目录
一、MySQL语法执行工作原理
客户端请求由Nginx等负载均衡服务器转交给Tomcat,Tomcat从MySQL中捞取数据,如果请求的数据在MySQL缓存中,那么MySQL会将缓存中捞取到的数据返回给客户端,如果缓存中没有请求的数据,那么MySQL会通过解析器解析SQL语法是否有问题(用户权限问题),在SQL语法没有问题的情况下,将SQL转交给优化器,看SQL是否通过索引等来进行查询,再通过存储引擎在磁盘中捞取数据。
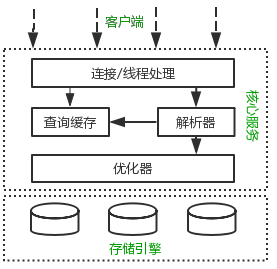
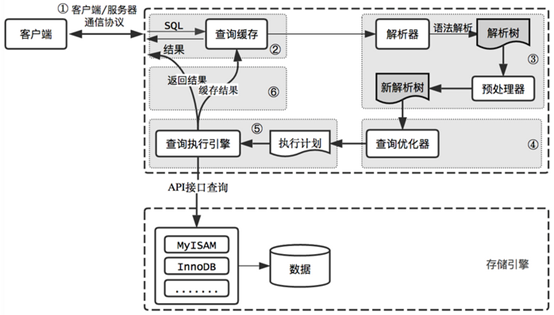
详细流程如下,对于IE-->TOMCAT-->MySQL的流程,客户端请求在到达Tomcat后,经历路程如下:
① 先在Tomcat的JVM中捞取数据,如果捞取到对应数据,请求直接返回;
② 在MySQL缓存(缓存数据集、SQL语法、表定义、表权限、字段)中查询数据,若查询到,MySQL在将缓存中查询到的数据返回给应用缓存时,会校验一遍用户权限,此时校验用户权限不会走解析器;若没有命中缓存,就会来到解析和预处理环节。
③ 将SQL交给MySQL的第二层对SQL语句的语法进行解析,该层包括解析器以及预处理器。这里的解析可以分为硬解析和软解析,在SQL语法没有问题的情况下,执行下一步操作。
解析器: 也叫语法解析器,SQL语句经过解析器解析之后,会生成一颗对应的解析数,在解析器中,MySQL会使用语法规则验证和解析查询,例如是否使用错误的关键字、使用关键字的顺序是否正确、验证引号是否能正确匹配等。
预处理器: 在预处理其中,进一步解析解析数是否合法并生成一颗新的解析数。例如:检查数据表和数据列是否存在,SQL语句的名字和别名是否有歧义,之后预处理器还会校验用户权限(权限校验一般会很快,除非服务器上有非常多的权限设置)。
硬解析: 通过硬件监听,例如SELECT * FROM STUDENT WHERE id='test001',解析SQL语句以及对应操作用户的权限,对于一个类型的SQL,在第一次查询的过程中,都是硬解析,查询速度较慢。
软解析: 在查询SELECT * FROM STUDENT WHERE id='test002'时,当第二次使用查询student这张表,并再次用id这个字段作为检索字段时,此时这条SQL已经缓存下来,该SQL被缓存成如下形式:SELECT * FROM STUDENT WHERE id=$,第二次查询时,就不需要消耗CPU去解析这这条SQL的语法,从而降低CPU的消耗。需要注意的是,MySQL缓存需要整个SQL语句全部命中,而软解析,当MySQL只是变量变化时,就会利用已有的解析数和执行计划。
④ 在生成了解析树之后,便来到查询优化器这一层,在查询优化器中,将解析数转化为执行计划,一般一条查询语句可以由多种执行计划完成,优化器的工作是从这些执行方式中找到性能最好的执行计划。
全表扫描: SELECT * FROM TABLE_NAME WHERE ...,将一张表无论什么样的数据,都全部一次性从硬盘中捞出来,这样的方式,在表中数据量较大的情况下,磁盘IO会比较大,造成CPU使用率较高(监听IO事件)。
索引扫描: 主键索引、普通索引、唯一性索引、全文索引(介绍链接:https://www.cnblogs.com/qianzf/p/7131760.html)
⑤ 找到最优的执行计划以后,MySQL调用查询执行引擎(InnoDB、MyISAM)在磁盘中捞取数据。
