一.MFS概述
MooseFS是一个分布式存储的框架,其具有如下特性:
(1)通用文件系统,不需要修改上层应用就可以使用(那些需要专门api的dfs很麻烦!)。
(2)可以在线扩容,体系架构可伸缩性极强。(官方的case可以扩到70台了!)
(3)部署简单。
(4)高可用,可设置任意的文件冗余程度(提供比raid1+0更高的冗余级别,而绝对不会影响读或者写的性能,只会加速!)
(5)可回收在指定时间内删除的文件(“回收站”提供的是系统级别的服务,不怕误操作了,提供类似oralce 的闪回等高级dbms的即时回滚特性!)
(6)提供netapp,emc,ibm等商业存储的snapshot特性。(可以对整个文件甚至在正在写入的文件创建文件的快照)
(7)google filesystem的一个c实现。
(8)提供web gui监控接口。
# 读写原理
1.MFS的读数据过程
(1) client当需要一个数据时,首先向master server发起查询请求;
(2)管理服务器检索自己的数据,获取到数据所在的可用数据服务器位置ip|port|chunkid;
(3)管理服务器将数据服务器的地址发送给客户端;
(4)客户端向具体的数据服务器发起数据获取请求;
(5)数据服务器将数据发送给客户端;
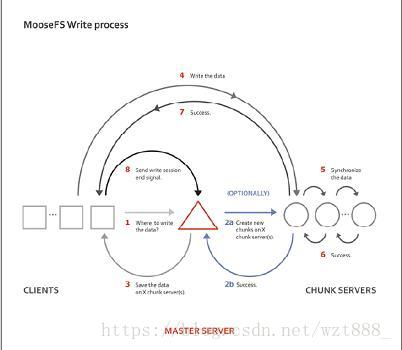
2.MFS的写数据过程
(1)当客户端有数据写需求时,首先向管理服务器提供文件元数据信息请求存储地址(元数据信息如:文件名|大小|份数等);
(2)管理服务器根据写文件的元数据信息,到数据服务器创建新的数据块;
(3)数据服务器返回创建成功的消息;
(4)管理服务器将数据服务器的地址返回给客户端(chunkIP|port|chunkid);
(5)客户端向数据服务器写数据;
(6)数据服务器返回给客户端写成功的消息;
(7)客户端将此次写完成结束信号和一些信息发送到管理服务器来更新文件的长度和最后修改时间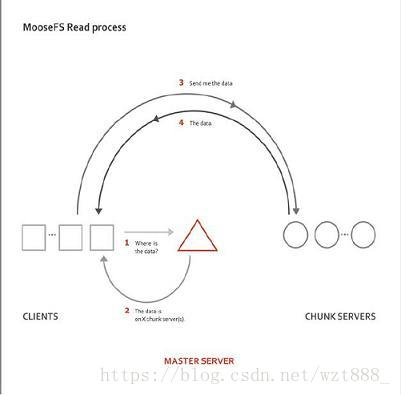
环境:rhel7.3
base2 172.25.78.12 mfsmaster节点
bzse3 172.25.78.13 chunkserver
base4 172.25.78.14 chunkserver
base5 172.25.78.15 高可用
foundation78 172.25.78.254 客户端
9421 # 对外的连接端口
9420 # 用于chunkserver 连接的端口地址
9419 # metalogger 监听的端口地址
这个软件可以记录元数据日志,定期同步master数据日志,防止master挂掉
MFS元数据日志服务器(moosefs-metalogger-3.0.97-1.rhsysv.x86_64.rpm)
元数据日志守护进程是在安装master server 时一同安装的,
最小的要求并不比master 本身大,可以被运行在任何机器上(例如任一台
chunkserver),但是最好是放置在MooseFS master 的备份机上,备份master
服务器的变化日志文件,文件类型为changelog_ml.*.mfs。因为主要的master server 一旦失效,
可能就会将这台metalogger 机器取代而作为master server
二.MFS的安装、部署、配置
1.安装部署mfs
mfsmaster端
[root@base2 ~]# ls
moosefs-cgi-3.0.103-1.rhsystemd.x86_64.rpm
moosefs-cgiserv-3.0.103-1.rhsystemd.x86_64.rpm
moosefs-cli-3.0.103-1.rhsystemd.x86_64.rpm
moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
[root@base2 ~]# yim install -y *.rpm
[root@base2 ~]# vim /etc/hosts # 写解析,不然启动不起来
172.25.78.12 base2 mfsmaster
[root@base2 ~]# systemctl start moosefs-master
[root@base2 ~]# netstat -antlp 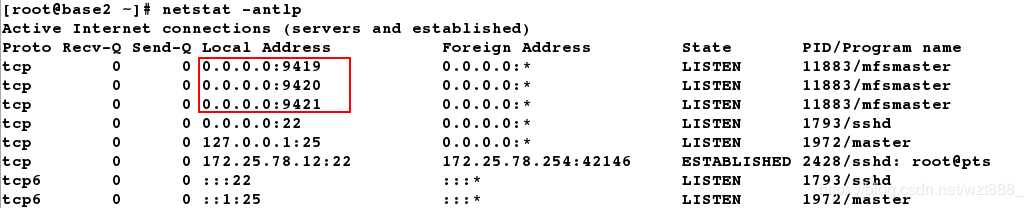
[root@base2 ~]# ll /var/lib/mfs/ # 数据目录
[root@base2 ~]# ll /etc/mfs/ # 主配置文件目录
[root@base2 ~]# systemctl start moosefs-cgiserv # 打开web图形处理工具
配置chunkserver
