今天突然发现,我们的flink程序挂掉了,然后先把程序启动起来,发现正常运行,然后去看什么问题,发现我们的集群当中的一台服务器挂掉了,然后重新启动了一台服务器
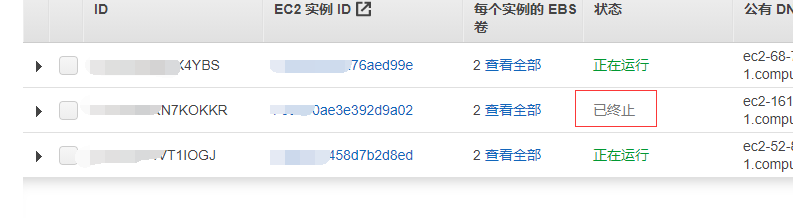
然后紧接着,我去看yarn资源管理器看失败的任务发现超时
Application application_1603766479824_0004 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1603766479824_0004_000001 exited with exitCode: -100 Failing this attempt.Diagnostics: Container released on a *lost* nodeFor more detailed output, check the application tracking page: http://ip-172-31-30-217.cn-northwest-1.compute.internal:8088/cluster/app/application_1603766479824_0004 Then click on links to logs of each attempt. . Failing the application.
然后我们去hdfs的界面发现也有问题:
Please check the logs or run fsck in order to identify the missing blocks. See the Hadoop FAQ for common causes and potential solutions.

flink程序在写日志的时候,数据块好像有问题。解决这个问题的办法如下
连接:http://www.julyme.com/20180202/99.html
但是在执行的时候出现了一点小问题,文件目录权限的问题:
Permission denied: user=root, access=READ_EXECUTE, inode="/tmp/entity-file-history/done":yarn:hadoo
解决这个问题的方法是:
先切回到你的用户下,然后执行 hadoop fsck -delete 命令这样数据块就被修复了
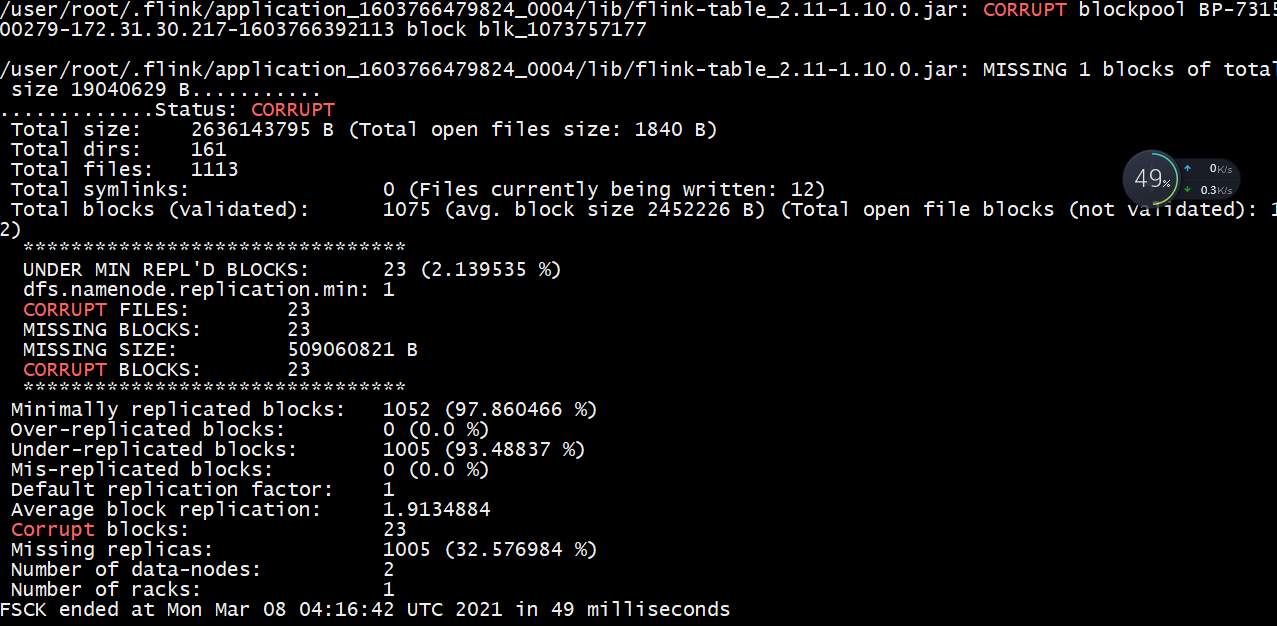
至此问题得到解决。