 这几天在写一个spark的程序做数据的迁移工作,但是我看了一下cm管理的spark的版本是1.6.0的spark(我们集群安装的cm的版本是5.14.0的版本)于是就要将spark2集成到我们的大数据管理平台当中去。步骤如下:
这几天在写一个spark的程序做数据的迁移工作,但是我看了一下cm管理的spark的版本是1.6.0的spark(我们集群安装的cm的版本是5.14.0的版本)于是就要将spark2集成到我们的大数据管理平台当中去。步骤如下:

通过这张图我们可以看到,在cm的管理平台上,有两种集成模式的spark。其中一个是spark on yarn模式的spark,一种是spark 在standlone模式的spark。这两个都不是我们想要的模式。于是要进行集成spark2.
安装准备:
(1)准备csd包:http://archive.cloudera.com/spark2/csd/
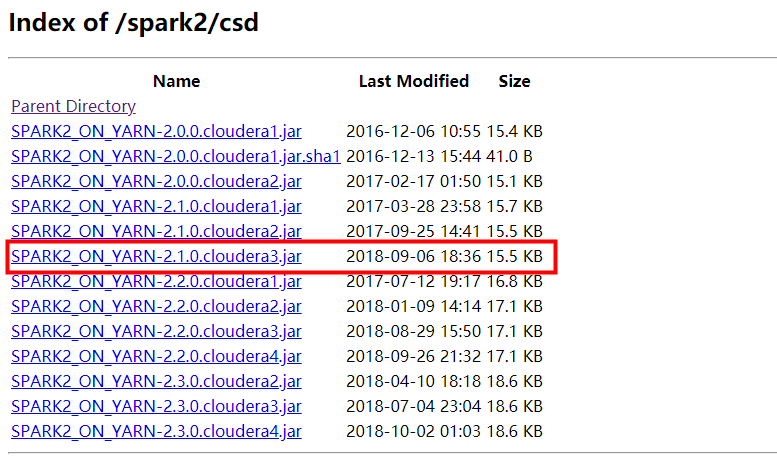
在这里选择自己要安装的spark2的安装包,这里需要注意一下啊,如果你的jdk的版本不是1.8的不要装spark2.2的版本,即使装好了后面也要卸载掉。不要给自己找麻烦
