概述
由于innodb支持事务和行级别锁,使得mysql拥有更好的安全性和并发性,mysql从5.5版本已经把innodb引擎作为默认引擎,而且除非有一些非常特别的原因,不然innodb都是最优的选择
mysql架构

连接器:负责连接客服端和MySQL服务端,并且可以进行权限验证,保持连接等
查询缓存:看图大家可能有个疑问,为啥这个sql进来连解析都没有直接连接到查询缓存,先解释一下什么是查询缓存,查询缓存是用户之前查询的结果,缓存在这里,结构类似于key/value结构,其中key就是sql,value是查询结果,当有新的查询进来,先比较key,当key相同就直接返回结果,好,到这里相信很多人都会有个疑问,那如果存在更新怎么办,这里的缓存跟着更新吗?如果不更新那返回的不就是旧数据吗?没错,有这个疑问就对,MySQL这里做的很shadiao,就是如果有更新,就会把这玩意清空,缓存就没啥用了,那对于一个经常修改的数据库,这玩意基本没什么用,所以在MySQL8之后直接把这玩意给干掉了,没了,一了百了,干净利落。
解析器:这个应该不用解释,学过编译原理的都知道,高级语言是没法直接执行的,需要进行词法解析和语法解析之后才知道里面是什么意思,所以这玩意就是干这个的。
优化器:用过MySQL的都知道,mysql有个神奇的功能就是自动优化你的sql语句,有时你觉得你可以走索引,他偏偏搞一个全表扫描,就是这家伙干的,他会决定使用什么索引,来进行查询。
执行器:这个就不用解释,就是把上面解析过的sql提交给引擎执行
引擎:可以时各种各样的引擎,就是说mysql把server层固定好,剩下的引擎层可以插拔式更换
文件:mysql真正和文件打交道的其实是引擎,无论读写,数据都是会先放到引擎的缓存中的。
innodb架构
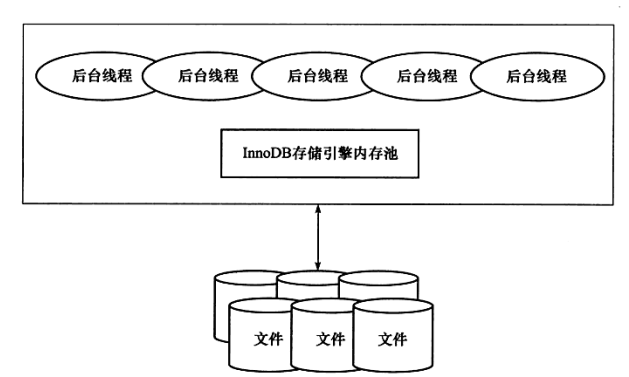
后台线程:innodb中是通过多线程执行,每个线程负责不同的事情,大致有如下这些线程
- master thread:这个是整个innodb的核心线程,主要会做如下几件事,第一、刷新脏页(什么,不知道这是什么,别急,后面会bb)到磁盘,第二、undo页(这个同上,别急)的回收,第三、合并插入缓存(insert buffer),估计大多数老兄看到上面完全陌生的概念都头大了,我看书(innodb引擎技术内幕)的时候也是这样,这就是看书比较困难的地方。
- io thread:innodb中使用了很多的aio(什么这个也不知道,其实我刚开始看的时候也不知道,哈哈哈,可以查查aio,nio,bio,书上作者也不解释,难受),其实aio就是异步io,异步io分为两种一种是aio,另一种就是nio,nio就是我一下子干了好几件事,然后我进行轮询看看哪个结束了,而aio就是我也一下子干了几件事,但是我不会去傻傻的轮询,我就坐那里等着(其实也可以干点别的,比如你懂的,哈哈哈),谁执行完了来通知我就可以了。上面解释那个浪费了点时间,下面就说说有几种io,大家可以自己想想MySQL需要和磁盘进行哪几种交互,第一、我要读数据(对应的就是read io thread)。第二、我要写数据(对应就是write io thread)。第三、我要写日志(对应就是log io thread注意这里写的不是binlog,binlog是server层写的,引擎层写的是redo log和undo log,至于这两者干啥的,后面会介绍)。第四、我要写索引(那对应的就是insert buffer io thread,insert buffer这个是老版本的叫法了,从1.0.x之后就升级为change buffer了)
- purge thread,这个也是把undo log回收的的线程,上面有一个log io thread,这两个应该是配合使用的,可以设置启动多个这个线程