1.1 案例
案例1:
存在一张表,表名为table1,字段有id,name,age等字段,id为主键;同时存在第二张表,表名为table2,表字段以及数据和table1一样,但是无主键,无索引,现有下列SQL
SELECT * FROM table1 WHERE id = 1;
SELECT * FROM table2 WHERE id = 1;
SELECT * FROM table1;
SELECT * FROM table2;
上述SQL语句,均会通过I/O从磁盘中捞取一张表的全部数据,无论是否使用WHERE语句,是否使用索引,但是使用索引之后,数据库会通过索引到缓存中捞取数据,查询效率特别高。
案例2:
场景:
存在一张表,表名为table1,字段有id,name,age等字段,如果先到两条SQL如下:
SELECT * FROM table1 WHERE id = 1;
SELECT * FROM table1 WHERE id = 2;
第一条SQL类似语法到达MySQL完成解析返回结果后,第二条SQL是否能够命中缓存?
分析:
对于SQL语句到达MySQL在缓存中捞取数据时,会将这条SQL进行hash操作,这条SQL即使大小写不同,语法一样,但变量不同,都不会命中MySQL的缓存,此时,第二条SQL会到解析器中,但是,MySQL已经在解析器和预处理器中分析了第一条SQL的语法,得到了对应的解析计划,而第二条SQL和第一条SQL的语法相同,只是变量变化,所以在MySQL缓存中,仍然缓存了这条SQL的解析计划,在第二条SQL进入解析器时,会在MySQL缓存中捞取语法解析结果,如果命中,那么就会走软解析的路线,提高SQL语句的查询性能。
二、从MySQL语法执行原理谈性能测试
2.1 混合场景测试以及长时间稳定性测试的必要性
由于数据库的缓存机制和锁机制,在混合业务线以及大并发的过程中,当增删改查业务线并行的情况下,会出现资源争用的现象,进行混合场景测试,可以观察是否出现死锁现象,而如果数据库缓存设置不合理,在混合场景以及长时间的稳定性测试的过程中,实时的大数据量查询过程中,前面查询得到的数据库缓存被过早的清除掉,导致数据库频繁的对SQL语句进行解析,增大系统I/O以及数据库查询的时间,影响系统性能,综上所述,对典型交易做混合场景测试以及长时间稳定性测试来验证测试过程中对资源争用情况的处理是否合理,缓存空间配置是否充足,从而完成系统的高可靠性以及高可用性测试。所以,对于SQL语句而言,统一大小写是十分重要的。
2.2 数据库缓存设置大小和性能的关系
如2.1所述,数据库缓存设置太小,数据库缓存清理过快,影响系统性能,此外,对于基于MySQL主从库容灾集群部署的系统如果数据库缓存配置的比较大,在一台数据库服务器宕机的情况下,除了在切换的瞬间查询效率比较慢外,建立缓存后,可以保证查询的部分性能。
三、数据库服务器缓存配置策略
一般来说,数据库缓存越大,数据库的性能越好,所以在物理内存足够大的情况下,可以尽量配置多一点的内存给数据库。如果物理额内存8G,可以配置65%给数据库,如果物理内存4G,可以配置1/3给数据库,对于2G的物理内存,看情况进行配置。一般而言,在将SQL语法等问题都排除了,再来考虑数据库的内存配置问题。
四、各数据库集群部署方式
Oracle
自带集群部署方式(RAC)。
MySQL
MySQL本身不支持集群部署,但是通过第三方工具,可以做到主从配置的方式完成集群部署。
PostgreSQL
可使用PostgreSQL自带的工具(pgpool),完成集群部署。