今天在做将oracle当中获取到排序后的第一行的数据执行的sql如下:
SELECT USERCODE,org_id FROM ( select usercode, org_id from com_employee where in_active = 't' and employee_type = '管理人员' order by id DESC ) WHERE ROWNUM = 1
这句sql是将数据过滤掉,然后取出第一行的数据,获取到这两个字段;
然后我们去hive里面进行改造:
方法一:
select id,usercode, org_id from com_employee where trim(in_active) = 't' and employee_type = '管理人员' order by id desc limit 1
将数据查询出来,然后按照ID进行排序,然后去第一条数据。使用hive当中的limit 条件进行过滤;
方法二:
select id, usercode, org_id, ROW_NUMBER() OVER( ORDER BY id desc) from com_employee where trim(in_active) = 't' and employee_type = '管理人员'
这里使用到了
ROW_NUMBER()OVER() 分析函数,一般都是按照每个字段进行分组,然后排序之后得到一个排序后的行编号。
例子:ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2) 这个就是按照某个列分组,然后按照另外一个列排序。然后统计出行号。
说到这里还有两个分析函数,分别是rank() over() , dense_rank() over()这两个也是给排序好的字段进行排序操作具体的结果如下;(借鉴别人的图)
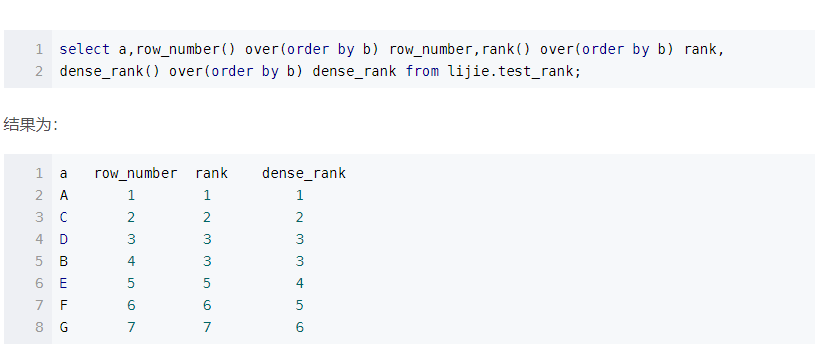
同样是对ID进行排序操作。对于ROW_NUMBER() 不管是怎么的都是按照罗马数字的形式进行排序。
对于rank()函数,他对重复的ID进行跳过,重复几次就跳过几次。
对于dense_rank()他会将同样的ID设置相同的行号,然后后面的按照罗马数字排序