最近在做要执行很复杂的sql.然后在文件输出的时候出现了一堆小文件:
为啥要对小文件进行合并一句话总结为:文件数目过多,增加namenode的压力。因为每一个文件的元数据信息都是存在namenode上面的。所以要减少小文件的数据量。
同时也是降低下一个程序处理这些小文件,启动和小文件一样数量的map数。增加jvm的压力。
从两方面出发进行控制hive最终的文件大小:
(1)从数据的文件大小控制,也就是控制map的数量:
由于mapreduce中没有办法直接控制map数量,通过设置每个map中处理的数据量进行设置;reduce是可以直接设置的。
控制map和reduce的参数 set mapred.max.split.size=256000000; -- 决定每个map处理的最大的文件大小,单位为B set mapred.min.split.size.per.node=1024000000; -- 节点中可以处理的最小的文件大小
set mapred.min.split.size.per.rack=1024000000; -- 机架中可以处理的最小的文件大小
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
上面三个参数分别是map切分的文件大小。这个没有办法通过参数进行调整,这能动态的进行设置。第二个参数是对一个节点上面的文件进行合并,然后一个map的大小设置。第三个参数是对每个机架上面的文件进行合并。
这三个参数的大小设置的顺序为:
mapred.max.split.size <= mapred.min.split.size.per.node <= mapred.min.split.size.per.rack
(2)对于map数的控制是通过上面的参数进行设置的。但是这个只是控制map的数量,并不能控制reduce形成的数据文件的大小,因此我们还要在reduce端进行文件的合并操作
方法1 set mapred.reduce.tasks=10; -- 设置reduce的数量 方法2 set hive.exec.reducers.bytes.per.reducer=1073741824 -- 每个reduce处理的数据量,默认1GB
通过设置reduce的个数控制reduce端的文件的输出个数,还有一种方法是通过设置进入reduce端的数据的文件大小来控制文件的大小,来控制reduce的文件输出的个数。
除了通过上面的例子参数对reduce的个数进行控制之外,我们还要控制在reduce端形成的文件大小,不能让小文件这种现象在出现。
可以通过配置如下几个参数,合并Map和Reduce的结果文件,消除这些影响。
- 控制每个任务合并小文件后的文件大小(默认256000000):hive.merge.size.per.task
- 告诉hadoop什么样的文件属于小文件(默认16000000):hive.merge.smallfiles.avgsize
- 是否合并Map的输出文件(默认true):hive.merge.mapfiles
- 是否合并Reduce的输出文件(默认false):hive.merge.mapredfiles
关于上免的参数的例子我做了一些实验,对于map数量的设置,直接通过set的方式进行设置即可,对于reduce端输出的文件大小的设置我的实验如下:
create table loan_base_copy as select i.* FROM loan_base c left join loan_special_repayment i on i.loan_id = c.ID
通过在hive的命令行执行上面的语句,然后转换为mapreduce任务。在这句sql当中,我们想控制在reduce端输出的文件大小。这里我设置了 hive.merge.smallfiles.avgsize的大小为256M。默认是16M。
这句话的意思是在hive在执行之后reduce端的数据如果小于这个数,则会进行合并,然后按照我们给定的大小hive.merge.size.per.task 每一个任务合并的大小进行合并,他的值就是合并之后文件的大小。我们这里设置为512M.
执行的结果和执行的过程如下:
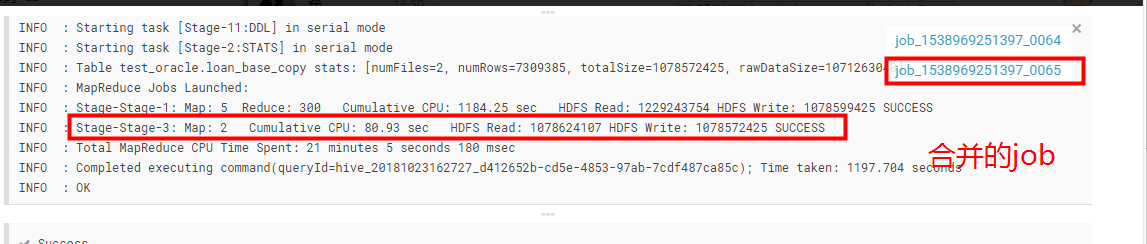
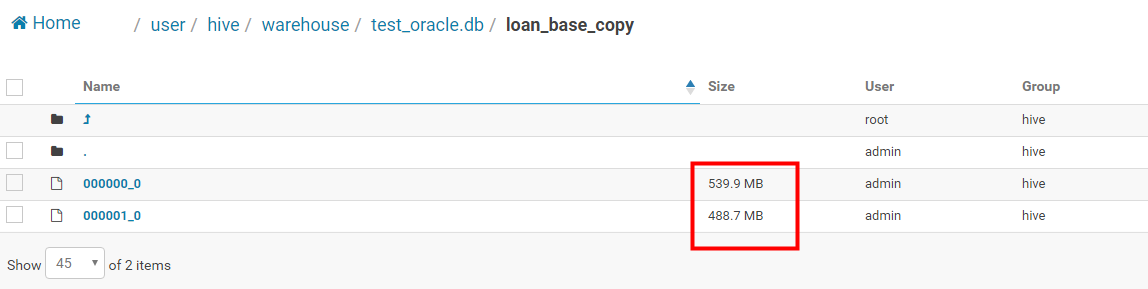
整个的reduce的合并是需要单独启动一个job的,然后将数据进行合并,至于我这里设置的数据为512M的文件大小,最后形成的文件大小不是512M。总而言之形成的不是小文件就好了。
(这里一定要搞清楚,只有reduce端形成的文件小于设置的hive.merge.smallfiles.avgsize的文件大小才实现文件的合并操作,合并的大小就是设置的hive.merge.size.per.task)