[root@base3 ~]# yum install -y moosefs-chunkserver-3.0.103-1.rhsystemd.x86_64.rpm
[root@base3 ~]# vim /etc/hosts # 从节点也必须写解析
172.25.78.12 base2 mfsmaster
[root@base3 ~]# cd /etc/mfs/
[root@base3 mfs]# vim mfshdd.cfg # 定义base3中存储数据的挂载点
/mnt/chunk1
[root@base3 mfs]# mkdir /mnt/chunk1 # 创建挂载点
[root@base3 mfs]# chown mfs.mfs /mnt/chunk1 # 改该挂载目录的所有人和所有组,这样才可以在目录中进行读写操作
[root@base3 mfs]# systemctl start moosefs-chunkserver # 开启服务
[root@base4 ~]# yum install -y moosefs-chunkserver-3.0.103-1.rhsystemd.x86_64.rpm
[root@base4 ~]# vim /etc/hosts
172.25.78.12 base2 mfsmaster
[root@base4 ~]# cd /etc/mfs/
[root@base4 mfs]# vim mfshdd.cfg
[root@base4 mfs]# mkdir /mnt/chunk2
[root@base4 mfs]# chown mfs.mfs /mnt/chunk2
[root@base4 mfs]# systemctl start moosefs-chunkserver
8
浏览器访问,从节点添加成功
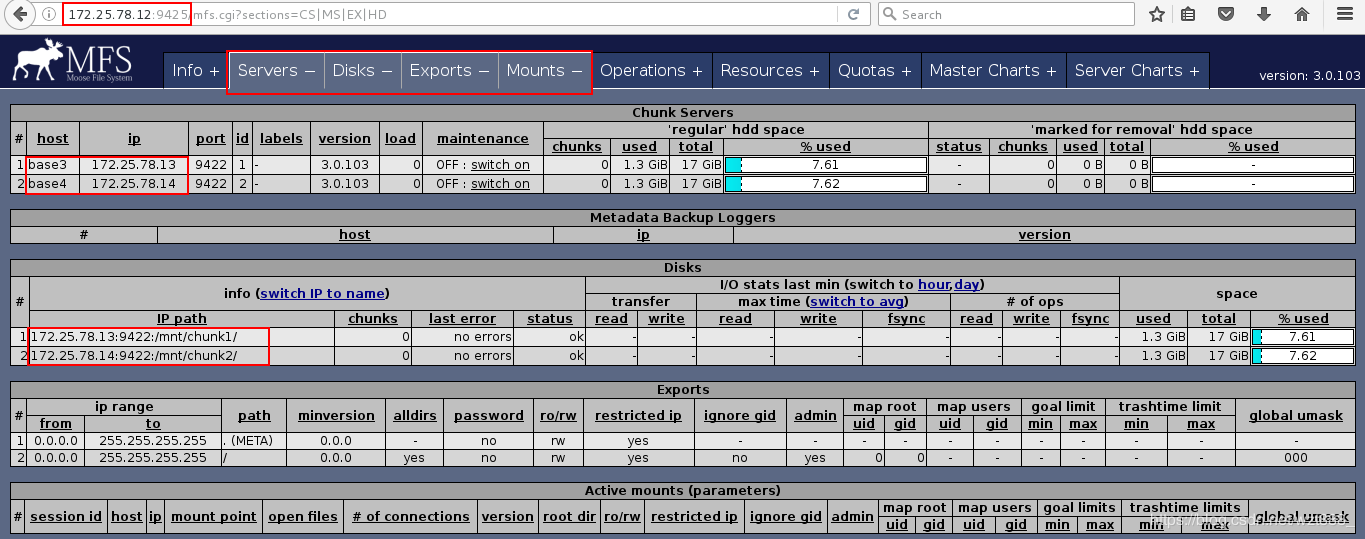
2.客户端测试分布式存储
配置客户端
[root@foundation78 3.0.103]# rpm -ivh moosefs-client-3.0.103-1.rhsystemd.x86_64.rpm # 安装客户端软件
[root@foundation78 mfs]# cd /etc/mfs/
[root@foundation78 mfs]# vim mfsmount.cfg # 确定挂载数据的目录
/mnt/mfs
[root@foundation78 mfs]# mkdir /mnt/mfs # 创建挂载数据的目录
[root@foundation78 mfs]# vim /etc/hosts # 编辑解析文件
172.25.78.12 base2 mfsmaster
[root@foundation78 mfs]# cd /mnt/mfs
[root@foundation78 mfs]# mfsmount # 自动读取后端文件进行挂载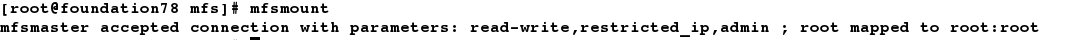
[root@foundation78 mnt]# df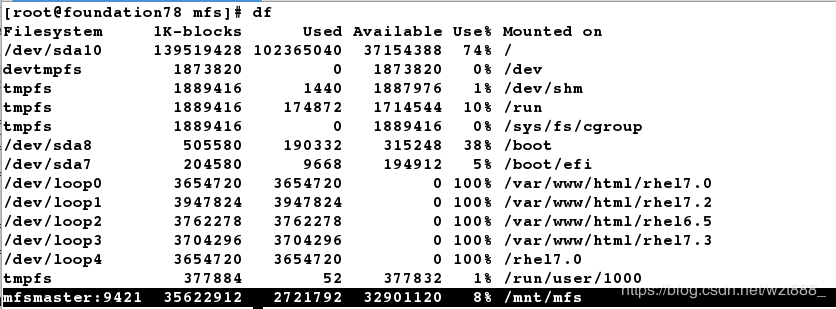
[root@foundation78 mfs]# mkdir dir1
[root@foundation78 mfs]# mkdir dir2
[root@foundation78 mfs]# ls
dir1 dir2
[root@foundation78 mfs]# mfsgetgoal dir1 # 默认的文件副本是2份
dir1: 2
[root@foundation78 mfs]# mfsgetgoal dir2
dir2: 2
[root@foundation78 mfs]# mfssetgoal -r 1 dir1 # 修改dir1的文件备份份数为1

[root@foundation78 mfs]# cd dir1/
[root@foundation78 dir1]# cp /etc/passwd .
[root@foundation78 dir1]# mfsfileinfo passwd # 查看文件具体信息,数据存储在chunk1上,因为我们设置了数据只能存储在一台服务器上
[root@foundation78 dir1]# cd ../dir2/
[root@foundation78 dir2]# cp /etc/fstab .
[root@foundation78 dir2]# mfsfileinfo fstab # 实际上数据存储默认为两份
3.对于大文件,实行离散存储
[root@foundation78 dir2]# cd ../dir1/
[root@foundation78 dir1]# dd if=/dev/zero of=file1 bs=1M count=100 
[root@foundation78 dir1]# mfsfileinfo file1
