1.什么是泛型
泛型,即“参数化类型”。
创建集合时就指定集合元素的类型,该集合只能保存其指定类型的元素,避免使用强制类型转换。
Java编译器生成的字节码是不包涵泛型信息的,泛型类型信息将在编译处理时被擦除,这个过程即类型擦除。泛型擦除可以简单的理解为将泛型java代码转换为普通java代码,只不过编译器更直接点,将泛型java代码直接转换成普通java字节码。
类型擦除的主要过程如下:
1).将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。
2).移除所有的类型参数。
2.JAVA中的集合类以及关系图
List和Set继承自Collection接口。
Set无序不允许元素重复。HashSet和TreeSet是两个主要的实现类。
List有序且允许元素重复。ArrayList、LinkedList和Vector是三个主要的实现类。
Map也属于集合系统,但和Collection接口没关系。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
SortedSet和SortedMap接口对元素按指定规则排序,SortedMap是对key列进行排序。
-----------------------------------回顾一下各集合类--------------------------------------------------------------------------------------
List:
对于ArrayList和LinkedList的存储方式相对简单,默认情况下就是顺序存储,先添加的元素在前面,后添加的元素在后面,不同的是ArrayList底层是通过数组来维护,LinkedList底层是通过链表来维护。这两种方式都可以重复添加相同的元素,根据应用情况不同自行选择。
LinkedList类
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
ArrayList类
ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。
size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
Vector类
Vector非常类似ArrayList,但是Vector是同步的。由Vector创建的Iterator,虽然和ArrayList创建的Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
SET:
HashSet类
对于HashSet我们还应该知道HashSet实质是通过HashMap来实现的。我们应该为定义到HashSet中的对象定义hashCode和equals方法。在HashSet中并没有get方法,我们只能通过迭代器去访问其中的元素。
- 不能保证元素的排列顺序,顺序有可能发生变化
- 不是同步的
- 集合元素可以是null,但只能放入一个null
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相 等
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对 象通过equals方法比较返回true时,其hashCode也应该相同。
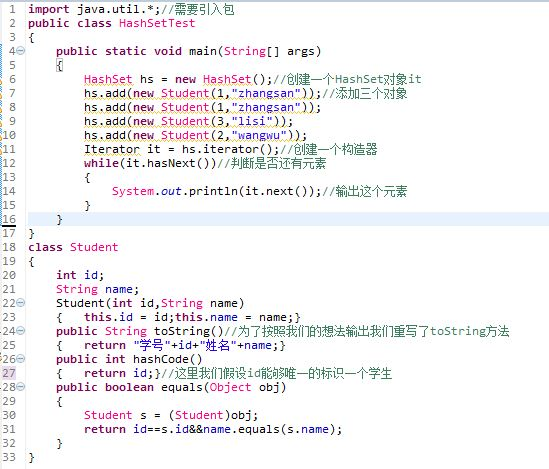
TreeSet类
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法
Map
HashMap
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。
HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力.
Map Collections.synchronizedMap(Map m)
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。
TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
在TreeMap中映射是以关键字的字母顺序存储的,而在HashMap中映射中存储顺序一般依赖于编译器,不同的编译器则最后生成的存储顺序不同。
TreeMap默认按key进行升序排序,如果想改变默认的顺序,可以使用比较器:
Map<String,String> map = new TreeMap<String,String>(new Comparator<String>(){ public int compare(String obj1,String obj2){ //降序排序 return obj2.compareTo(obj1); } }); map.put("month", "The month"); map.put("bread", "The bread"); map.put("attack", "The attack"); Set<String> keySet = map.keySet(); Iterator<String> iter = keySet.iterator(); while(iter.hasNext()){ String key = iter.next(); System.out.println(key+":"+map.get(key)); }
LinkedHashMap:
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
HashTable:
Hashtable是Dictionary的子类,HashMap是Map接口的一个实现类.
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢
HashTable使用Enumeration,HashMap使用Iterator
class HashMaps { public static void main(String[] args) { // HashMap Map map=new HashMap(); map.put(“a”, “aaa”); map.put(“b”, “bbb”); map.put(“c”, “ccc”); map.put(“d”, “ddd”); Iterator iterator = map.keySet().iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(“map.get(key) is :”+map.get(key)); } Hashtable tab=new Hashtable(); tab.put(“a”, “aaa”); tab.put(“b”, “bbb”); tab.put(“c”, “ccc”); tab.put(“d”, “ddd”); Iterator iterator_1 = tab.keySet().iterator(); while (iterator_1.hasNext()) { Object key = iterator_1.next(); System.out.println(“tab.get(key) is :”+tab.get(key)); } TreeMap tmp=new TreeMap(); tmp.put(“a”, “aaa”); tmp.put(“b”, “bbb”); tmp.put(“c”, “ccc”); tmp.put(“d”, “ddd”); Iterator iterator_2 = tmp.keySet().iterator(); while (iterator_2.hasNext()) { Object key = iterator_2.next(); System.out.println(“tmp.get(key) is :”+tmp.get(key)); } } }
输出只有TreeMap是有序的
3.HashMap和HashTable的区别
1).HashTable的方法前面都有synchronized来同步,是线程安全的;HashMap未经同步,是非线程安全的。
2).HashTable不允许null值(key和value都不可以) ;HashMap允许null值(key和value都可以)。
3).HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4).HashTable使用Enumeration进行遍历;HashMap使用Iterator进行遍历。
5).HashTable中hash数组默认大小是11,增加的方式是old*2+1;HashMap中hash数组的默认大小是16,而且一定是2的指数。
6).哈希值的使用不同,HashTable直接使用对象的hashCode; HashMap重新计算hash值,而且用与代替求模。
4.ArrayList 和vector的区别
ArrayList和Vector都实现了List接口,都是通过数组实现的。
Vector是线程安全的,而ArrayList是非线程安全的。
List第一次创建的时候,会有一个初始大小,随着不断向List中增加元素,当List 认为容量不够的时候就会进行扩容。Vector缺省情况下自动增长原来一倍的数组长度,ArrayList增长原来的50%。
5.ArrayList和LinkedList区别及使用场景
区别
ArrayList底层是用数组实现的,可以认为ArrayList是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其规模是动态增加的。
LinkedList底层是通过双向链表实现的, LinkedList和ArrayList相比,增删的速度较快。但是查询和修改值的速度较慢。同时,LinkedList还实现了Queue接口,所以他还提供了offer(),peek(), poll()等方法。
使用场景
LinkedList更适合从中间插入或者删除(链表的特性)。
ArrayList更适合检索和在末尾插入或删除(数组的特性)。
6.collection和collections的区别
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式。
java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。