概述
最近几年微服务火的一塌糊涂,先是从dubbo开始,之后火的是spring cloud,spring cloud整合了非常多的组件,比如注册中心eureka,rpc远程调用组件feign,负载均衡组件ribbon,熔断限流工具hystrix,网关zuul,以及配置中心,上面提到的大多数组件都是Netflix公司开源的,但是上面的很多工具多多少少都有些问题,而且有些都已经停止更新了,比如我们这篇文章谈的eureka,只有1.0版本,2.0版本就没有维护了,在之后呢?号称具有地表最强java团队的阿里开源了非常多的组件,用于微服务,比如注册中心和配置中心nacos,熔断限流工具sentinel等,所以以后的趋势就是spring cloud alibaba,所以不得不说alibaba,就是牛逼。
本文讲述主要内容
1.eureka可以做注册中心,他是如何处理服务注册和服务发现的
2.eureka的心跳机制是如何决定一个服务下线的
3.eureka的自我保护机制是什么玩意
4.eureka为什么符合AP原则,而不是像zookeeper那样符合CP原则
5.eureka在生产环境如何调优
带着上面的几个问题,来学习eureka
eureka作为注册中心,基本原理
eureka是如何实现服务注册和服务发现的,eureka中会维护一个服务注册表,这个服务注册表是放在eureka服务的内存中的,如果eureka是一个集群部署的,那eureka在每个节点中都维护一套服务注册表,并且尽量同步成一致(这里为什么不说所有的服务注册表都一样,这个就是问题4要讲的内容,eureka符合AP原则),然后每个客户端会从eureka服务端定时拉取这个服务注册表放到自己的内存中,每次拉取更新一下,然后客户端如果要调用别的服务直接从自己本地的服务注册表中就可以找到要调用服务的地址和端口信息。
ok,有了上面的大致理解,来看一下eureka底层到底是如何做的,看下图。
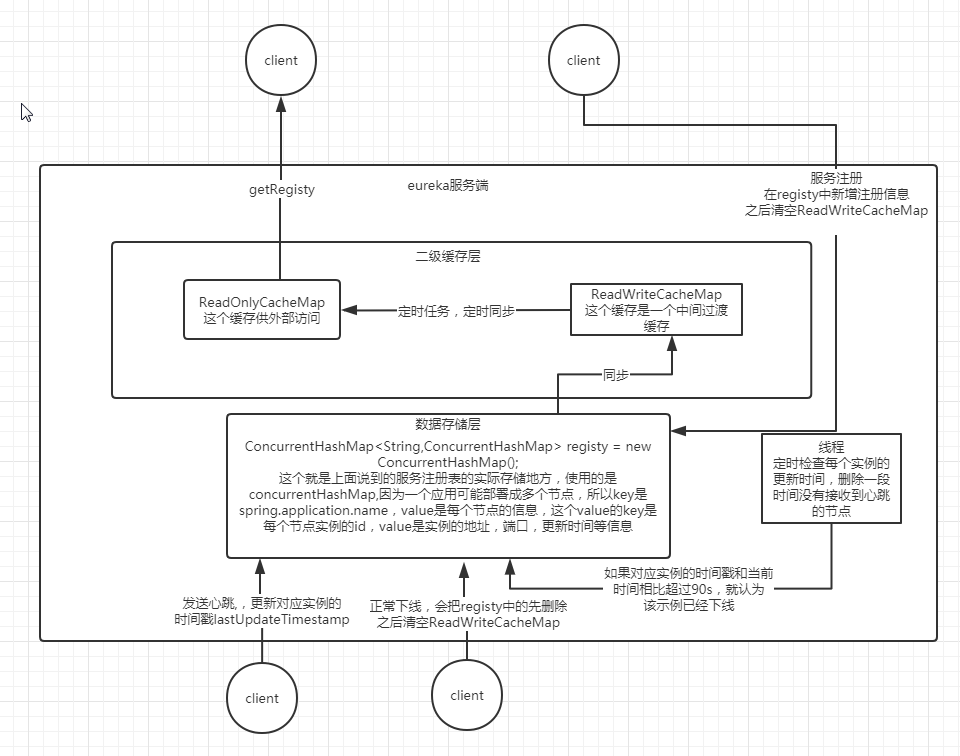
上图就是eureka内部数据结构以及交互过程,下面具体讲一下(上图中线程定时检测下线的服务的时间默认不是90s,而是60s,写错了)
从上图可以看出,eureka的存储结构中并不是只有一个,而是分两块,一块是数据存储层,一块是二级缓存层,那为什么要分两块呢?直接搞一个存储结构不更加简单,这么做的原因其实是为了读写分离,ReadOnlyCacheMap这个其实是一个ConcurrentHashMap,主要的作用就是负责客户端获取服务注册表的时候返回给客户端。服务注册其实是不和他交互的,而是直接和registy交互。如果不设计成这样,那就要加锁,这里就涉及到读锁和写锁,会导致系统设计复杂和降低读写的性能。
服务注册过程
- 保存服务信息,将服务信息保存到 registry 中;
- 更新队列,将此事件添加到更新队列中,供 Eureka Client 增量同步服务信息使用。
- 清空二级缓存,即 readWriteCacheMap,用于保证数据的一致性。
- 更新阈值,供剔除服务使用。
- 同步服务信息,将此事件同步至其他的 Eureka Server 节点。
上面的几个过程大家看了之后估计会有下面几个疑问?