4.如果我们在客户端不小心删除了元数据,那么怎么恢复呢?
[root@foundation78 dir1]# mfsgettrashtime . # 查看当前文件的缓存时间,在 86400秒内的文件都可以恢复
.: 86400
[root@foundation78 mfs]# mkdir /mnt/mfsmeda
[root@foundation78 mfs]# mfsmount -m /mnt/mfsmeda # 挂载
[root@foundation78 mfs]# mount # 查看挂载记录
[root@foundation78 mfs]# cd /mnt/mfsmeda/
[root@foundation78 mfsmeda]# ls
sustained trash
[root@foundation78 trash]# ls

[root@foundation78 trash]# find -name *passwd* # 查找丢失文件
./004/00000004|dir1|passwd
[root@foundation78 trash]# cd 004
[root@foundation78 004]# ls
00000004|dir1|passwd undel
[root@foundation78 004]# mv 00000004|dir1|passwd undel/ # 恢复文件,注意特殊字符要进行转译
[root@foundation78 004]# cd /mnt/mfs/dir1/
[root@foundation78 dir1]# ls # 文件成功恢复
file1 passwd
5.master有时候会处于非正常服务状态,导致客户端无法获取数据
(1)正常关闭master
当服务端正常关闭时,客户端就会卡顿
[root@base2 ~]# systemctl stop moosefs-master
[root@foundation78 dir1]# df
当服务端重新开启时,客户端就会恢复正常
[root@base2 ~]# systemctl start moosefs-master
(2)非正常关闭master
[root@base2 ~]# ps ax
[root@base2 ~]# kill -9 11986 # 模拟非正常关闭
[root@base2 ~]# systemctl start moosefs-master
[root@base2 ~]# /usr/sbin/mfsmaster -a
[root@base2 ~]# ps ax # 查看进程,成功开启
但是每次master非正常关闭之后,我们每次执行这个命令就有点麻烦,所以我们直接写在配置文件里,这样不管是否正常关闭,都可以保证服务成功开启
[root@base2 ~]# vim /usr/lib/systemd/system/moosefs-master.service
[Unit]
Description=MooseFS Master server
Wants=network-online.target
After=network.target network-online.target
[Service]
Type=forking
ExecStart=/usr/sbin/mfsmaster -a
ExecStop=/usr/sbin/mfsmaster stop
ExecReload=/usr/sbin/mfsmaster reload
PIDFile=/var/lib/mfs/.mfsmaster.lock
TimeoutStopSec=1800
TimeoutStartSec=1800
Restart=no
[Install]
WantedBy=multi-user.target
[root@base2 ~]# systemctl daemon-reload
[root@base2 ~]# ps ax
[root@base2 ~]# kill -9 12060
[root@base2 ~]# systemctl start moosefs-master # 此时开启就不会报错了
[root@base2 ~]# systemctl status moosefs-master
三.mfsmaser的高可用
配置master,先获取高可用安装包
[root@base2 ~]# vim /etc/yum.repos.d/yum.repo # 配置高可用yum源
[rhel7.3]
name=rhel7.3
baseurl=http://172.25.78.254/rhel7.3
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.78.254/rhel7.3/addons/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.78.254/rhel7.3/addons/ResilientStorage