(2)parcel包:http://archive.cloudera.com/spark2/parcels/2.1.0.cloudera3/
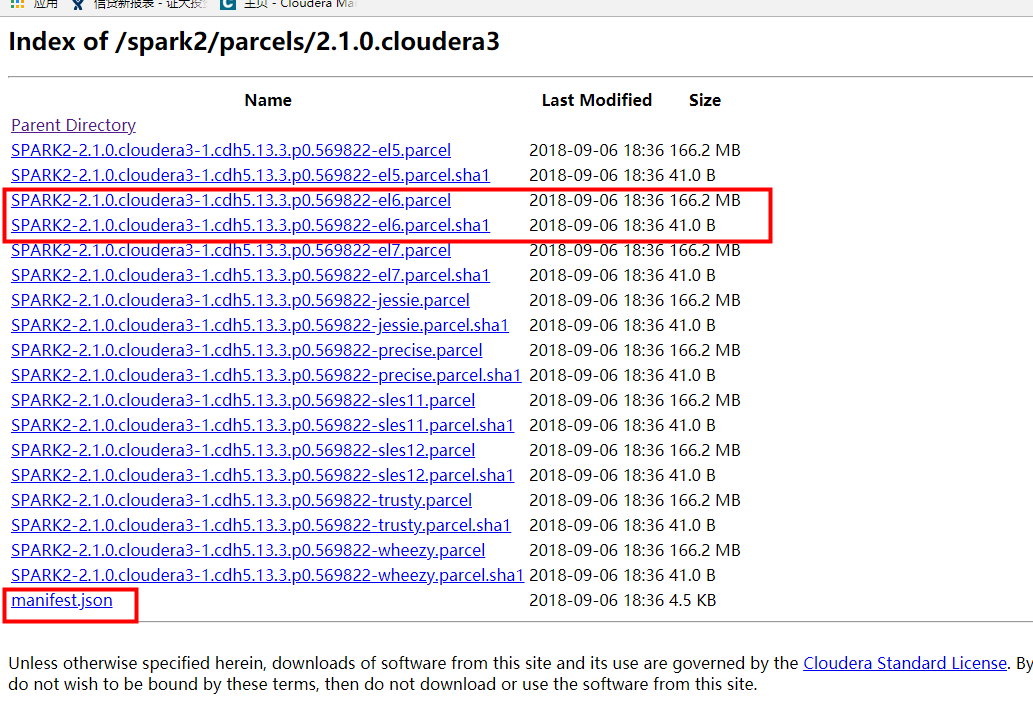
注意,下载对应版本的包,我的CentOS7,所以下载el7的包,若是CentOS6,就要下el6的包。这里对应的cloudera的版本一定也要对应上
准备好需要的包,现在开始安装:
(1)操作前停掉集群的所有服务
(2)接下来在执行下面的命令
上传CSD包到机器的/opt/cloudera/csd目录,并且修改文件的用户和组。
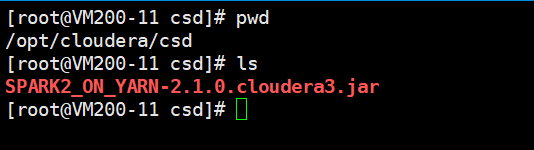
chown cloudera-scm:cloudera-scm SPARK2_ON_YARN-2.1.0.cloudera3.jar
chmod 644 SPARK2_ON_YARN-2.1.0.cloudera3.jar 修改jar包的执行权限
(3)上传parcel包到机器的/opt/cloudera/parcel-repo目录下。注意,。如果有其他的安装包,不用删除 ,但是如果本目录下有其他的重名文件比如manifest.json文件,把它重命名备份掉。然后把那3个parcel包的文件放在这里。
