一、简介
1.Natural Language ToolKit(NLTK) 自然语言处理包:是一个用于自然语言处理和文本分析的综合性python库。用于NLP的研究和开发。
2.NLTK 文档和API 可在http://text-processing.com. 查看。
3.Tokenization(标记化)标记化是将字符串拆分成一个片段或标记列表的过程。一个符号是一个整体的一部分,所以一个单词是一个句子中的一个标记,而一个句子是一个段落中的一个标记。
4.WordNet:一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。是为自然语言处理系统编程访问而设计的词典。
它有许多不同的用例:
比如 查找单词的定义、寻找同义词(synonyms)和反义词(antonyms)、探讨词的关系与相似性、具有多种用途和定义的词的词义消歧。
NLTK包含一个Wordnet语料库阅读器(WordNet corpus reader),我们将使用它来访问Wordnet。语料库只是一个文本,而语料库阅读器的目的是使访问一个语料库比直接文件访问容易得多。
二、做好准备
安装NLTK前需要安装python环境,我电脑win10装的是python3.6 64位。编译器安的是pyCharm
这里我以pyCharm安装NLTK为例,如果不用编译器下载,则访问下面的网址下载安装
官网链接:http://www.nltk.org/
安装步骤:http://www.nltk.org/install.html
下载地址:https://pypi.python.org/pypi/nltk
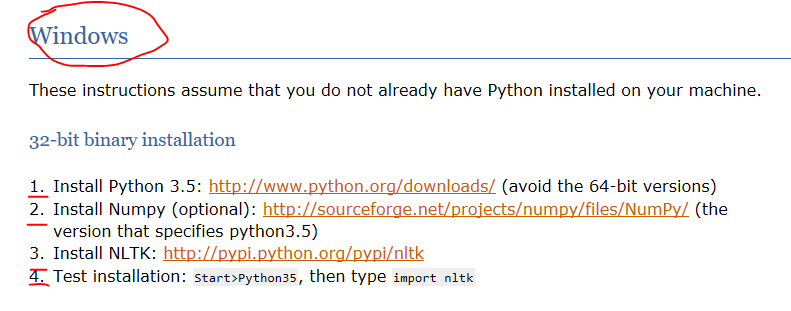
第一步先装python。第二步装NumPy。
第三步装NLTK 时 会报如下错误(现在还没搞明白) 果断弃坑,转用pyCharm安装
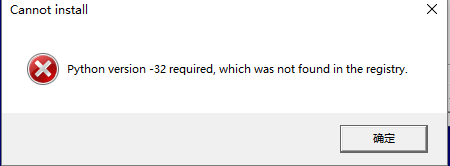
1.打开编译器-》File-》settings 出现如下图界面
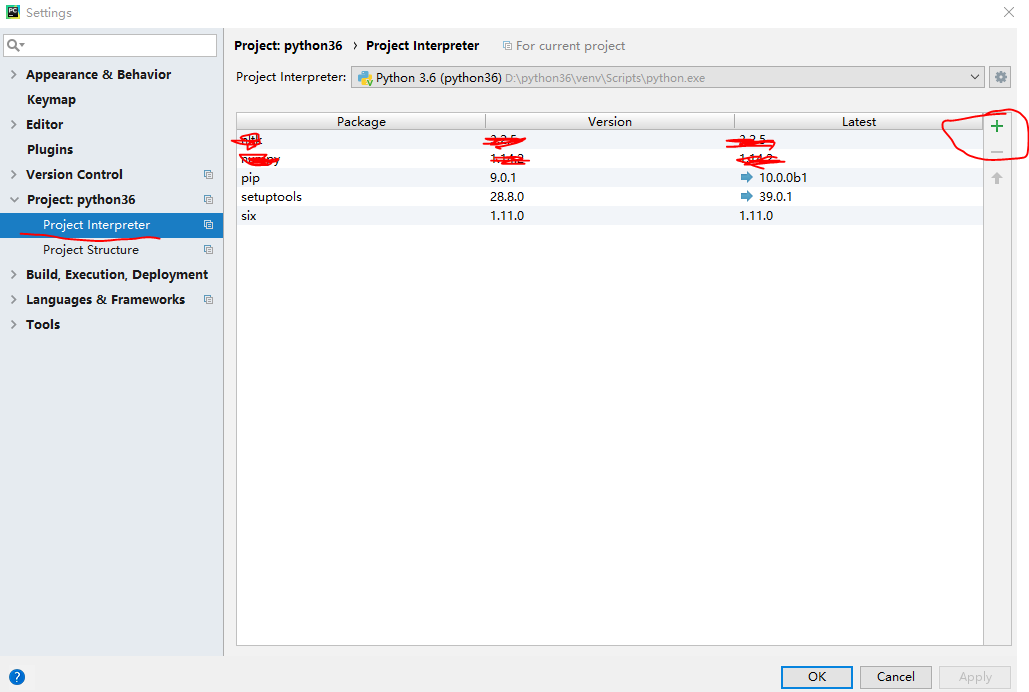
点击红圈绿色的加号,显示下图页面,搜索numpy-》点右下角安装
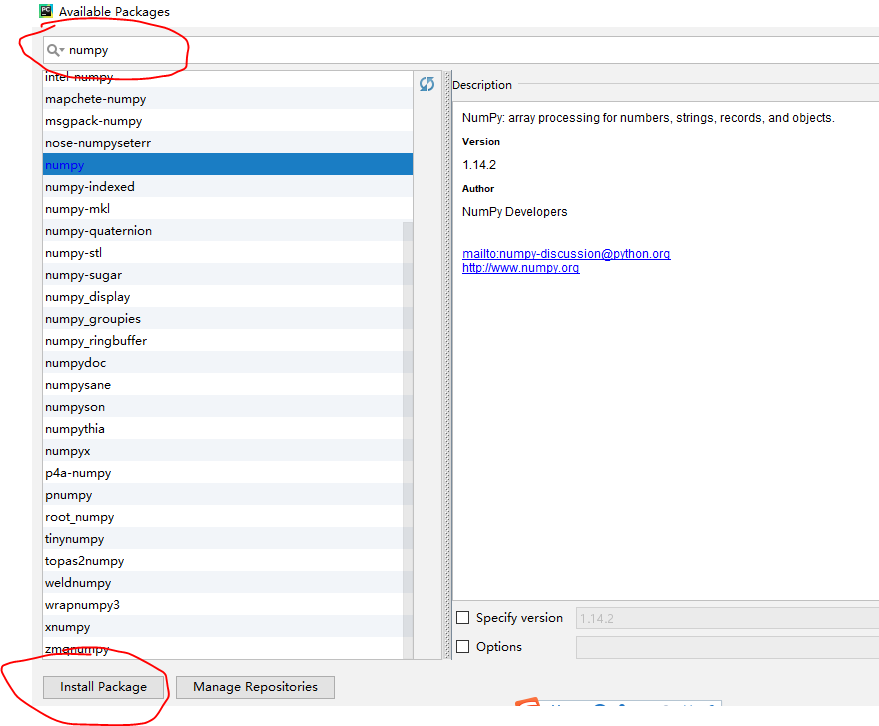
numpy安装完后,继续搜索nltk安装,都安装好后如下图
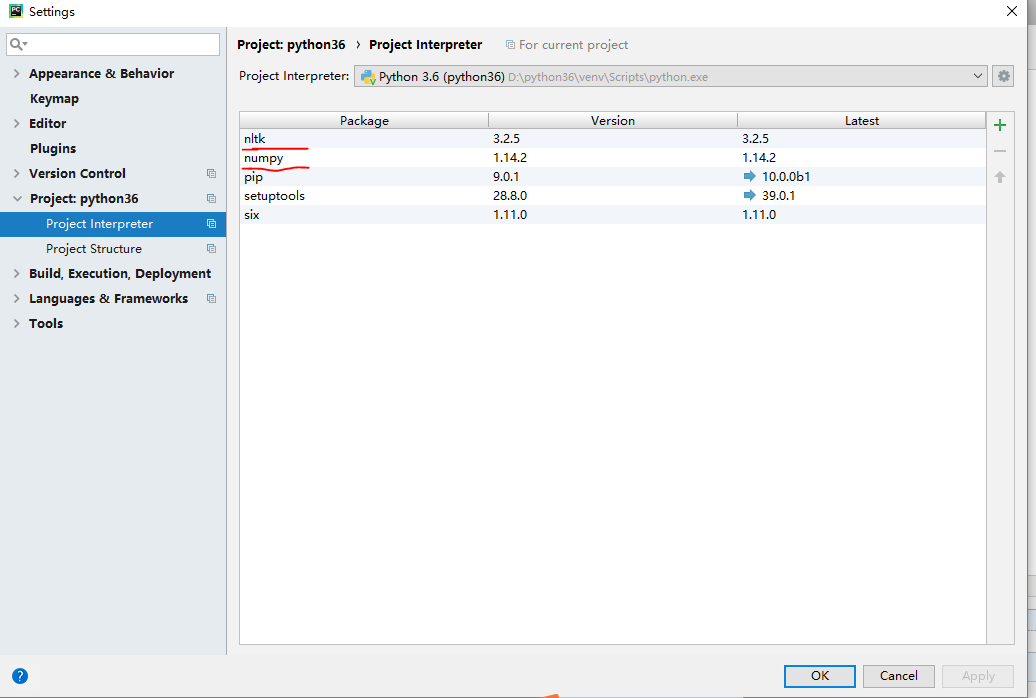
继续,新建个test.py 输入如下代码
1 import nltk 2 nltk.download()
用来下载 nltk data
点击运行test.py 会弹出如下页面
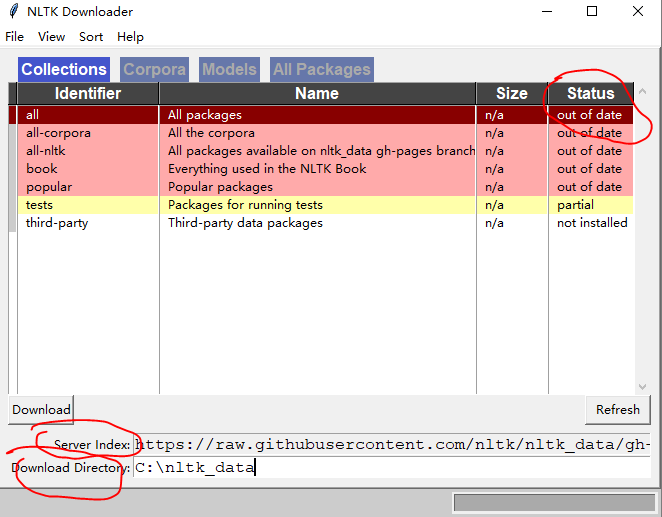
Server Index 将默认地址改为http://www.nltk.org/nltk_data/
Download Directory可以选择默认c盘,也可以改成 下面任意一个目录(因为查找是按下面文件顺序查找的)
- 'C:\Users\dell/nltk_data'
- 'C:\nltk_data'
- 'D:\nltk_data'
- 'E:\nltk_data'
- 'D:\python36\venv\nltk_data'
- 'D:\python36\venv\lib\nltk_data'
- 'C:\Users\dell\AppData\Roaming\nltk_data'
选all 是全部都下载,相当慢应该要两天时间,也可以每次只下载要用的部分。
点击Download(因为我之前下过,所以状态Status为out of date,如果是第一次安状态都为 not installed)
如果嫌麻烦 也可以从百度云盘分享我下好的nltk data 链接:https://pan.baidu.com/s/1d64mVhAbMBh3U3bw34XlfA 密码:64ey
百度云盘下载完后只需将解压移动到
- 'C:\Users\dell/nltk_data'
- 'C:\nltk_data'
- 'D:\nltk_data'
- 'E:\nltk_data'
- 'D:\python36\venv\nltk_data'
- 'D:\python36\venv\lib\nltk_data'
- 'C:\Users\dell\AppData\Roaming\nltk_data'
任意目录下就可以了。
上述步骤完成后可以敲入如下代码
from nltk.book import *
运行结果如下图说明成功

下载我百度云盘里的,运行时可能会报如下错误

找不到punkt资源
只需再单独下载punkt就可以了,代码如下
1 import nltk 2 nltk.download('punkt')