gpgcheck=0
[root@base2 ~]# yum repolist
[root@base2 ~]# yum install -y pacemaker corosync pcs # 这是高可用安装包
[root@base2 ~]# rpm -q pacemaker
pacemaker-1.1.15-11.el7.x86_64
[root@base2 ~]# ssh-keygen # 生成密钥,方便连接
[root@base2 ~]# ssh-copy-id base5 # 设置免密
[root@base2 ~]# systemctl start pcsd
[root@base2 ~]# systemctl enable pcsd
[root@base2 ~]# passwd hacluster
Changing password for user hacluster. # 设置密码,主备必须相同
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
配置bankup-mfsmaster
[root@base5 ~]# ls
moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
[root@base5 ~]# rpm -ivh moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
[root@base5 ~]# vim /usr/lib/systemd/system/moosefs-master.service
[Unit]
Description=MooseFS Master server
Wants=network-online.target
After=network.target network-online.target
[Service]
Type=forking
ExecStart=/usr/sbin/mfsmaster -a
ExecStop=/usr/sbin/mfsmaster stop
ExecReload=/usr/sbin/mfsmaster reload
PIDFile=/var/lib/mfs/.mfsmaster.lock
TimeoutStopSec=1800
TimeoutStartSec=1800
Restart=no
[Install]
WantedBy=multi-user.target
[root@base5 ~]# systemctl daemon-reload
[root@base5 ~]# vim /etc/yum.repos.d/yum.repo # 配置高可用yum源
[rhel7.3]
name=rhel7.3
baseurl=http://172.25.78.254/rhel7.3
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.78.254/rhel7.3/addons/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.78.254/rhel7.3/addons/ResilientStorage
gpgcheck=0
[root@base5 ~]# yum repolist
[root@base5 ~]# yum install -y pacemaker corosync
[root@base5 ~]# yum install -y pcs
[root@base5 ~]# systemctl start pcsd
[root@base5 ~]# systemctl enable pcsd
[root@base5 ~]# passwd hacluster
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
开始创建集群
[root@base2 ~]# pcs cluster auth base2 base5 # 创建集群
[root@base2 ~]# pcs cluster setup --name mycluster base2 base5 # 给集群起名称
[root@base2 ~]# pcs status nodes # 查看集群状态,有报错,是因为有部分服务没有开启
Error: error running crm_mon, is pacemaker running?
[root@base2 ~]# pcs cluster start --all # 开启所有的服务
[root@base2 ~]# pcs status nodes # 再次查看节点信息