第2步:将事件更新到队列中,上图中没有画队列啊,那队列在哪里?
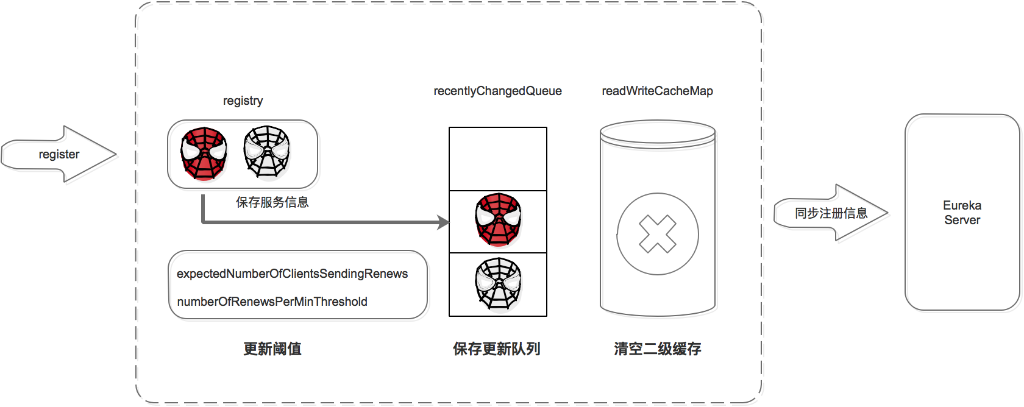
上图是从别的文章盗的,其实在eureka中是有维护一个队列的,这个队列是当客户端进行同步注册表的时候才会用到,下面讲到服务发现的时候会讲到这个队列的作用。
第3步:清空readWriteCacheMap,为什么要清空,而不是直接把服务注册信息同步到readWriteCacheMap?
readWriteCacheMap,这个缓存其实不是ConcurrentHashMap,而是google开发的guava,这玩意就是一个内存中的key-value缓存,里面包括key的失效机制等。其实我也不明白eureka为什么这么设计,直接一下全部清空里面的key-value,其实对于服务注册来说,完全可以不处理这个,当有客户端来同步这个服务的时候,再从registy中同步到readWriteCacheMap中就可以了。
第4步:更新阈值,这个阈值又是什么?
这个说起来就复杂了,这是eureka的一个自我保护机制,可以同步配置来配置是否开启。
- 自我保护阈值 = 服务总数 * 每分钟续约数 * 自我保护阈值因子。
- 每分钟续约数 =(60S/ 客户端续约间隔)
最后自我保护阈值的计算公式为:
自我保护阈值 = 服务总数 * (60S/ 客户端续约间隔) * 自我保护阈值因子。
举例:如果有 100 个服务,续约间隔是 30S,自我保护阈值 0.85。
自我保护阈值 =100 * 60 / 30 * 0.85 = 170。
如果上一分钟的续约数 =180>170,则说明大量服务可用,是服务问题,进入剔除流程;
如果上一分钟的续约数 =150<170,则说明大量服务不可用,是注册中心自己的问题,进入自我保护模式,不进入剔除流程。
这个自我保护机制怎么说呢,如果真是因为网络问题,导致很多节点的心跳接收都失败,这时候eureka不进行服务剔除是可以理解的,这是一种很好的保护系统的方法,但是如果不是因为网络问题,而是确实要下线那么多服务,这个就很鸡肋了。
服务下线检测
在上图中,有一个单独的线程定时会去遍历registy,找出实例的lastUpdateTimestamp,判断这个时间和当前时间的间隔,比如超过60s,就认为该服务异常了,但是这时候并不能随便下线哦,上面已经讲了eureka的自我保护机制,这里其实就是在每个检测周期内看一下需要线下的节点数量有没有超过阈值,如果没有超过,就直接下线,如果超过阈值就会启动自我保护机制。
服务获取过程
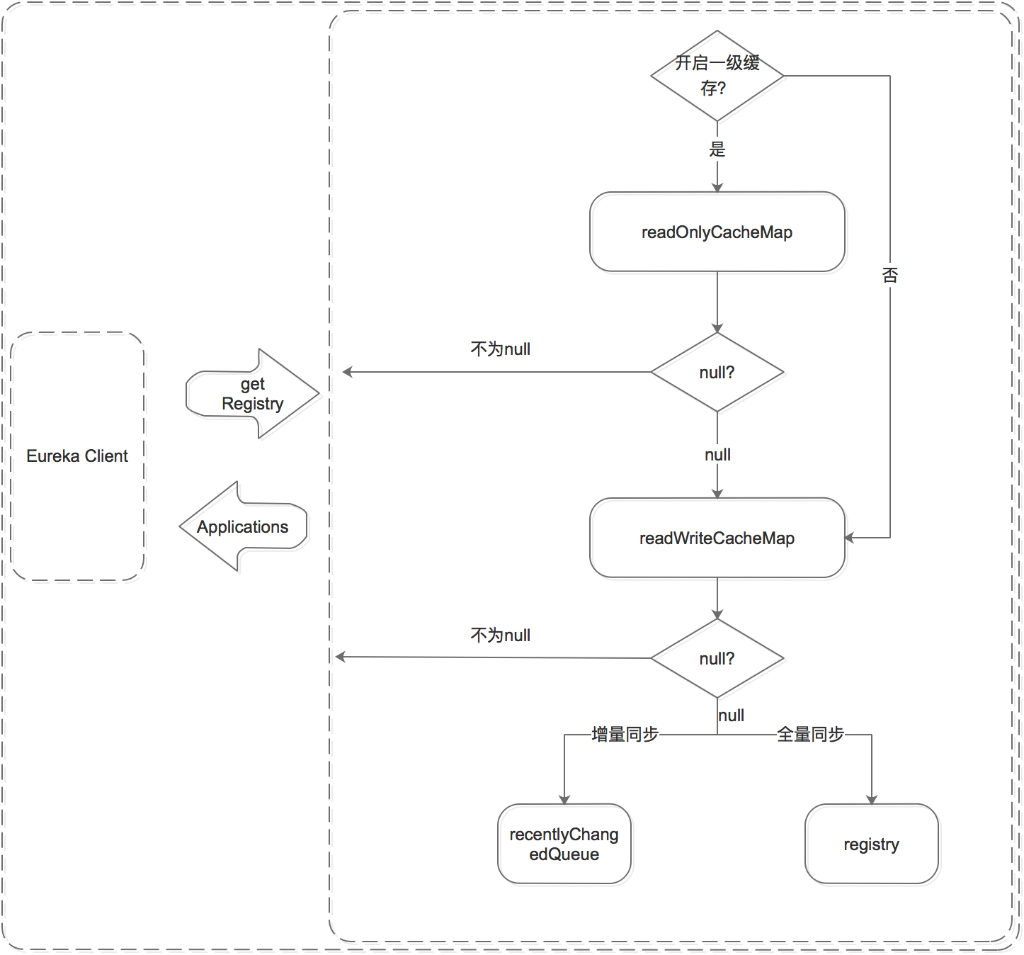
上图很详细的画出了获取服务的过程,我就不叙述了,这里还记的上面那个问题吗就是队列的作用?
