1、什么是Sqoop:
Sqoop就是将数据在 关系型数据库(mysql、oracle)和 Hadoop 之间相互转移的工具。底层是用mapreduce来实现的。
2、Sqoop的工作机制:
https://blog.csdn.net/RivenDong/article/details/101423412
sqoop是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。主要用于在Hadoop与关系型数据库之间进行数据转移,可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
3、全量抽取和增量抽取
(1)增量抽取
Sqoop支持两种类型的增量导入:append和lastmodified。可以使用–incremental参数指定增量导入的类型。
当被导入表的新行具有持续递增的行id值时,应该使用append模式。指定行id为–check-column的列。Sqoop导入那些被检查列的值比–last-value给出最大的数据行。
Sqoop支持的另一个表修改策略叫做lastmodified模式。当源表的数据行可能被修改,并且每次修改都会更新一个last-modified列为当前时间戳时,应该使用lastmodified模式。那些被检查列的时间戳比–last-value给出的时间戳新的数据行被导入。
增量导入命令执行后,在控制台输出的最后部分,会打印出后续导入需要使用的last-value。当周期性执行导入时,应该用这种方式指定–last-value参数的值,以确保只导入新的或修改过的数据。可以通过一个增量导入的保存作业自动执行这个过程,这是适合重复执行增量导入的方式。
创建口令文件
echo -n "123456" > sqoopPWD.pwd hdfs dfs -mkdir -p /sqoop/pwd hdfs dfs -put sqoopPWD.pwd /sqoop/pwd hdfs dfs -chmod 400 /sqoop/pwd/sqoopPWD.pwd 可以在 sqoop 的 job 中增加: --password-file /sqoop/pwd/sqoopPWD.pwd
sqoop import --connect jdbc:mysql://node2:3306/sales_source --username root --password-file /sqoop/pwd/sqoopPWD.pwd --table sales_order --fields-terminated-by ' ' --lines-terminated-by ' ' --hive-import --hive-table ods.sales_order --incremental append --check-column entry_date --last-value '1900-1-1'
bin/sqoop import --connect jdbc:mysql://node-2:3306/qfbap_ods --username root --password root --table us_order --target-dir /qfbap/ods/bap_us_order --check-column update_time --incremental "append" --last-value 0 --num-mappers 1 --fields-terminated-by "�01"
create external table qfbap.bap_us_order(order_id bigint, order_no string, order_date date, user_id bigint, user_name string, order_money decimal, order_type int, order_status int, pay_status int, pay_type int, order_source string, update_time date ) partitioned by (date_time string) row format delimited fields terminated by "�01" ;
load data inpath '/qfbap/ods/bap_us_order' into table qfbap.bap_us_order partition(date_time=20190107) ;
–last-value,指定上一次导入中检查列指定字段最大值
