶段(提交执行阶段)
【成功】
当协调者从所有参与者获得的相应消息都为“Yes”时:
① 协调者向所有参与者发出“COMMIT”的请求;
② 参与者完成COMMIT操作,并释放在整个事务期间所占用的资源;
③ 参与者向协调者发送“ACK”消息;
④ 协调者收到所有参与者反馈的“ACK”消息后,完成事务;
【失败】
当任一参与者在第一阶段返回的响应消息为“No”,或者协调者在第一阶段的询问超时之前无法获取所有参与者的响应消息时:
① 协调者向所有参与者发出“ROLLBACK”消息请求;
② 参与者利用之前写入的“Undo”信息执行回滚,并释放整个事务期间所占用的资源;
③ 参与者向协调者发送“ACK”消息;
④ 协调者收到所有参与者反馈的“ACK”消息后,取消事务;
示意图:
2PC强调一致性算法,优点实现简单,缺点如下
同步阻塞;状态不一致;单点故障(协调者是整个算法的单点,如果协调者故障,则参与者会一直阻塞下去)
3PC:三阶段提交算法是争对二阶段提交算法的“单点故障”而提出的。在二阶段提交算法中,插入一个新的阶段“准备阶段”。当协调者故障后,参与者可以通过超时提交来避免一直阻塞。
第一阶段(提交判断阶段):
①协调者向参与者发送canCommit消息,询问参与者是否可以提交事务
②参与者收到canCommit消息后,判断自己是否可以提交事务,如果可以则返回yes,否则返回no
③如果协调者收到任何一个no消息或参与者超时,则事务终止,同时通知所有参与者终止事务,如果在超时时间之前收到了所有yes,则进入第二阶段
第二阶段(准备提交阶段):
①协调者发送preCommit消息给所有参与者,告诉参与者准备提交。
②参与者收到preCommit消息后,执行事务操作,将undo和redo信息记录到事务日志上,然后返回ack消息
第三阶段(执行提交阶段):
①协调者在接到所有ack消息后会发送doCommit,告诉所有参与者正式提交;否则会给所有参与者发出终止事务消息,事务回滚;
② 参与者接到doCommit消息后提交事务,然后返回haveCommited消息
③如果参与者收到一个preCommit消息并返回了ack,但等待doCommit消息超时(如协调者故障或超时),参与者则会在超时后继续提交事务。
流程如下:
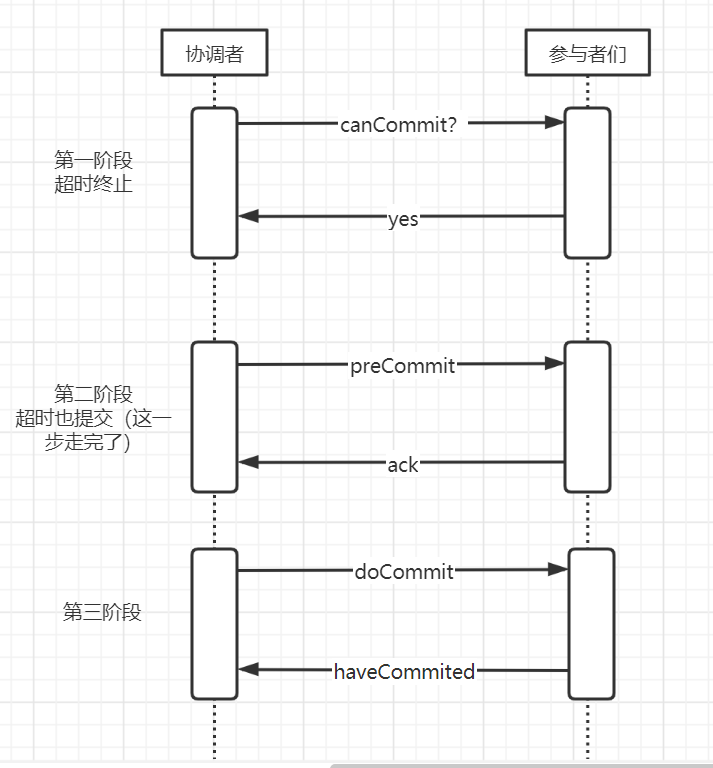
三阶段提交算法虽然避免了二阶段提交算法的协调者单点故障导致系统阻塞问题,但同样存在数据不一致问题。