内连接查询
创建suppliers
-- 创建suppliers CREATE TABLE suppliers ( s_id int not null auto_increment, s_name char(50) not null, s_city char(50) null, s_zip char(10) null, s_call char(50) not null, primary key (s_id) );
创建fruits
-- 创建fruits CREATE TABLE fruits ( f_id CHAR(10) not null, s_id int not null, f_name CHAR(255) not NULL, f_price DECIMAL(8,2) not NULL, PRIMARY KEY(f_id) );
两张表都有s_id字段
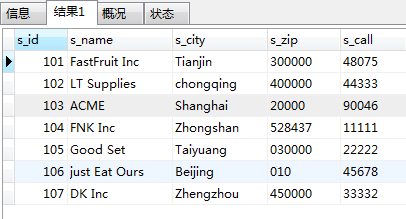
INSERT into suppliers (s_id,s_name,s_city,s_zip,s_call) VALUES (101,'FastFruit Inc','Tianjin','300000','48075'), (102,'LT Supplies','chongqing','400000','44333'), (103,'ACME','Shanghai','20000','90046'), (104,'FNK Inc','Zhongshan','528437','11111'), (105,'Good Set','Taiyuang','030000','22222'), (106,'just Eat Ours','Beijing','010','45678'), (107,'DK Inc','Zhengzhou','450000','33332');
INSERT INTO fruits (f_id,s_id,f_name,f_price) VALUES ('a1',101,'apple',5.2), ('b1',101,'blackberry',10.2), ('bs1',102,'orange',11.2), ('bs2',105,'melon',8.2), ('t1',102,'banana',10.3), ('t2',102,'grape',5.3), ('o2',103,'cocount',9.2), ('co',101,'cherry',3.2), ('a2',103,'apricot',2.2), ('l2',104,'lemon',6.4), ('b2',104,'berry',7.6), ('m1',106,'mango',16.5), ('m2',105,'xbabay',2.6), ('t4',107,'xbababa',3.6), ('m3',105,'xxtt',11.6), ('b5',107,'xxxx',3.6)
SELECT f_id,suppliers.s_id,fruits.s_id,s_name,f_name,f_price from fruits,suppliers where fruits.s_id=suppliers.s_id

使用内连接
SELECT f_id,suppliers.s_id,fruits.s_id,s_name,f_name,f_price from fruits INNER JOIN suppliers on fruits.s_id=suppliers.s_id
或者,逗号分隔
SELECT f_id,suppliers.s_id,fruits.s_id,s_name,f_name,f_price from fruits,suppliers where fruits.s_id=suppliers.s_id
最终结果和上面的查询结果一模一样.
使用where子句定义连接条件比较简单明了,而inner join 语法是ansi sql的标准规范,使用inner join 连接语法能够确保
不会忘记连接条件,而且,where子句在某些时候会影响查询的性能.
自连接查询
如果在一个连接查询中,涉及到的两个表都是同一个表,这种查询称为自连接查询.自连接是一种特殊的内连接,
它是之相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表.
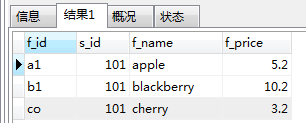
查看f_id='a1'的水果供应商提供其他水果种类
SELECT f1.f_id,f1.f_name,f1.s_id,f2.s_id,f2.f_id,f2.f_name from fruits as f1,fruits as f2 where f1.s_id=f2.s_id and f2.f_id='a1';

上面的意思可以用这个sql语句表示
SELECT * from fruits where s_id=101
外连接查询
外连接查询分为左外连接和又外连接
left join(左连接):返回包括左表中的所有记录和右表中连接字段相等的记录
right join(右连接):返回包括右表中的所有记录和右表中连接字段相等的记录.
-- 创建表customers CREATE TABLE customers ( c_id int not null auto_increment, c_name CHAR(50) not NULL, c_address CHAR(50) NULL, c_city CHAR(50) NULL, c_zip CHAR(50) NULL, c_contact CHAR(50) NULL, c_email CHAR(255) NULL, PRIMARY KEY(c_id) );
插入数据:
-- 插入数据 insert into customers (c_id,c_name,c_address,c_city,c_zip,c_contact,c_email) VALUES (10001,'RedHook','200 Street','Tianjin','300000','LiMing','LMing@163.com'), (10002,'Stars','333 Fromage Lane','Dalian','116000','Zhangbo','jerry@hotmail.com'), (10003,'Nethood','1 Sunny Place','Qingdao','266000','LuoCong',null), (10004,'JOTO','829 Riverside Drive','Haikou','570000','YangShan','sam@hotmail.com');
-- 创建表 CREATE TABLE orders ( o_num int not null auto_increment, o_date datetime not null, c_id int not null, PRIMARY key (o_num) );
-- 插入数据 INSERT into orders (o_num,o_date,c_id) VALUES (30001,'2008-09-01',10001), (30002,'2008-09-12',10003), (30003,'2008-09-30',10004), (30004,'2008-10-03',10005), (30005,'2008-10-08',10001)
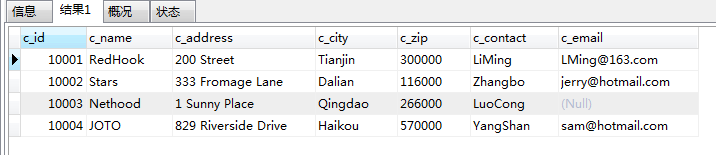
SELECT * from customers;