–check-column : 用来指定一些列(可以是多个字段),这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系数据库中的自增字段及时间戳类似。这些指定列的类型不能使用任意字符类型,如char、varchar等类型都是不可以的;
–incremental,用来指定增量导入的模式,
append和lastmodified
(2)全量抽取
采用整体拉取的方式抽取数据。ETL通常是按一个固定的时间间隔,周期性定时执行,因此对于整体拉取的方式而言,每次导入的数据需要覆盖上次导入的数据。Sqop中提供了 hive-overwrite参数实现覆盖导入。 hive-overwrite的另一个作用是提供了一个幂等操作的选择。所谓幂等操作指的是其执行任意多次所产生的影响均与次执行的影响相同。这样就能在导入失败或修复bug后可以再次执行该操作,而不用担心重复执行会对系统造成数据混乱。具体Sqoop命令如下,其中 hive-import参数表示向hive表导入,hive- table参数指定目标hive库表。
-- 全量导入hive表 sqoop import --connect jdbc:mysql://node2:3306/sales_source --username root --password-file /sqoop/pwd/sqoopPWD.pwd --table sales_order --fields-terminated-by ' ' --lines-terminated-by ' ' --hive-import --hive-table ods.sales_order --hive-delims-replacement ' '
bin/sqoop import --connect jdbc:mysql://node-2:3306/qfbap_ods --username root --password root --table code_category --target-dir /qfbap/ods/bap_code_category --hive-import --create-hive-table --hive-overwrite --num-mappers 1
–node2就是主机的映射地址,就是主机IP
–hive-import :指定是导入 Hive
–hive-table:导入 Hive 中的数据库名和表名
–hive-delims-replacement 导入到hive时
用自定义的字符替换掉
,
, and �1
create external table qfbap.bap_code_category ( first_category_id int, first_category_name string, second_category_id int, second_catery_name string, third_category_id int, third_category_name string, category_id int) row format delimited fields terminated by "�01" location "/qfbap/ods/bap_code_category" ;
load data inpath "/qfbap/ods/bap_code_category" into table qfbap.bap_code_category ;
4、使用场景
环境信息:CDH SandBox
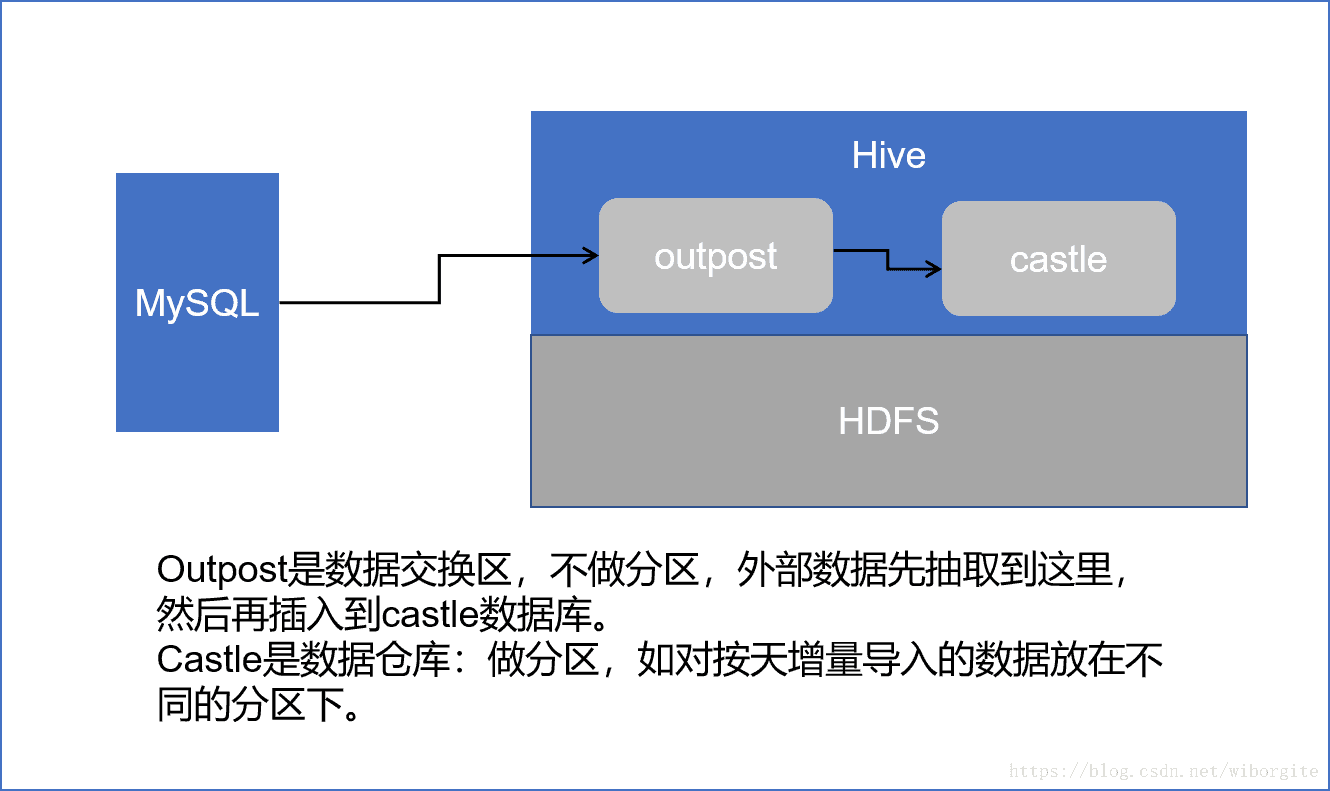
1. 在Mysql中创建一个customertest表,指定一个时间戳字段。
createtable customertest(id int,name varchar(20),last_mod timestampDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP);
2. 插入数据。
insertinto customertest(id,name) values(1,'neil');
insertinto customertest(id,name) values(2,'jack');
insertinto customertest(id,name) values(3,'martin');
insertinto customertest(id,name) values(4,'tony');
