Hadoop 3.x的发展Hadoop版本包括Hadoop 1.x、Hadoop 2.x和Hadoop 3.x。本节将以Hadoop 3.1.0为例,完成HDFS高可用的搭建。
Hadoop 3新特性
Hadoop 3.1.0 GA版本于2017年12月份正式发布。Hadoop 3相较于Hadoop 2有一些新特性,包括基于JDK 1.8、HDFS可擦除编码、MR Native Task优化、基于Cgroup的内存隔离和IO Disk隔离,以及支持更改分配容器的资源Containerresizing等。
Hadoop 3的新特性介绍如下。
1.classpath isolation
防止不同版本的JAR包发生冲突。
2.Shell重写
启动脚本和Hadoop 2.x不同。
3.支持HDFS中的擦除编码
主要用于做数据恢复,这一特性使HDFS的存储节省了一半空间,同时还不降低可靠性。擦除编码目前主要针对的是大数据块。
擦除编码的工作原理是把存储系统接收到的大块数据进行切割并且编码,接着再对切割之后的数据进行再次切割并编码,持续重复这个操作,直到数据切割到合适的数据块大小为止,这样数据块就分散成多个数据块,再进行冗余校验,把不重复的数据块和编码写到存储系统中。
4.MapReduce任务级本地优化
提高MR的执行速度,Hadoop 3为MapReduce增加了基于C/C++的map outputcollector。
5.MapReduce内存参数自动推断
Hadoop 2.x中通过配置mapreduce.{map,reduce}.memory.mb和mapreduce.{map.reduce}.Java.opts来配置所使用的内存,如果设置不合理,则会使内存资源严重浪费,而在Hadoop 3.x中则不需要再配置。
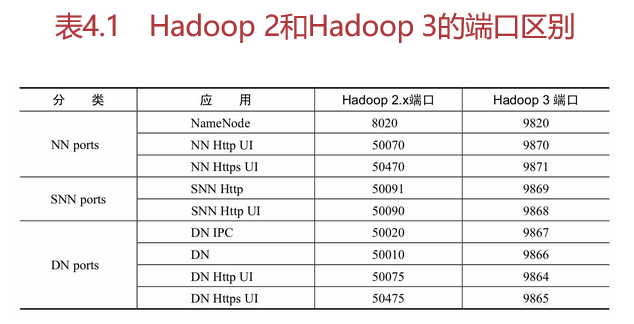
6.端口区别
Hadoop 2和Hadoop 3的端口区别如表4.1所示。
Hadoop 3 HDFS集群架构
HDFS集群中包括NameNode、DataNode和SecondaryNameNode,具体介绍如下。
·NameNode:接受客户端的读写服务,比如文件的上传和下载,保存元数据,包括文件大小、文件创建时间、文件的拥有者、权限、路径和文件名。元数据存放在内存中,不会和磁盘发生交互。
·DataNode:简称DN,与NameNode对应,主要用来存储数据内容,本地磁盘目录存储数据块(Block),以文件形式分别存储在不同的DataNode节点上,同时存储Block的元数据信息文件。
·Secondary NameNode:前面提到NameoNode的元数据存储在内存中,为了保证数据不丢失,需要将数据保存起来,这里涉及的文件包括fsimage和edits。fsimage是整个元数据文件,在集群刚开始搭建时是空的,对元数据增删改的操作放到edits文件中。Secondary NameNode完成数据的合并操作,每隔3600秒更新一次。