[root@base2 ~]# corosync-cfgtool -s # 验证corosync是否正常
[root@base2 ~]# pcs status corosync # 查看corosync状态
创建主备集群
[root@base2 ~]# crm_verify -L -V # 检查配置,有报错
[root@base2 ~]# pcs property set stonith-enabled=false # 更改属性,禁用STONITH
[root@base2 ~]# crm_verify -L -V # 再次检查,没有报错
[root@base2 ~]# pcs status # 查看状态
[root@base2 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.78.100 cidr_netmask=32 op monitor interval=30s # 创建vip
[root@base2 ~]# ip a # 查看创建成功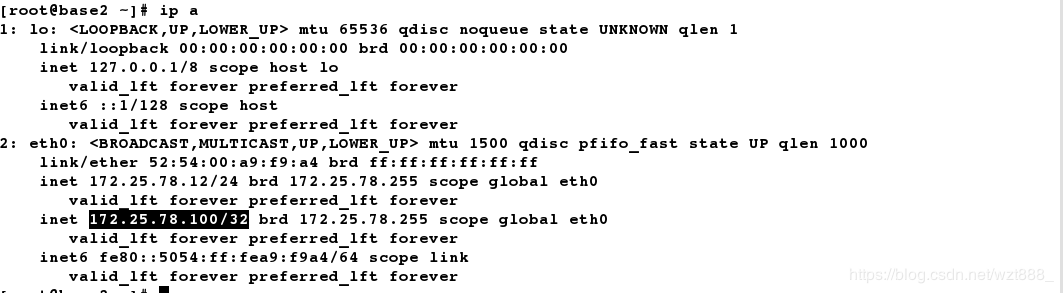
[root@base5 ~]# crm_mon # 查看监控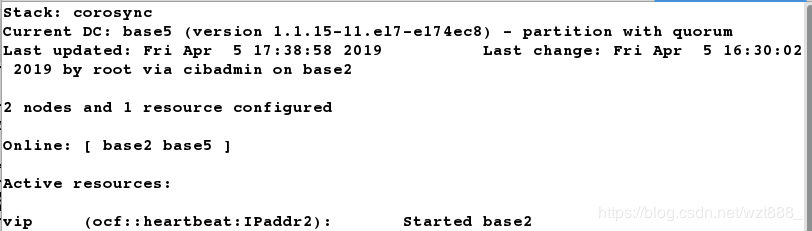
执行故障转移
[root@base2 ~]# pcs cluster stop base2 # 关闭master,查看监控vip会自动漂移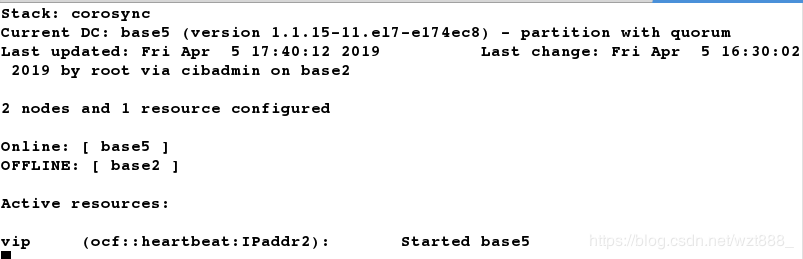
[root@base2 ~]# pcs cluster start base2 # 当master重新开启时,不会抢占资源
[root@base5 ~]# pcs cluster stop base5 # 关闭backup-master,vip又自动漂移到master上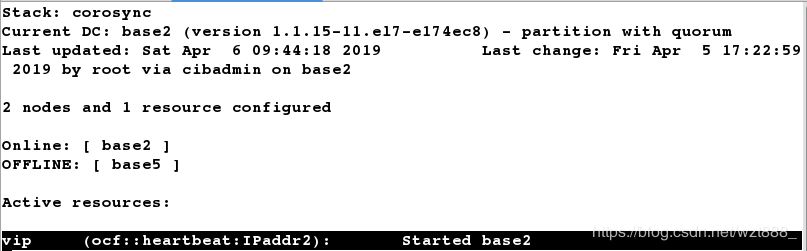
以上实验我们实现了mfs的高可用,当master出故障时,backup-master会立刻接替master的工作,保证客户端可以正常得到服务
[root@base2 ~]# pcs resource standards # 获取可用资源标准列表
[root@base2 ~]# pcs resource providers # 查看资源提供者的列表
[root@base2 ~]# pcs resource agents ocf:heartbeat # 查看特定的可用资源代理

2.存储共享(我们用vip的方式来实现共享)
先恢复环境,写好解析
[root@foundation78 ~]# umount /mnt/mfs
[root@foundation78 ~]# umount /mnt/mfsmeta
[root@foundation78 ~]# vim /etc/hosts
172.25.78.100 mfsmaster
[root@base2 ~]# systemctl stop moosefs-master
[root@base2 ~]# vim /etc/hosts
172.25.78.100 mfsmaster
[root@base3 ~]# systemctl stop moosefs-chunkserver
[root@base3 ~]# vim /etc/hosts
172.25.78.100 mfsmaster
[root@base4 ~]# systemctl stop moosefs-chunkserver
[root@base4 ~]# vim /etc/hosts
172.25.78.100 mfsmaster
給chunkserver(base3)添加一块磁盘
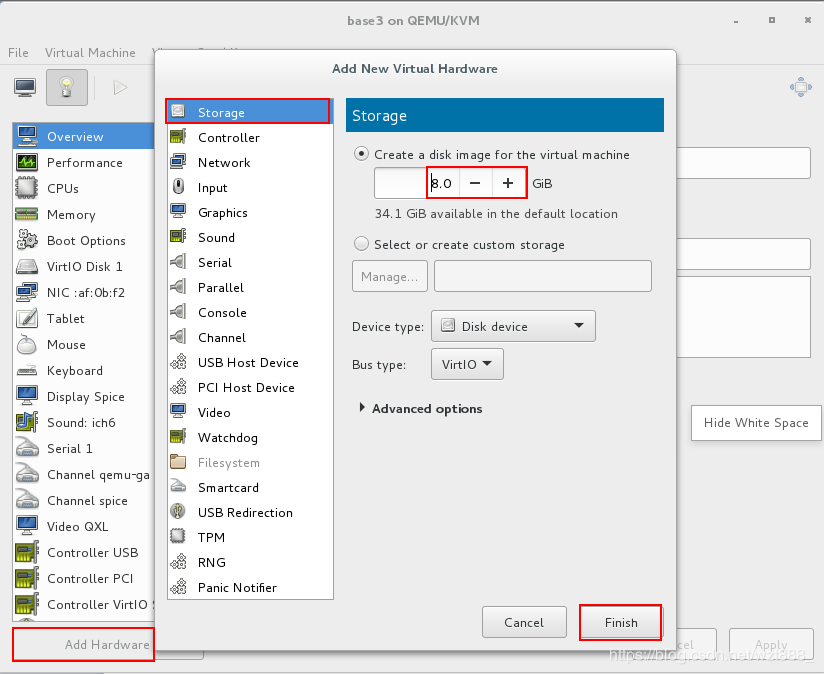
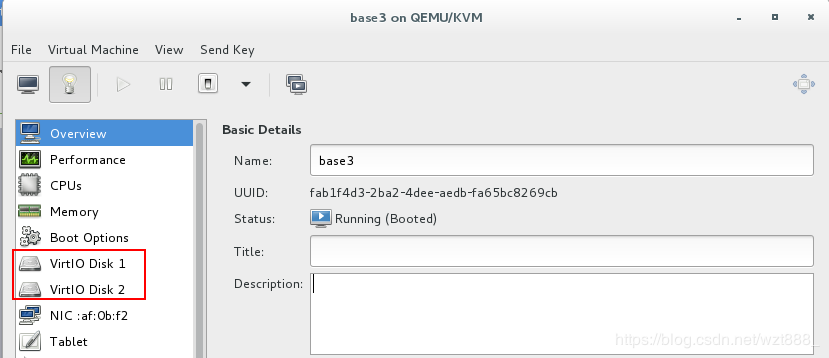
[root@base3 ~]# fdisk -l
[root@base3 ~]# yum install -y targetcli # 安装远程块存储设备
[root@base3 ~]# systemctl start target # 开启服务
[root@base3 ~]# targetcli # 配置iSCSI服务
/> cd backstores/block
/backstores/block> create my_disk1 /dev/vdb
/backstores/block> cd ..
/backstores> cd ..
/> cd iscsi
/iscsi> create iqn.2019-04.com.example:base3
/iscsi> cd iqn.2019-04.com.example:base3
/iscsi/iqn.20...example:base3> cd tpg1/luns
