问题描述:我们知道在spark当中是对RDD进行操作的。所以我们想把数据源当中的数据转化成很多的数据集,这也就是partition的由来。
而我们在将数据转换成RDD之后。我们可以通过设置partition的数量来让计算的效率更高。
首先来看一下官网创建的RDD的描述:

从这段描述当中我们可以看到。通过parallelize来个创建RDD。这个时候创建的partiton数 量是根据集群当中的CPU的核数进行创建的。但是在官网当中我们可以看到
建议是一个核数尽量分配2到4个partition。
通过下面的例子我们来验证这个问题:
我们的集群有5台机器:(我在server1和server5上面提交任务看下面的结果)
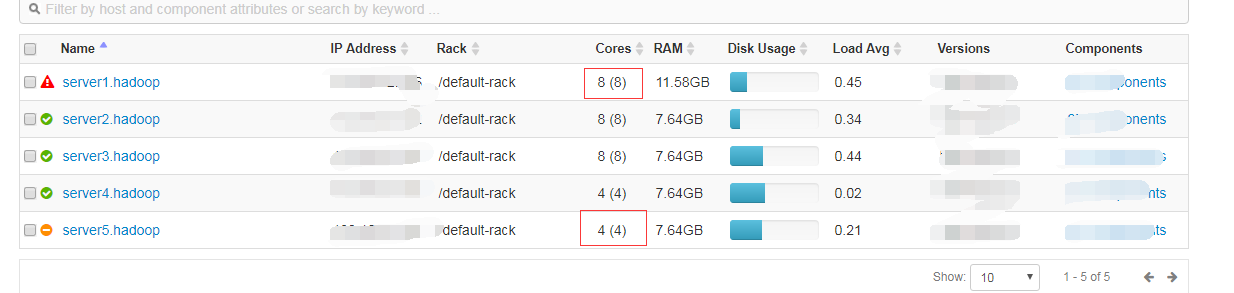

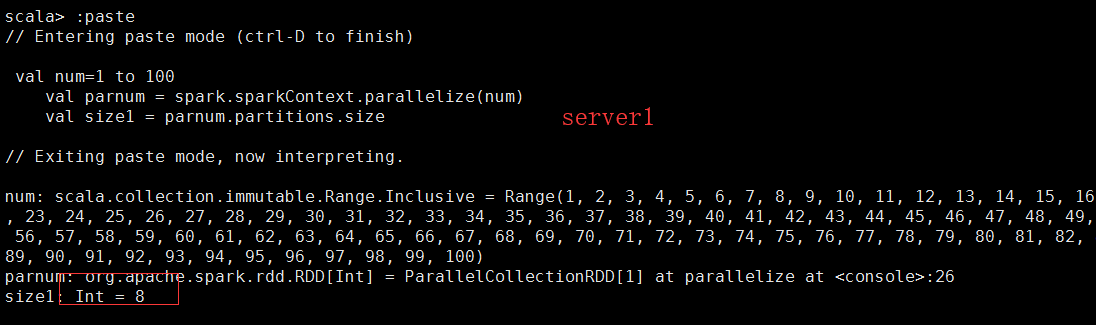
我们可以看到在不同的机器上去提交任务的时候,所生成的分区的数量是根据CPU的核数来定的。
下面我们来设置一下载parallellize后面设置partition的个数来定义指定的数据源的分区数是多少。
val parnum = spark.sparkContext.parallelize(num,10)
在这里我们设置第二个参数我们队第二个参数进行了设置。这里设置为10.他会将数据源中的数据切分成10个分区。在数据量比较大的情况下优化计算。

使用这种方式创建的RDD可以对分区的数量进行设置。还有一种创建RDD的方式是通过另外一种方式去创建。(缺点是不能修改分区的数量。只能根据系统CPU的情况定义分区的数量) 代码如下。
val unit = spark.sparkContext.makeRDD(num)
至此我们通过数据源创建的RDD最简单的方式总结如上。