语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
例一:
表数据:

create table TEST_ROW_NUMBER_OVER( id varchar(10) not null, name varchar(10) null, age varchar(10) null, salary int null ); select * from TEST_ROW_NUMBER_OVER t; insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000); insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
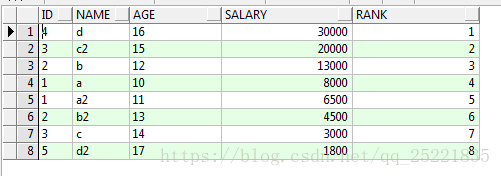
一次排序:对查询结果进行排序(无分组)
select id,name,age,salary,row_number()over(order by salary desc) rn from TEST_ROW_NUMBER_OVER t
结果:
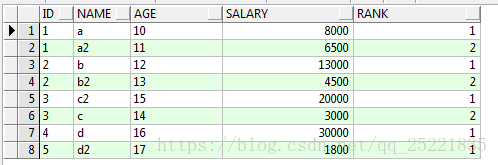
进一步排序:根据id分组排序
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t
结果:
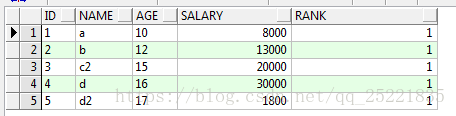
再一次排序:找出每一组中序号为一的数据
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t) where rank <2
结果:
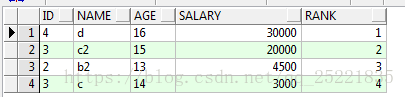
排序找出年龄在13岁到16岁数据,按salary排序
select id,name,age,salary,row_number()over(order by salary desc) rank from TEST_ROW_NUMBER_OVER t where age between '13' and '16'
结果:结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的
例二:
1.使用row_number()函数进行编号,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了:
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
4.统计每一个客户最近下的订单是第几次下的订单:
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
)
select MAX(rows) as '下单次数',customerID from tabs
group by customerID
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的:
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
6.筛选出客户第一次下的订单。
思路。利用rows=1来查询客户第一次下的订单记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
7.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>'2011-07-22'