- page clean thread:将脏页刷新到磁盘,这里先提一嘴,其实把由于innodb为了提高写的性能,把用户写的数据先不写道磁盘,而是写道内存中,这就造成了内存中页和磁盘中的页(别告诉我页是什么都不知道,我上一篇文章有介绍)不一样,所以内存中的那个页就叫做脏页,那既然不一样就要搞成一样啊 ,怎么搞,就是把这些脏页刷新到磁盘,这里写的这个线程就是干这个事情,其实可以干这个事情的有很多线程,master thread就可以干,后面详细介绍。
innodb存储引擎内存池:大家都知道磁盘,特别是机械硬盘,顺序读写还好,如果是随机读写,那性能就太低了,所以搞个缓存,所有的操作都在缓存中完成,之后在把缓存中的数据慢慢搞到磁盘上,我们不是dba一般生产上的数据库的参数一般也没有调过,但是我想大家应该都听说过innodb_buffer_pool_size,这个参数就是控制缓存大小的,搞得越大数据库的性能就越好。innodb缓存中存储的页如下:
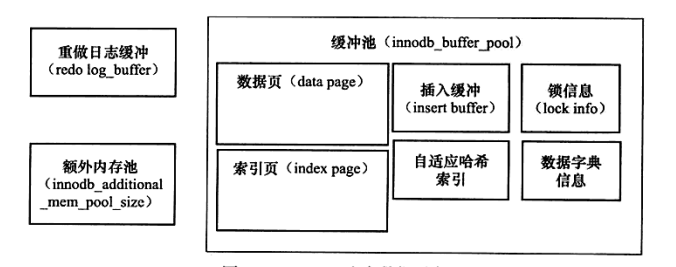
上图中有好多页,这里我不做过多的介绍,因为我也不太清楚每个页的具体情况,等我把innodb这本书读完或许可以知道答案,大家先不要纠结这里每个页是干啥的,知道里面放的都是一些页就可以了。下面介绍一下innodb是怎么管理这么大的一个区域的。
innodb是使用LRU(Latest Recent Used)算法进行管理的,其实redis中也有这个玩意,在Redis内存使用超过一定值的时候(一般这个值可以配置)使用的淘汰策略。
下面讲一下free list, lru list, flush list,LRU算法具体就是通过这三个结构实现管理。
- Free List:其上的节点都是未被使用的节点,如果需要从数据库中分配新的数据页,直接从上获取即可。InnoDB需要保证Free List有足够的节点,提供给用户线程用,否则需要从FLU List或者LRU List淘汰一定的节点。InnoDB初始化后,Buffer Chunks中的所有数据页都被加入到Free List,表示所有节点都可用。
- LRU List: 这个是InnoDB中最重要的链表。所有新读取进来的数据页都被放在上面。链表按照最近最少使用算法排序,最近最少使用的节点被放在链表末尾,如果Free List里面没有节点了,就会从中淘汰末尾的节点,把脏页刷新到磁盘。LRU List还包含没有被解压的压缩页,这些压缩页刚从磁盘读取出来,还没来的及被解压。LRU List被分为两部分,默认前5/8为young list,存储经常被使用的热点page,后3/8为old list。新读入的page默认被加在old list头,只有满足一定条件后,才被移到young list上,主要是为了预读的数据页和全表扫描污染buffer pool。
- FLUSH List: 这个链表中的所有节点都是脏页,也就是说这些数据页都被修改过,但是还没来得及被刷新到磁盘上。在FLU List上的页面一定在LRU List上,但是反之则不成立。一个数据页可能会在不同的时刻被修改多次,在数据页上记录了最老(也就是第一次)的一次修改的lsn,即oldest_modification。不同数据页有不同的oldest_modification,FLU List中的节点按照oldest_modification排序,链表尾是最小的,也就是最早被修改的数据页,当需要从FLU List中淘汰页面时候,从链表尾部开始淘汰。加入FLU List,需要使用flush_list_mutex保护,所以能保证FLU List中节点的顺序,其实有个有点不明白就是,如果lru list中部分脏页刷新到磁盘,这个里面如果页存在这个脏页会不会页刷新,还是怎么处理。
checkpoint
上面的描述中多次提到刷新脏页,其实innodb有个专门的技术来搞这个,叫做checkpoint.