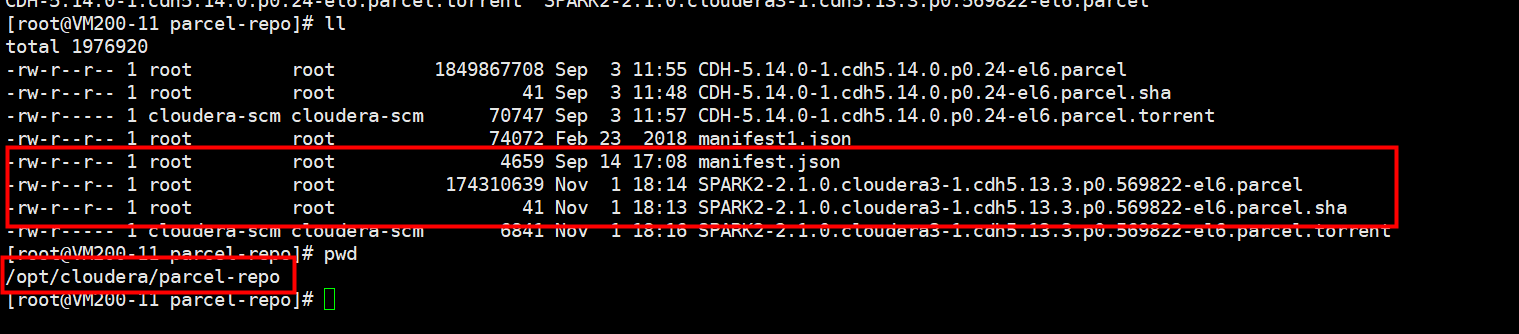
这里需要注意的是,将下载的sha1文件重命名为以sha结尾的文件,这样数据才能读到。
(4)现在重启一下cm。启动命令如下
service cloudera-scm-server restart 这个是重启一下cm的server
service cloudera-scm-agent restart 这个是重启一下cm的agent,这里重启所有节点上的agent。
(5)把CM和集群启动起来。然后点击主机->Parcel页面,看是否多了个spark2的选项。如下图,你这里此时应该是分配按钮,点击,等待操作完成后,点击激活按钮
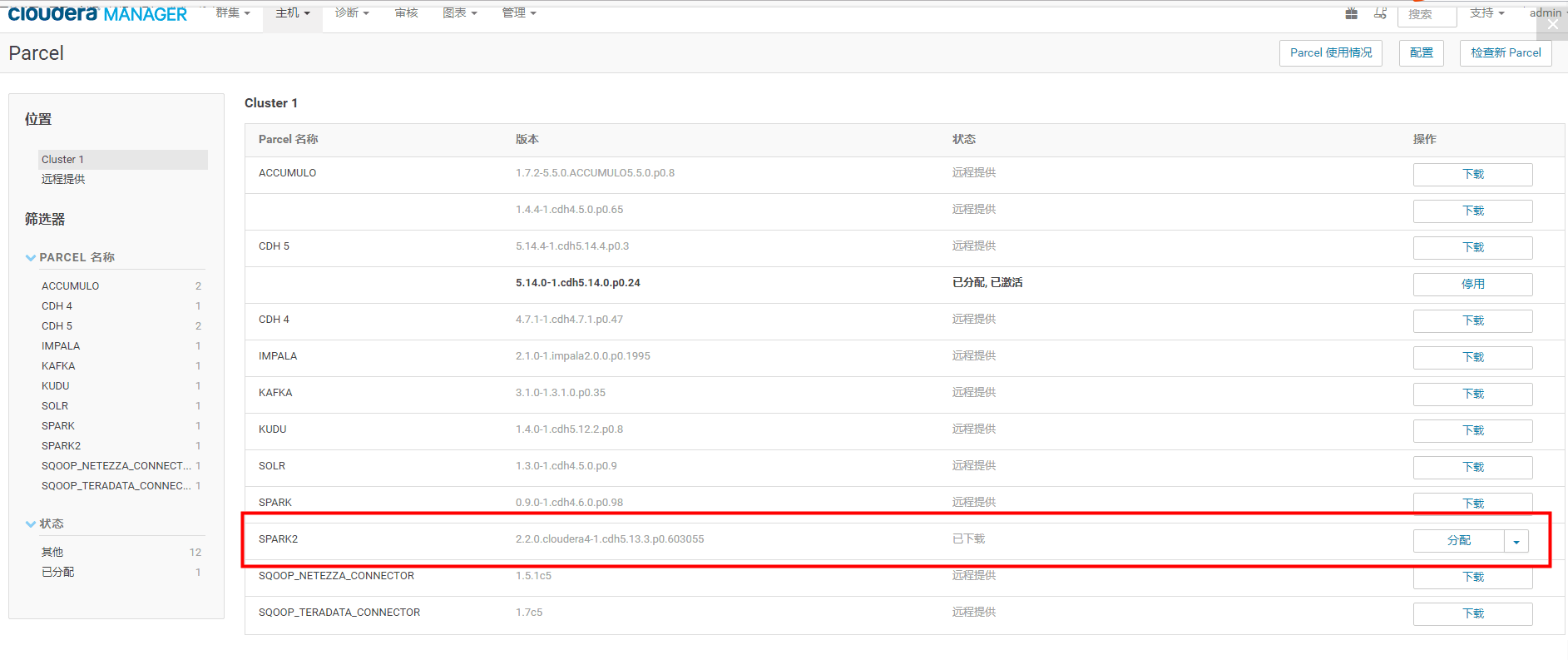

然后到管理界面,添加spark2的服务即可。
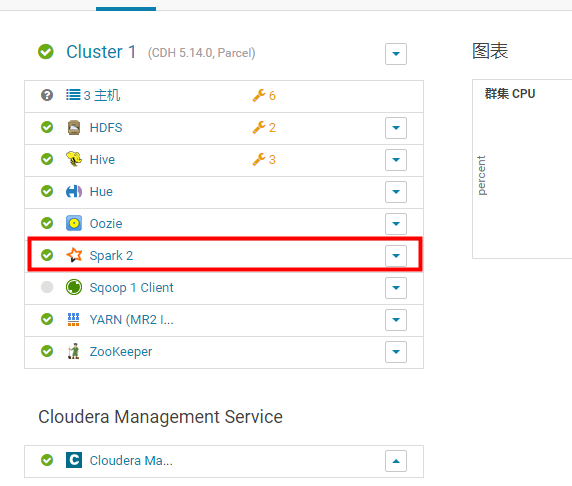
最终服务添加完成。算是整个的安装步骤结束。
集成好了spark2之后,我们就需要通过oozie来调度spark的程序。下一篇介绍通过hue使用oozie来调度spark2程序。