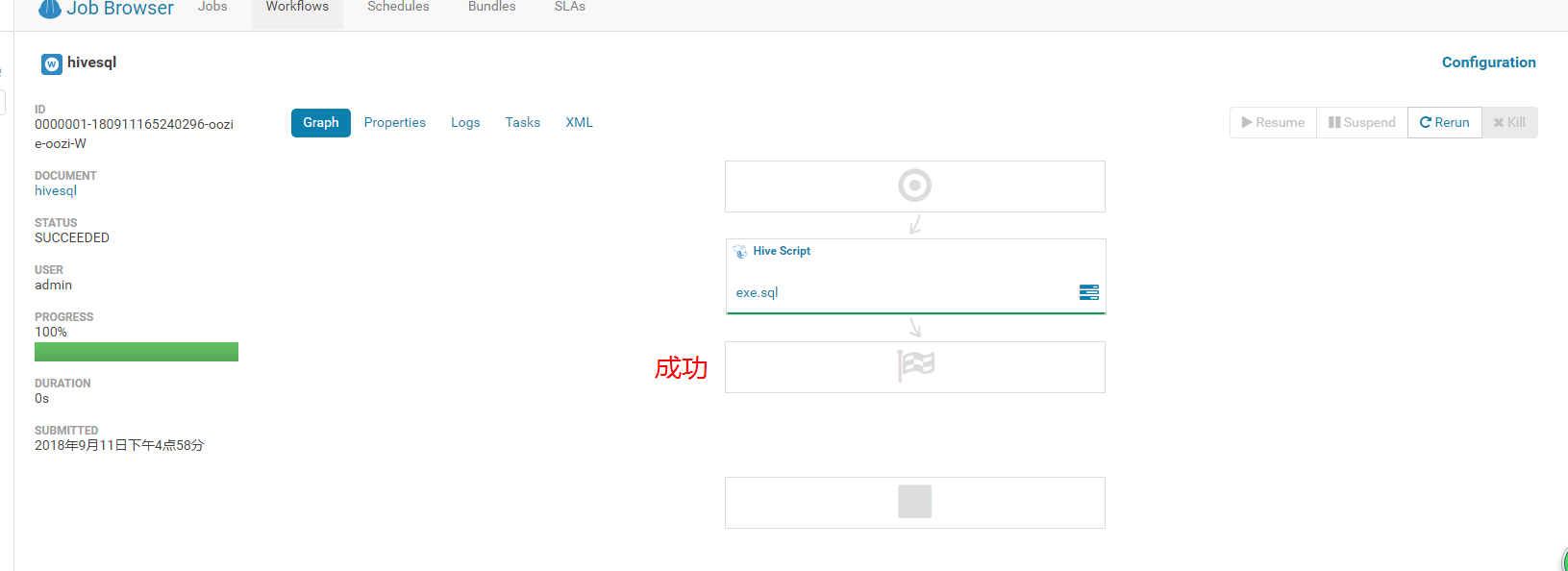
最近在做数据迁移的工作,但是那在使用hue建的工作流,提交任务之后两个任务,一个是oozie的常驻进程job laucher,还有一个就是真实的任务。action操作的任务。

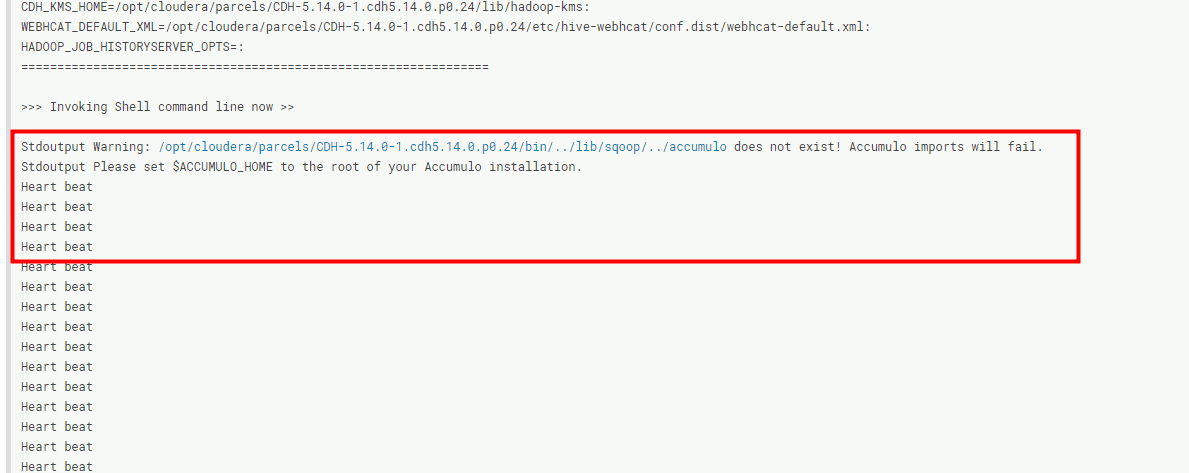
执行的结果就是这样的,launcher操作一直停在95%,正真的action操作则一直停在5%这里。然后hue的日志一直在向master发送心跳,也不报错,就一直卡着。然后网上百度了一圈,说调资源就可以了。但是一直调就是不行,很奇怪。
调着调着还把问题调出来了资源给的太小,然后就oom了。错误如下:
Diagnostics: Container [pid=24987,containerID=container_1536566845435_0002_02_000001] is running beyond physical memory limits.