设想一下,加入MySQL的缓存足够大,能不能搞成类似于reids一样,基于内存的读写操作,答案是可以的,但是你要有那么大的内存啊,数据库中存的数据往往都比较多,所以还是要定期把缓存中的数据清理一下到磁盘的,除了这个问题之外还有一个问题就是,你除了内存不够之外,如果日志一直写,会不会导致磁盘不够用,当然磁盘很便宜,可以加,但是也很麻烦,所以mysql就搞了要给checkpoint来清理磁盘和内存,checkpoint分两种:
- Sharp checkpoint:如果启用这个,就是当数据库关闭的时候会把所有的脏页刷新会磁盘,但是运行期间不会刷,这肯定不行。
- Fuzzy checkpoint:这种就是慢慢的刷新脏页到磁盘,具体Fuzzy checkpoint如下几种情况会发生。
Fuzzy checkpoint

Master Thread Checkpoint:每秒或者每十秒刷新一定的脏页回磁盘。
FLUSH_LRU_LIST Checkpoint:当lru列表的空间不足时,会刷新部分old list中的脏页回磁盘。
Async/Sync Flush Checkpoint:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
在checkpoint age(redo_lsn – checkpoint_lsn)大于async水位的时候触发Async Flush,大于sync水位的时候触发Sync Flush,保证刷完后age小于async水位。其实这段话简单来说就是当日志的版本高于一定量的checkpoint的版本的时候就会触发,这里的lsn就是一个版本号,占用8个字节,会逐渐增大。通过lsh可以获取如下几个信息:
- 数据页的版本信息。
- 写入的日志总量,通过LSN开始号码和结束号码可以计算出写入的日志量。
- 可知道检查点的位置。
Dirty Page too much Checkpoint:这个就是buffer size中的脏页占用的容量达到总容量的一定比例的时候就会触发,确保内存中有足够的可用空间。
redo log和undo log和binlog对比
先看一下日志的写入流程图
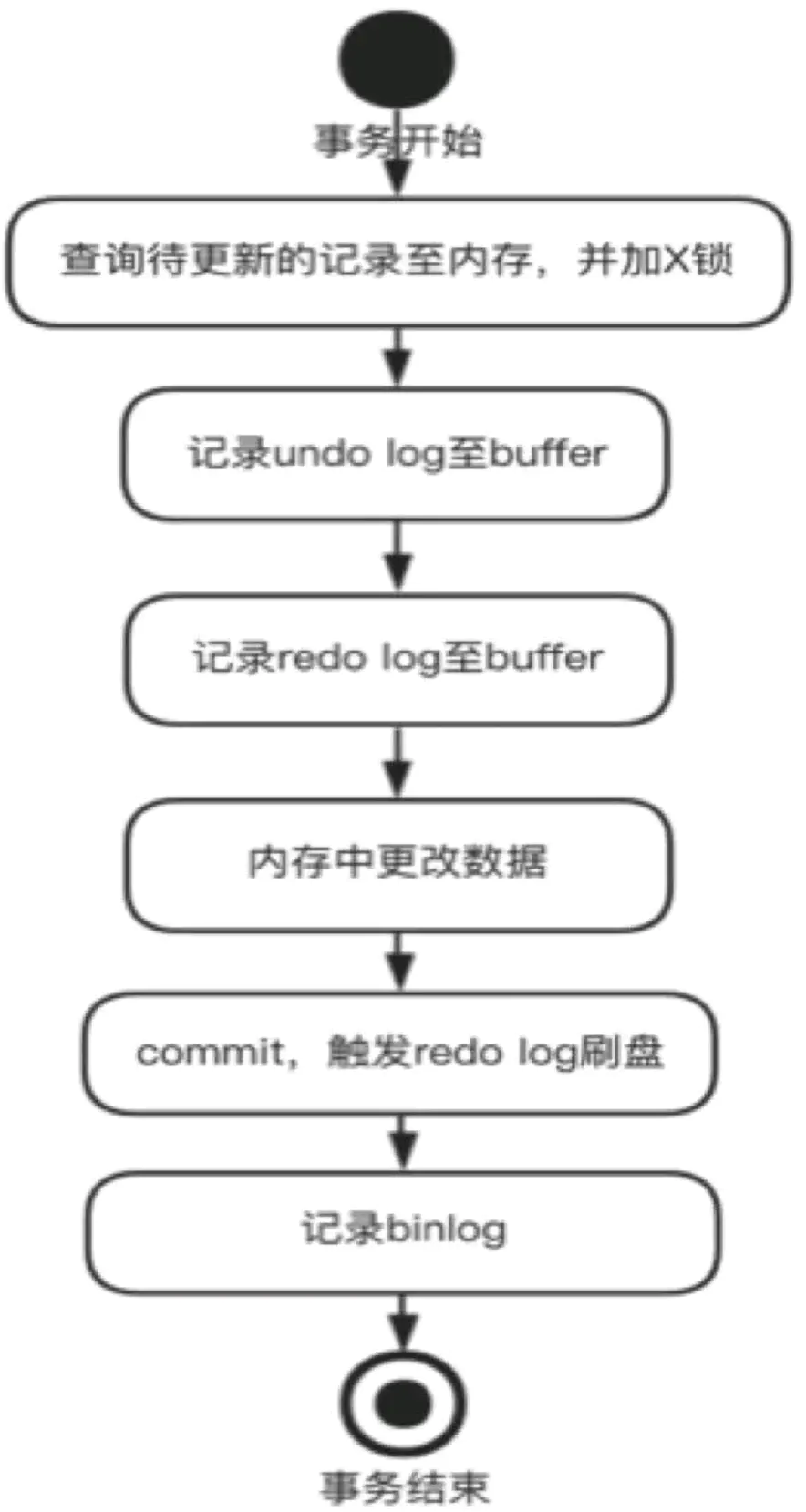
undo log:里面记录的是具体的操作逻辑,比如一个update语句,undo log中会记录操作之前的值是多少,修改之后是多少,那记录这玩意有什么用,有下面两种作用
- 事物回滚:当需要回滚事物的时候,由于redolog中已经记录了修改前的值,可以直接回滚。
- MVCC(多版本并发控制):大致介绍一下mvcc,mvcc是基于可重复度或者读已提交这两种事物隔离级别的(如果这两个不知道,可以先看一下mysql事物隔离级别),用户的操作都会处于一个版本链中,比如,一个更新操作事物还没有提交,来了一个读事物,那么这个读事物读到的版本就是这个更新操作之前的版本,类似于快照的功能,如果这个更新操作事物已经提交了,这个就变成了最新的版本,再次读取就会是修改之后版本。
redo log:redo log是物理日志,记录的是数据页的物理变化,主要用于数据库异常崩溃的数据恢复。
binlog:这个server层写的,也是逻辑日志,主要用于数据同步到从库,类似于mysql对外暴露的一个接口,供外部读取。
上面介绍完之后,很多人应该会有疑问?为什么mysql要搞那么多的日志,搞一个不行吗,我当时也有这个疑问,比如只搞一个binlog,不就可以了,其实这个事情是这样的,server层记录的binlog这个早就有了,他是独立于引擎层的,而redo log和undo log这两个是innodb中有的,那innodb内部为什么也搞了两个日志,这个主要还是用处不同吧。
innodb关键特性
Insert Buffer
插入缓冲和数据页一样,也是物理页的一个组成部分。
在B+树上数据是按照聚集索引的值顺序存放的,在非聚集索引中插入数据则是离散的,因此随机读取导致插入性能下降。InnoDB在非聚集索引的插入或者更新操作时,不是一次直接插入索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在则直接插入,若不在则放到一个Insert Buffer对象中,再通过一定频率进行Insert Buffer和辅助索引页子节点的merge操作,这样通常能够将多个插入合并到一个操作中(因为在同一个索引页中),提高非聚集索引的插入性能。
Insert Buffer的使用需要同时满足两个条件:
- 索引是辅助索引
- 索引不是唯一的
Insert Buffer在发生宕机的时候因为没有合并到非聚集索引中去,恢复可能需要很长时间。同时索引不是唯一的目的是为了避免去非聚集索引中判断唯一性,如果需要判断那么就需要离散读取,Insert Buffer就失去了意义。
InnoDB从1.0.x版本引入Change Buffer作为升级,对INSERT、DELETE、UPDATE操作都进行缓冲,对应Insert Buffer、Delete Buffer、Purge Buffer。对记录的Update操作分为两个过程:标记删除、真正删除,Delete Buffer对应第一个过程,Purge Buffer对应第二个过程。
Merge Insert Buffer可能发生在以下几种情况:
- 辅助索引页被读取到缓冲池时,如执行SELECT操作时,检查Insert Buffer Bitmap页确认该辅助索引页是否有记录存放在Insert Buffer B+树中
- Insert Buffer Bitmap页追查到该辅助索引页已经没有可用空间(小于1/32页)时,强制一个读取辅助索引页进行合并
- Master Thread
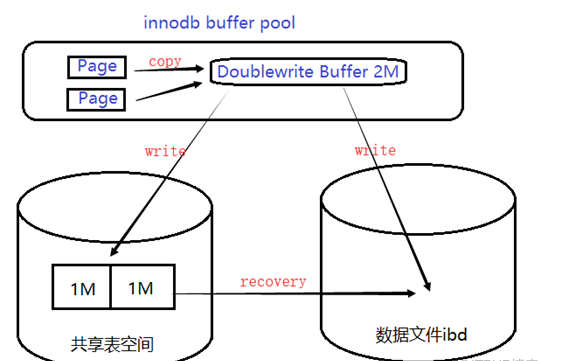
两次写
在写某个页到表中时发生宕机,页只写了部分,称为部分写失效。redo log是物理操作的记录,如偏移量800,写’aaaa’,因为页本身发生损坏,所以重做没有意义,因此需要一个页的副本,通过页的副本还原页,再进行重做,这就是doublewrite。
在对缓冲池的脏页进行刷新时,并不直接写磁盘,通过memcpy将脏页先复制到doublewrite buffer,之后通过doublewrite buffer分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后调用fsync函数同步磁盘,避免缓冲写带来的问题。当共享表空间写之后再把doublewrite buffer中的数据写入到数据文件中。
自适应哈希索引
构造AHI(Adaptive Hash Index)的要求是对页的连续访问模式必须是一样的,并且以该模式访问了100次,页通过该模式访问了N次,N=页中记录/16。
异步IO
用户请求可能需要扫描多个索引页,进行多次IO操作。在扫描完一个页后进行下一次扫描是没有必要的,用户可以在发出一个IO请求后立即再发出另一个IO请求,当全部IO请求发送完毕后等待所有IO操作完成,这就是AIO。
AIO的优势是可以进行IO Merge操作,将连续的IO操作合并为1个IO请求。
刷新邻接页
当刷新一个脏页时,InnoDB会检测该页所在的区(extent)的所有页,如果是脏页,则一起进行刷新,通过AIO可以合并成一个IO操作。这个对于早期的机械硬盘很有用,把多个临近的脏页一次性刷新到磁盘,可以减少磁盘io的次数,但是现在ssd硬盘的价格已经下降的非常低,这个功能以后估计没人使用了。