/iscsi/iqn.20...se3/tpg1/luns> create /backstores/block/my_disk1
/iscsi/iqn.20...se3/tpg1/luns> cd ..
/iscsi/iqn.20...le:base3/tpg1> cd acls
/iscsi/iqn.20...se3/tpg1/acls> create iqn.2019-04.com.example:client
/iscsi/iqn.20...se3/tpg1/acls> cd ..
/iscsi/iqn.20...le:base3/tpg1> cd ..
/iscsi/iqn.20...example:base3> cd ..
/iscsi> cd ..
/> ls
/> exit
在master上安装iscsi客户端软件
[root@base2 ~]# yum install -y iscsi-*
[root@base2 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-04.com.example:client
[root@base2 ~]# iscsiadm -m discovery -t st -p 172.25.78.13 # 发现远程设备
172.25.78.13:3260,1 iqn.2019-04.com.example:base3
[root@base2 ~]# iscsiadm -m node -l # 登录

[root@base2 ~]# fdisk -l # 可以查看到远程共享出来的磁盘
[root@base2 ~]# fdisk /dev/sda # 使用共享磁盘,建立分区
Command (m for help): n
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-16777215, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-16777215, default 16777215):
Using default value 16777215
Command (m for help): p
Command (m for help): wq
[root@base2 ~]# mkfs.xfs /dev/sda1 # 格式化分区
[root@base2 ~]# dd if=/dev/zero of=/dev/sda bs=512 count=1 # 破坏分区
[root@base2 ~]# fdisk -l /dev/sda # 查看不到分区
因为截取速度太快,导致分区被自动删除,不过不用担心,因为我们把/dev/sda下的所有空间都分给了/dev/sda1,所以我们只需要重新建立分区即可
[root@base2 ~]# mount /dev/sda1 /media/ # 查看到分区不存在
mount: special device /dev/sda1 does not exist
[root@base2 ~]# fdisk /dev/sda # 重新创建分区
Command (m for help): n
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-16777215, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-16777215, default 16777215):
Using default value 16777215
Command (m for help): wq
[root@base2 ~]# mount /dev/sda1 /mnt
[root@base2 ~]# df
[root@base2 ~]# cd /var/lib/mfs/ # 这是mfs的数据目录
[root@base2 mfs]# ls
changelog.10.mfs changelog.13.mfs changelog.4.mfs metadata.crc metadata.mfs.back.1 stats.mfs
changelog.12.mfs changelog.3.mfs changelog.6.mfs metadata.mfs metadata.mfs.empty
[root@base2 mfs]# cp -p * /mnt # 带权限拷贝/var/lib/mfs的所有数据文件到/dev/sdb1上
[root@base2 mfs]# cd /mnt
[root@base2 mnt]# ll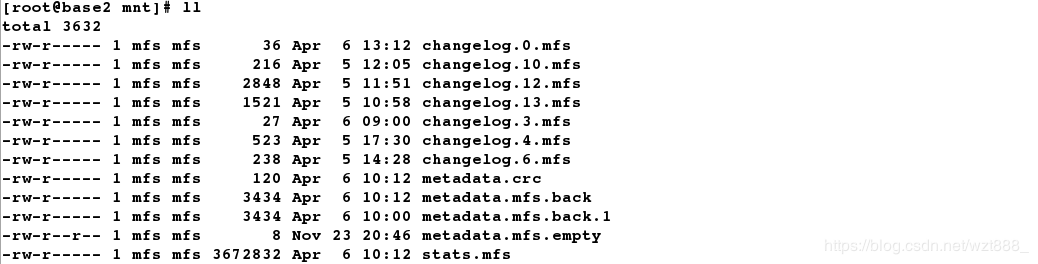
[root@base2 mnt]# chown mfs.mfs /mnt # 当目录属于mfs用户和组时,才能正常使用