从上图可以看出,这里从registy同步到readWriteCacheMap的过程有两种方法,一个是增量,一个是全量,全量就不说就是直接全部弄过去就可以了,这里说一下增量,因为每次注册服务都会把服务也放到队列中一份,所以如果要增量同步的时候,直接从队列中获取就可以了。
eureka符合AP原则
eureka的设计,就是集群中的每个节点都是对等的,保证每个节点的数据最终一致性,但是并不能保证强一致性,举个例子,服务在注册的时候是向eureka集群中的一个节点注册的,之后这个节点再异步的把注册的信息同步到其他节点,如果还没有同步到其他节点,这个节点就挂了,那么这个注册信息就丢失了,但是这并不妨碍eureka的使用,但是这就不能保证一致性了,就是剩下的节点的注册表中其实是缺失的,那为什么说是最终一致性呢?注册失败的服务会重新选择一个节点注册,保证最后可以注册成功,然后同步到所有的节点(这里注意:是这一个节点向所有的节点同步,而不存在传递,比如A服务->B服务 ,A服务->C服务,但是不能A服务->B服务,B服务->C服务),这就是最终一致性,这样设计还是可以接受的。
zookeeper也是可以作为注册中心的,但是zookeeper的设计是符合CP原则的,zookeeper可以保证一致性,但是不能保证可用性,因为zookeeper中有一个主节点,如果主节点挂了,那就会启动选主过程,这个过程要持续几十秒,在这几十秒中整个集群是不可以使用的,由于都是集群设计方式,那分区容错性自然都满足。
eureka生产环境调优
由于eureka的默认的一些参数设置的有些不合理,如果不做任何处理,直接部署到生产环境,可能会有很大的问题,首先第一个问题,就是服务发现时间过长的问题,比如一个服务注册成功,首先从ReadWriteCacheMap定时同步到ReadOnlyCacheMap,这个定时任务的默认间隔是30s,而客户端拉去服务注册表默认也是30拉去一次,这样一来一个服务从注册到发现都要1分钟,时间太长,可以将这个时间调小一点,比如调整成2s。
还有eureka中的线程定时检测心跳异常的那个定时任务,时间间隔也太长,默认是60s执行一次,那如果一个服务异常了要等到这么久才可以发现,太恐怖了。下面就是具体一些可以调整的参数。
#扫描失效服务的间隔时间(单位毫秒,默认是60*1000)即60秒,这个是默认时间,改成6秒
eureka.server.eviction-interval-timer-in-ms= 6000
#从eureka服务器注册表中获取注册信息的时间间隔(s),默认为30秒
eureka.client.registry-fetch-interval-seconds=2
具体可以调优的参数参考:https://www.cnblogs.com/xmzJava/p/11359636.html
本文参考: