1,编码问题,主要是区分面向人类的字符串,面向计算机的字节序列
在python3中,字符串是str(默认即unicode),字节序列是bytes
在python2中,字符串是unicode,字节序列是str
无论python3还是python2,从字符串向字节序列转换称为encode(编码),从字节序列向字符串转换称为decode(解码)
python2中可以通过type(s)确定是str还是unicode
#coding:utf-8
1)s1 = '人生' # s1是str,类型是utf-8
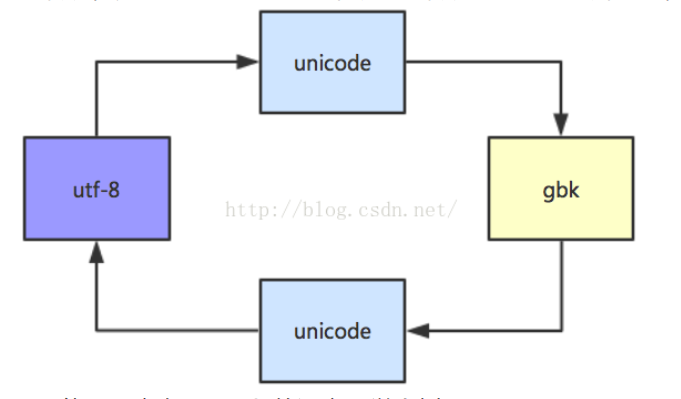
2)s1 = '人生'.encode('gbk') # 报错,原因是python实际执行了s = '中文'.decode('asc-ii').encode('gbk'),而ascii不支持中文
3)s1 = '人生'.decode('utf-8').encode('utf-8') # s1是str,类型是utf-8,转换过程是utf-8、unicode、utf-8
4)s1 = '人生'.decode('utf-8').encode('gbk') # s1是str,类型是gbk,转换过程是utf-8、unicode、gbk
5)s1 = u'人生' # s1是unicode
6)s1 = '人生'.decode('utf-8') # s1是unicode
7)s1 = unicode('人生' , 'utf-8') # s1是unicode,内部先转成str('utf-8'),再转成unicode,后面的'utf-8'改成'gbk'也行,如果不写则是通过defaultencoding转换
对于s = '你好',如果要显示到windows的gbk环境:
python2中,需要经过utf-8,unicode,gbk的转换,可以是:
#coding:utf-8
print '中文'.decode('utf-8').encode('gbk')
print unicode('中文', 'utf-8').encode('gbk')
print u'中文'.encode('gbk')
python3中,str所代表的都是unicode,可以直接输出到其他环境,支持中文显示:
print('中文')
4,python3编码
假设一段文本是gbk编码的
在windows上,系统默认gbk:
open(path, 'r') 或者 open(path, 'r', encoding='gbk') 可以正常解码
open(path, 'r', encoding='utf-8') 会报错, UnicodeDecodeError: 'utf-8' codec can't decode byte ......
在linux上,系统默认utf-8:
open(path, 'r', encoding='gbk') 可以正常解码
open(path, 'r') 或者 open(path, 'r', encoding='utf-8') 会报错, UnicodeDecodeError: 'utf-8' codec can't decode byte ......
假设bytes字节流压缩成gbk, 在linux上用python接受该字节流时, 必须用gbk解码,但保存至文本时,该文本会变成utf-8(python的默认编码)
sys.getdefaultencoding()拿到的应该是python语言的默认编码, 不是系统的默认编码
总结: 在windows上打开gbk编码文本不需要加encoding参数, 在linux上打开utf-8编码文本不需要加encoding参数
5, 和