Current usage: 271.2 MB of 256 MB physical memory used; 1.5 GB of 537.6 MB virtual memory used. Killing container.
这里要解释一下这个错误了:
271.2MB: 任务所占的物理内存
256MB 是mapreduce.map.memory.mb 设置的
1.5G 是程序占用的虚拟内存
537.6MB 是mapreduce.map.memory.db 乘以 yarn.nodemanager.vmem-pmem-ratio 得到的
其中yarn.nodemanager.vmem-pmem-ratio 是 虚拟内存和物理内存比例,在yarn-site.xml中设置,默认是2.1, 由于我本地设置的是256, container占用了1.5G的虚拟内存,但是分配给container的却只有537.6MB。所以kill掉了这个container
这个是由于我们在调整yarn上面的资源的时候,包括map的内存,reduce的内存的时候分配的太小了,导致提交的任务需要的资源集群当中满足不了,导致内存溢出,然后这个container就爆掉了。然后没办法运行。
说到这里我们来看一下yarn当中的资源的配置:
yarn-site.xml yarn.scheduler.minimum-allocation-mb yarn.scheduler.maximum-allocation-mb 说明:单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,小于最小值则分配最小值,从这个角度看,最小值有点想操作系统中的页。最小值还有另外一种用途,计算一个节点的最大container数目注:这两个值一经设定不能动态改变(此处所说的动态改变是指应用运行时)。 默认值:1024/8192 yarn.scheduler.minimum-allocation-vcores yarn.scheduler.maximum-allocation-vcores 参数解释:单个可申请的最小/最大虚拟CPU个数。比如设置为1和4,则运行MapRedce作业时,每个Task最少可申请1个虚拟CPU,最多可申请4个虚拟CPU。 默认值:1/32 yarn.nodemanager.resource.memory-mb
参数解释:这个参数的配置是非常重要的,他是每个节点可用的最大内存,RM(resourcemanager)中的两个值不应该超过此值。此数值可以用于计算container最大数目
下面来看一下这几个参数之间的关系:
yarn.scheduler.minimum-allocation-mb 和 yarn.scheduler.maximum-allocation-mb 这两个都是单个的container申请资源的最小和最大值,应用在运行时申请的内存不能超过这个配置项的值。
但是这个配置项是指定一个container的最大的内存,实际分配内存时并不是按照配置项进行分配,这里的配置项配置成和nodemanager的可用内存(yarn.nodemanager.resource.memory-mb)一样即可,这样的话,意味着只要节点的nodemanager可用内存哪怕
只有一个container,这个container也可以启动。(这里其实就是说我们尽量将两者的值配置相同)。
因为如果配置的参数比nodemanager的可用内存(yarn.nodemanager.resource.memory-mb)小,那么可能出现这个节点总内存即使足够提供所需内存的,但却无法启动container的情况。
这里还要说一点,
yarn.nodemanager.resource.memory-mb 的配置决定了集群当中总的内存大小。截图如下
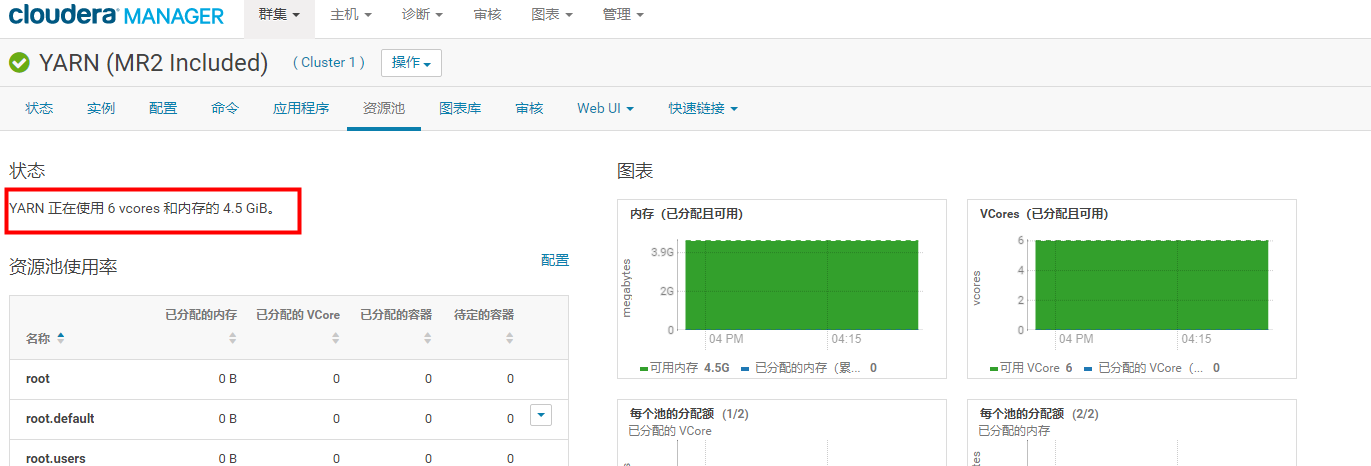
我这里配置的是每个节点为1.5G,然后每个节点2核。所以在这里就会出现这样的情况。我们的集群是三台机器,所以这里的总数就是这样的。
说到这里我们还需要关心的配置就是我们的map的内存和reduce的内存配置了。另外就是appMaster的配置项的配置。
mapreduce.map.memory.mb
- 指定map任务时申请的内存,是一个精确值,不是范围值,这就是一个map真实用到内存的值了。