insertinto customertest(id,name) values(5,'eric');
3. 依次执行如下三个脚本:抽取脚本、建表脚本、加载脚本。
sqoop import
--connect jdbc:mysql://localhost:3306/wht
--username root
--password cloudera
--table customertest
--as-textfile
--target-dir /user/data_exchange/customertest/20180623
--fields-terminated-by \t
--delete-target-dir
DROP TABLE IF EXISTS OUTPOST.customertest;
CREATE EXTERNAL TABLE OUTPOST.customertest (
id INT COMMENT '',
name VARCHAR(255) COMMENT '',
last_mod TIMESTAMP COMMENT ''
)
COMMENT 'car备注'
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES('field.delim'=' ', 'serialization.encoding'='GBK')
STORED AS TEXTFILE;
DROP TABLE IF EXISTS CASTLE.customertest;
CREATE TABLE CASTLE.customertest (
id INT COMMENT '',
name VARCHAR(255) COMMENT '',
last_mod TIMESTAMP COMMENT ''
)
COMMENT 'customertest备注'
PARTITIONED BY (PARTITION_VAR STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '�01'
STORED AS PARQUET;
ALTER TABLE outpost.customertest SET LOCATION '/user/data_exchange/customertest/20180623';
ALTER TABLE castle.customertest DROP IF EXISTS PARTITION(PARTITION_VAR='20180623');
INSERT INTO TABLE castle.customertest PARTITION(PARTITION_VAR='20180623')
SELECT
id,
name,
last_mod
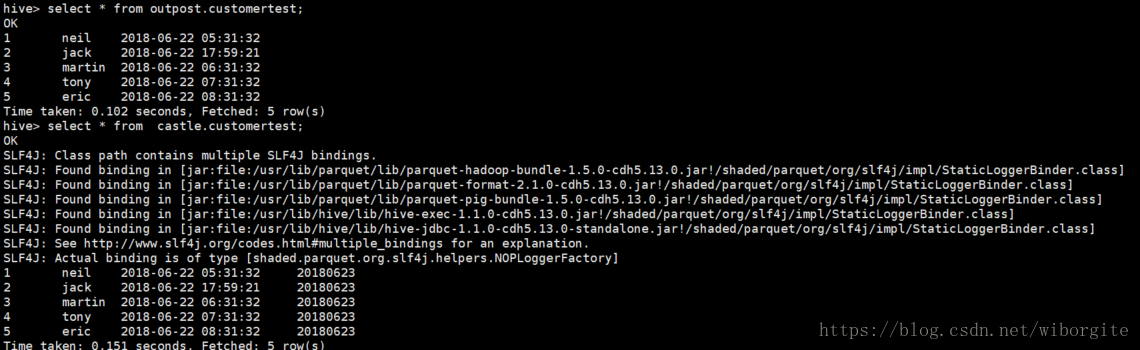
FROM outpost.customertest;4. 查询结果。
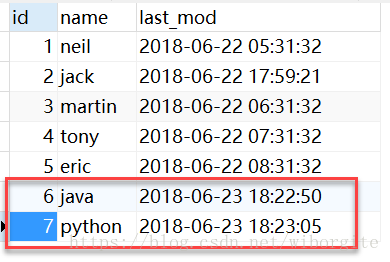
5. 在MySQL中插入新的记录。
6. 依次执行如下两个脚本,增量导入数据。
sqoop import
--connect jdbc:mysql://localhost:3306/wht
--username root
--password cloudera
--table customertest
--columns "id,name,last_mod"
--check-column last_mod
--incremental lastmodified
--last-value "2018-06-22 23:59:59"
--as-textfile
--target-dir /user/data_exchange/customertest/20180624
--fields-terminated-by \t
-m 1
--appendALTER TABLE outpost.customertest SET LOCATION '/user/data_exchange/customertest/20180624';
ALTER TABLE castle.customertest DROP IF EXISTS PARTITION(PARTITION_VAR='20180624');
INSERT INTO TABLE castle.customertest PARTITION(PARTITION_VAR='20180624')
SELECT
id,
name,
last_mod
FROM outpost.customertest;7. 查询结果。