[root@base2 mnt]# ll -d /mnt
drwxr-xr-x 2 mfs mfs 285 Apr 6 13:30 /mnt
[root@base2 mnt]# cd
[root@base2 ~]# umount /mnt
[root@base2 ~]# mount /dev/sda1 /var/lib/mfs/ # 使用分区,测试是否可以使用共享磁盘
[root@base2 ~]# df
[root@base2 ~]# systemctl start moosefs-master # 服务开启成功,就说明数据文件拷贝成功,共享磁盘可以正常使用
[root@base2 ~]# ps ax
[root@base2 ~]# systemctl stop moosefs-master
配置backup-master,是之也可以使用共享磁盘
[root@base5 ~]# vim /etc/hosts
[root@base5 ~]# yum install -y iscsi-*
[root@base5 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-04.com.example:client
[root@base5 ~]# iscsiadm -m discovery -t st -p 172.25.78.13
172.25.78.13:3260,1 iqn.2019-04.com.example:base3
[root@base5 ~]# iscsiadm -m node -l
[root@base5 ~]# fdisk -l
[root@base5 ~]# mount /dev/sda1 /var/lib/mfs/ # 此处使用的磁盘和master是同一块,因为master已经做过配置了,所以我们只需要使用即可,不用再次配置
[root@base5 ~]# systemctl start moosefs-master # 测试磁盘是否可以正常使用
[root@base5 ~]# systemctl stop moosefs-master
[root@base5 ~]# pcs cluster start base5
在master上创建mfs文件系统
[root@base2 ~]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sda1 directory=/var/lib/mfs fstype=xfs op monitor interval=30s
[root@base2 ~]# pcs resource show

[root@base2 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min # 创建mfsd系统
[root@base2 ~]# pcs resource group add mfsgroup vip mfsdata mfsd # 把vip,mfsdata,mfsd 集中在一个组中
[root@base2 ~]# pcs cluster stop base2 # 当关闭master之后,master上的服务就会迁移到backup-master上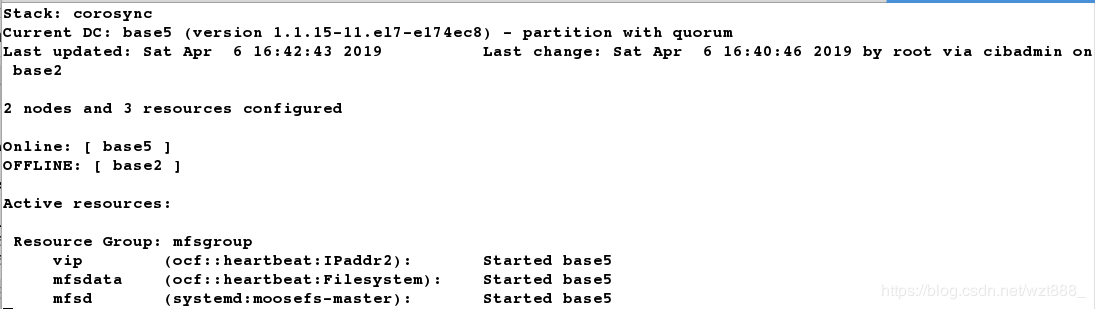
3.fence解决脑裂问题
(1)先在客户端测试高可用
打开chunkserver
[root@base3 ~]# systemctl start moosefs-chunkserver
[root@base3 ~]# ping mfsmaster # 保证解析可以通信
[root@base4 ~]# systemctl start moosefs-chunkserver
[root@base4 ~]# ping mfsmaster
查看vip的位置
[root@base5 ~]# ip a
开启master
[root@base2 ~]# pcs cluster start base2
在客户端进行分布式存储测试
[root@foundation78 ~]# mfsmount # 挂载,挂载失败
[root@foundation78 ~]# cd /mnt/mfs
[root@foundation78 mfs]# ls # 因为此目录下不是空的
dir1 dir2
[root@foundation78 mfs]# rm -fr * # 删除此目录下的所有文件
[root@foundation78 mfs]# ls
[root@foundation78 mfs]# cd
[root@foundation78 ~]# mfsmount # 可以成功挂载
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@foundation78 ~]# cd /mnt/mfs/dir1
