1. 简单说明爬虫原理
1、向服务器发起请求
2、获取响应内容
3、解析内容
4、保存内容
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
浏览器的主要功能是向服务器发出请求,在浏览器中展示选择的网路资源,一般资源就是HTML文档,也可以是PDF, IMGAGE,或者其他类型,资源的位置由用户使用URI(统一资源表示符)指定。
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests url='http://news.gzcc.cn/html/2019/meitishijie_0225/10895.html' res = requests.get(url) res.encoding='utf-8' res.text
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<html> <body> <h1 id="title">Hello</h1> <a href="#" class="link"> This is link1</a> <a href="# link2" class="link" qao=123> This is link2</a> </body> </html> '
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
<html> <body> <h1 id="title">Hello</h1> <a href="#" class="link"> This is link1</a> <a href="# link2" class="link" qao=123> This is link2</a> </body> </html> ' soups = BeautifulSoup(html_sample,'html.parser') a1 =soups.a a = soups.select('a') h = soups.select('h1') t = soups.select('#title') l = soups.select('.link')
3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其
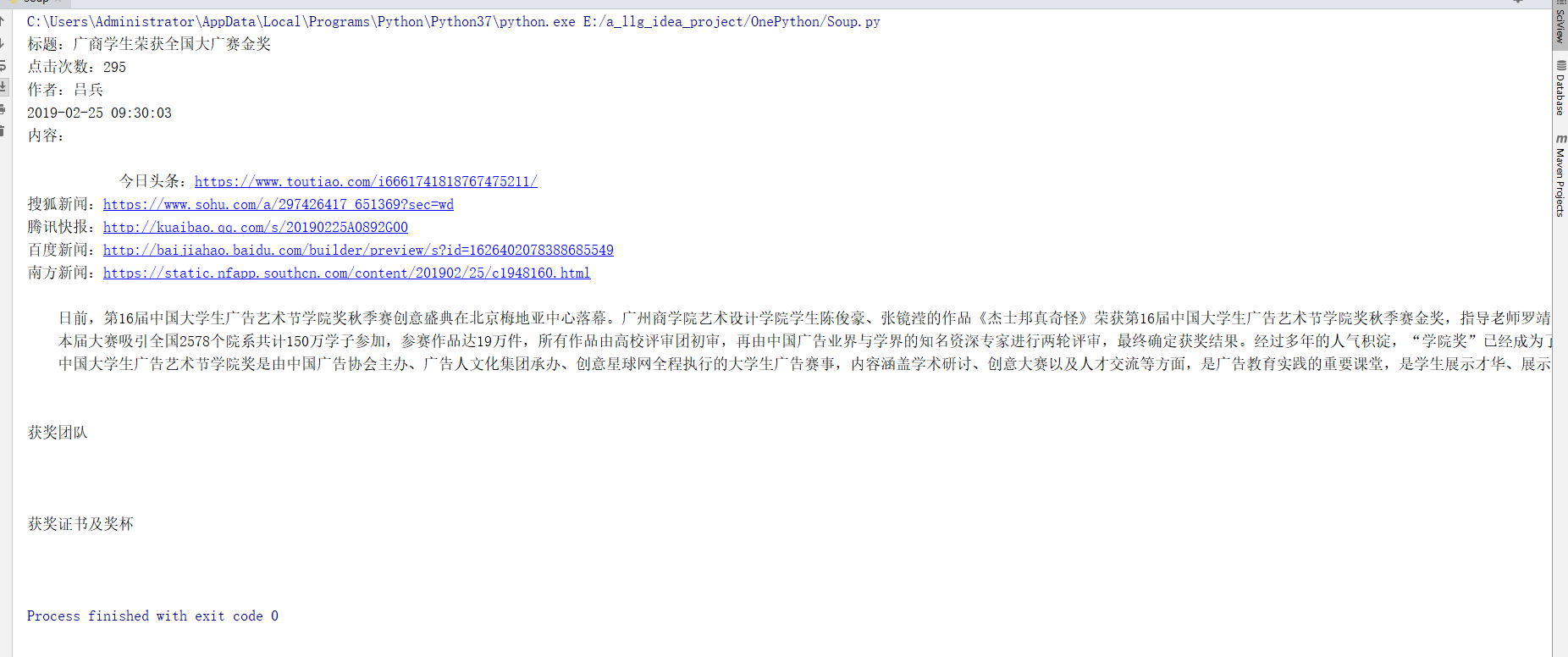
temp=requests.get("http://news.gzcc.cn/html/2019/meitishijie_0225/10895.html") temp.encoding='utf-8' soups=BeautifulSoup(temp.text,'html.parser') title=soups.select('.show-title')[0].text content_array=soups.select('.show-info')[0].text.split() content=soups.select('#content') publish_date=content_array[0].split('发布时间:')[1] actor=content_array[2] click=requests.get("http://oa.gzcc.cn/api.php?op=count&id=11095&modelid=80").text.split('.html')[-1].replace("(","").replace(")","").replace("'","").replace(";","") date=datetime.strptime(publish_date+' '+content_array[1],'%Y-%m-%d %H:%M:%S') print("标题:"+title) print("点击次数:"+click) print(actor) print(date) print("内容:"+content[0].text)
演示: