业余玩爬虫时,由原先的原生写法 改为 scrapy框架了,使用自带的selector时,xpath配合正则来抓取回复数和阅读数的时候,遇到的小问题,mark下。
首先获取到 我需要的数据块,(我用scrapy shell调试的)

对应的html文档是:

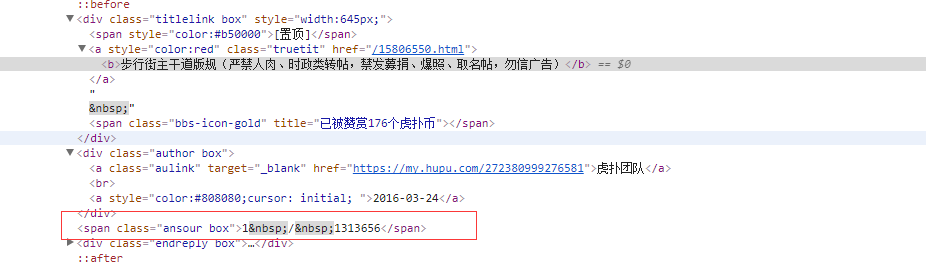
关于 这个 空格  被爬成了xa0的问题,我找了一些资料,这里说下原因:
xa0 叫做不间断空白符,英文描述non-breaking space,阻止在此处自动换行和阻止多个空格被压缩成一个,属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,我之所以用下列方法去不掉,是因为我们平常用的更多的 空格是x20,
如下方式取匹配我想要的阅读数和回复数都失败了

这里面就是因为 空格字符的影响,所以后来用针对空格的办法,/s 就没问题了

收集了网上的对付这种问题一些办法:如下
string.replace(u'xa0', u' ') ; strip()等,
附:unicode标点对应表,http://www.unicode.org/charts/PDF/U3000.pdf
2.因为有些加粗标题被包含<b></b>标签下,如下:
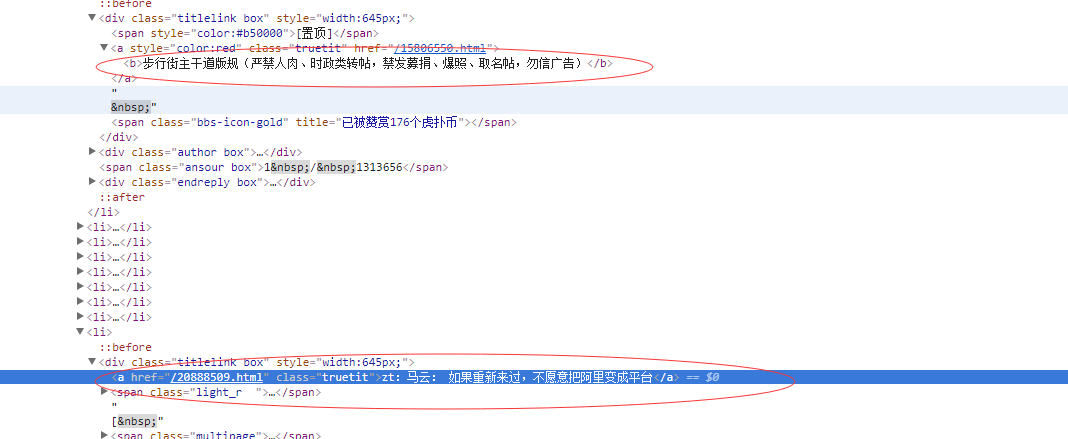

他在 多了一级的标签,用text()就取不到了,
但是xpath('string(.)')这个可以取出所有的文字元素,不包括html标签,

以上就是这次 业余抓取的小实录,好了,去拥抱下世界上最好的语言了 -。-