[root@foundation78 dir1]# dd if=/dev/zero of=file2 bs=1M count=2000 # 我们上传一份大文件
[root@base2 ~]# pcs cluster stop base5 # 在客户端上传大文件的同时,关闭正在提供服务的服务端
[root@foundation78 dir1]# mfsfileinfo file2 # 我们查看到文件上传成功,并没有受到影响
通过以上实验我们发现,当master挂掉之后,backup-master会立刻接替master的工作,保证客户端可以进行正常访问,但是,当master重新运行时,我们不能保证master是否会抢回自己的工作,从而导致master和backup-master同时修改同一份数据文件从而发生脑裂,此时fence就派上用场了
安装fence服务
[root@base5 ~]# yum install -y fence-virt
[root@base5 ~]# mkdir /etc/cluster
[root@base2 ~]# yum install -y fence-virt
[root@base2 ~]# mkdir /etc/cluster
生成一份fence密钥文件,传给服务端
[root@foundation78 ~]# yum install -y fence-virtd
[root@foundation78 ~]# yum install fence-virtd-libvirt -y
[root@foundation78 ~]# yum install fence-virtd-multicast -y
[root@foundation78 ~]# fence_virtd -c
Listener module [multicast]:
Multicast IP Address [225.0.0.12]:
Multicast IP Port [1229]:
Interface [virbr0]: br0 # 注意此处要修改接口,必须与本机一致
Key File [/etc/cluster/fence_xvm.key]:
Backend module [libvirt]: 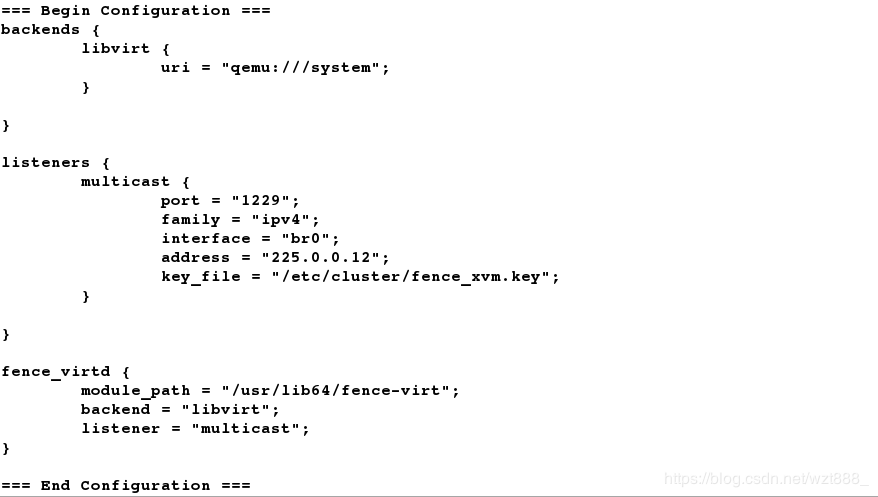
[root@foundation78 ~]# mkdir /etc/cluster # 这是存放密钥的文件,需要自己手动建立
[root@foundation78 ~]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
[root@foundation78 ~]# systemctl start fence_virtd
[root@foundation78 ~]# cd /etc/cluster/
[root@foundation78 cluster]# ls
fence_xvm.key
[root@foundation78 cluster]# scp fence_xvm.key root@172.25.78.12:/etc/cluster/
[root@foundation78 cluster]# scp fence_xvm.key root@172.25.78.15:/etc/cluster/
[root@foundation78 cluster]# netstat -anulp | grep 1229

[root@foundation78 cluster]# virsh list # 查看主机域名
在master查看监控crm_mon

[root@base2 ~]# cd /etc/cluster
[root@base2 cluster]# pcs stonith create vmfence fence_xvm pcmk_host_map="base2:base2;base5:base5" op monitor interval=1min
[root@base2 cluster]# pcs property set stonith-enabled=true
[root@base2 cluster]# crm_verify -L -V
[root@base2 cluster]# fence_xvm -H base5 # 使base5断电重启
[root@base2 cluster]# crm_mon # 查看监控,base5上的服务迁移到master上
[root@base2 cluster]# echo c > /proc/sysrq-trigger # 模拟master端内核崩溃
查看监控,base5会立刻接管master的所有服务

查看监控发现,master重启成功之后,并不会抢占资源,服务依旧在backup-master端正常运行,说明fence生效