- 这个配置是可以在脚本或代码中动态申请的,但是取值范围必须是在container内存大小值之间。
- 即 yarn.scheduler.minimum-allocation-mb < mapreduce.map.memory.mb < yarn.scheduler.maximum-allocation-mb
- 比如在hive中申请:set mapreduce.map.memory.mb=4096;
- 实际上,我们现在大部分脚本在执行前都是动态申请一下的。只要在container大小以内。
遗留问题:
这个值该如何配置。还是说不需要配置,只需要把控container的大小内存,有开发人员根据实际情况申请,
mapreduce.reduce.memory.mb
和map的是对应的,指定reduce任务执行时申请的内存,是一个精确值,不是范围值。
可以在脚本或者代码中动态申请,取值范围必须是在container内存大小值之间。
配置时建议这个值是map的2倍,这个可能是要考虑到多个map后数据可能会有一个reduce处理,根据实际需要来看。
(这说一下,不一定为map的两倍奥,因为如果你container的大小为1.5G,然后你的map内存为1G,然后你将reduce的大小设置为2G就会报下面的错误,所以还是要按照自己的实际情况去定义)
REDUCE capability required is more than the supported max container capability in the cluster. Killing the Job. reduceResourceRequest: <memory:2048, vCores:1> maxContainerCapability:<memory:1536, vCores:2> Job received Kill while in RUNNING state.
yarn.app.mapreduce.am.resource.mb
指定appMaster的运行内存,默认是1.5g。
appMaster也是运行在container中,所以如果修改了yarn.scheduler.maximum-allocation-mb,就要注意修改这个配置
这个值必须小于 yarn.scheduler.maximum-allocation-mb才可以启动appMaster
至此我的总结就是在改yarn的资源配置的时候,我们首先关系的应该是 yarn.nodemanager.resource.memory-mb 这个配置参数的大小,因为这个定下来之后我们在去定义 yarn.scheduler.maximum-allocation-mb的大小。
从而我们就可以定义map的内存大小,reduce的内存大小随之就别定义好了。只有这样我们的集群资源不会出现内存溢出的现象。当内存溢出的时候我们的解决办法是尽量的调整 mapreduce.map.memory.mb的代表不要让虚拟内存超过实际的物理内存。
爆出下面这个错误(也不要关掉内存检查机制,因为那样是治标不治本的。只有调整map的内存才行)
Diagnostics: Container [pid=24987,containerID=container_1536566845435_0002_02_000001] is running beyond physical memory limits.
Current usage: 271.2 MB of 256 MB physical memory used; 1.5 GB of 537.6 MB virtual memory used. Killing container.
我的问题最后解决了,假死的任务启动了。但是我改了好多遍。来回改这几个参数。我介绍一下我改的情况:
yarn.scheduler.minimum-allocation-mb 256MB yarn.scheduler.maximum-allocation-mb 1.5GB
yarn.nodemanager.resource.memory-mb 1.5GB
mapreduce.map.memory.mb 1GB
mapreduce.reduce.memory.mb 1GB
yarn.app.mapreduce.am.resource.mb 512MB
改的配置参数大概就这么多。具体的以自己集群当中的实际资源为准去配置就可以了。