数据案例

1、匹配查询
a、单词查询

执行match步骤:
·检查field类型:title字段为(analyzed)字符串,所以搜索时,title需要被分析。
·分析查询字符串:QUICK! 经过标准分析器分后为quick
·找到匹配文档:再倒排索引中找到quick,并返回包含该词的文档(1,2,3)
·为每个文档打分:查询综合考虑词频( 每篇文档 title 字段包含 quick 的次数) 、 逆文档频率( 在全部文档中 title 字段包含 quick 的次数) 、
包含 quick 的字段长度( 长度越短越相关) 来计算每篇文档的相关性得分 _score
b、多词查询


<1> 文档4的相关度最高, 因为包含两个"brown"和一个"dog"。
<2> 文档2和3都包含一个"brown"和一个"dog", 且'title'字段长度相同, 所以相关度相等。
<3> 文档1只包含一个"brown", 不包含"dog", 所以相关度最低。
因为 match 查询需要查询两个关键词: "brown" 和 "dog" , 在内部会执行两个 term 查询并
综合二者的结果得到最终的结果。 match 的实现方式是将两个 term 查询放入一个 bool 查询, bool 查询在之前的章节已经介绍过。
重要的一点是, 'title' 字段包含至少一个查询关键字的文档都被认为是符合查询条件的。匹配的单词数越多, 文档的相关度越高。
提高精度
默认匹配结果为或的关系,如brown dog 搜索结果为包含brown或者dog的文档
match查询接受operator参数提高精度。默认operator=or
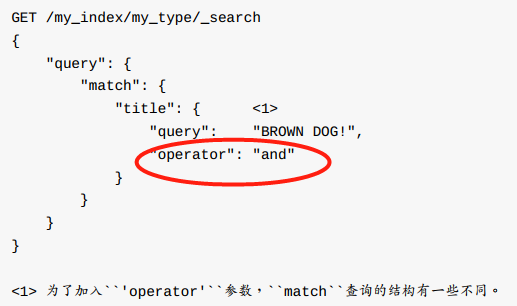
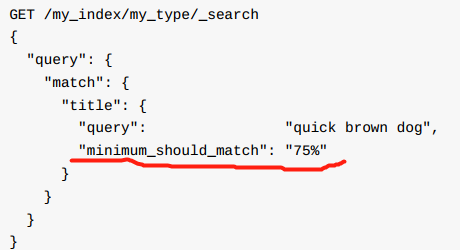
match 查询有 'minimum_should_match' 参数, 参数值表示被视为相关的文档必须匹配的关键词个数。 参数值可以设为整数, 也可以设置为百分数。
因为不能提前确定用户输入的查询关键词个数, 使用百分数也很合理
2、组合查询
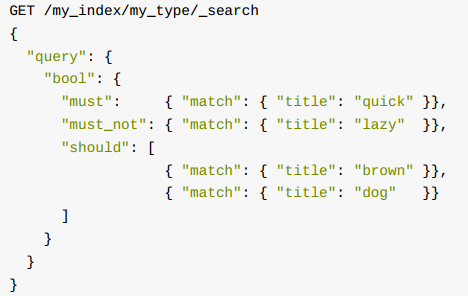
计算得分
把所有符合 must 和 should 的子句得分加起来, 然后除以 must 和 should 子句的总数为每个文档计算相关性得分。
must_not 子句并不影响得分; 他们存在的意义是排除已经被包含的文档。
精度控制
所有的 must 子句必须匹配, 并且所有的 must_not 子句必须不匹配, 但是多少 should 子句应该匹配呢? 默认的, 不需要匹配任何 should 子句,
一种情况例外: 如果没有 must 子句,就必须至少匹配一个 should 子句。像我们控制 match 查询的精度一样,
我们也可以通过 minimum_should_match 参数控制多少 should 子句需要被匹配, 这个参数可以是正整数, 也可以是百分比。

结果集仅包含 title 字段中有 "brown" 和 "fox" , "brown" 和 "dog" , 或 "fox" 和 "dog" 的文档。 如果一个文档包含上述三个条件, 那么它的相关性就会比其他仅包含三者中的两个条件的文档要高