SELECT * from orders;

左连接查询:
SELECT customers.c_id,orders.o_num from customers LEFT OUTER JOIN orders on customers.c_id=orders.c_id;
也可以写成这样(去除outer)
SELECT customers.c_id,orders.o_num from customers LEFT JOIN orders on customers.c_id=orders.c_id;
结果是一样的;
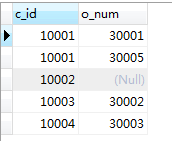
以左表为主表,拿左表中的每一项和右表中的每一项匹配,只要匹配成功,就显示,如果没有匹配上的,右表中的字段就显示null
此时有可能出现多条重复的左表数据,因为有多条数据匹配上,
左连接查询出的数据大于等于主表的数据条数.
右连接是左连接的反向连接,将返回右表的所有行为,如果右表的某行在左表中没有匹配的行,左表将返回空值
SELECT * from customers;
SELECT * from orders;
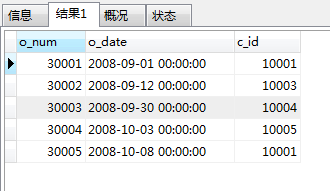
SELECT customers.c_id,orders.o_num from customers right JOIN orders on customers.c_id=orders.c_id;
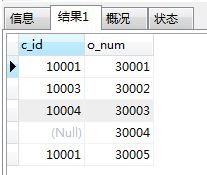
主表是右表,拿右表中的每一项和左表匹配,匹配到了就显示左表和右表的相应字段,如果没有匹配到,就显示左表字段为空值.
带some,any关键字的子查询:
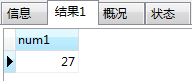
-- 创建表 CREATE TABLE tb1(num1 int not NULL); create table tb2(num2 int not null); -- 插入数据 INSERT into tb1 VALUES (1),(5),(13),(27); insert into tb2 VALUES (6),(14),(11),(20);
返回tb2表中的所有num2的列,然后将tb1中的num1的值与之进行比较,只要大于num2的任何一个值,即位符合条件的结果.
select num1 from tb1 where num1>SOME (SELECT num2 from tb2);
或者:
select num1 from tb1 where num1>ANY (SELECT num2 from tb2);

带all的查询;返回tb1表中比tb2表num2列所有值都大的值,
select num1 from tb1 where num1>ALL (SELECT num2 from tb2);
带exists关键字的子查询;如果exists返回true,外层查询将进行查询;如果子查询没有返回任何行,那么exists返回false,此时外层语句将不进行查询.
查询suppliers表中是否存在s_id=107的供应商,如果存在,则查询fruits表中的记录.
SELECT * FROM suppliers
SELECT * FROM fruits WHERE EXISTS (SELECT s_name from suppliers WHERE s_id=107)
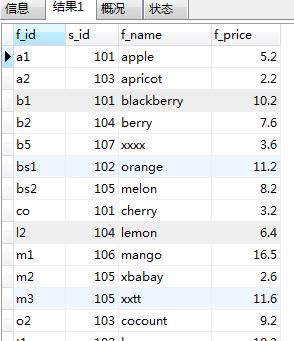
如果把107改成1090就无法查询到数据了.
查询suppliers表中是否存在s_id=107的供应商,如果存在,则查询fruits表中的f_price大于10.2的记录,sql语句如下:
SELECT * FROM fruits WHERE f_price>10.2 AND EXISTS (SELECT s_name FROM suppliers WHERE s_id=107)
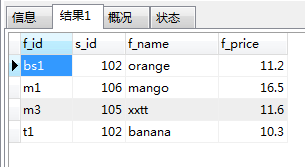
no exists与exists使用相同,返回的结果相反.子查询如果至少返回一行,那么not exists的结果为false,此时外层查询语句将不进行查询;如果子查询没有返回任何行业,那么not exixts返回的结果是true.此时外层语句将进行查询.
按照上面的逻辑,把上面的代码进行修改就应该获取不到数据了.
SELECT * FROM fruits WHERE NOT EXISTS (SELECT s_name from suppliers WHERE s_id=107)

合并查询;
union 删除重复项
union all 合并所有的项.不需要删除重复项
SELECT count(*) FROM fruits WHERE f_price<9.0;
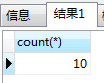
SELECT COUNT(*) FROM fruits WHERE s_id IN (101,103);
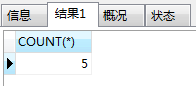
SELECT s_id,f_name,f_price FROM fruits WHERE f_price <9.0 UNION ALL SELECT s_id,f_name,f_price FROM fruits WHERE s_id IN (101,103);

将多个select语句的结果组合成一个结果集合.
这数据刚好有15条.