1、简单描述
hash是一个string类型的field和value的映射表。添加和删除操作都是O(1)(平均)的复杂度。hash类型特别适合用于存储对象。在field的数量在限制的范围内以及value的长度小于指定的字节数,那么此时的hash类型是用zipmap存储的,所以会比较节省内存。可以在配置文件里面修改配置项来控制field的数量和value的字节数大小。
hash-max-zipmap-entries 512 #配置字段最多512个
hash-max-zipmap-value 64 #配置value最大为64字节。
必须满足以上两个条件,那么该key会被压缩。否则就是按照正常的hash结构来存储hash类型的key。
【注意】这两个配置并不是限制hash结构最多只能存多少个field以及value的最大字节数,而是说在field未超过配置的数量,而且每一个filed对应的value的长度都小于指定的字节数时,注意是两个条件都满足时,该key的存储是采用的zipmap,就是压缩了的数据,节省空间。当field的数量超过了,或者其中有value的长度大于指定的长度,那么整个key就会采用正常的hash结构来在内存中存储。
2、相关命令(基于4.0.1版本)
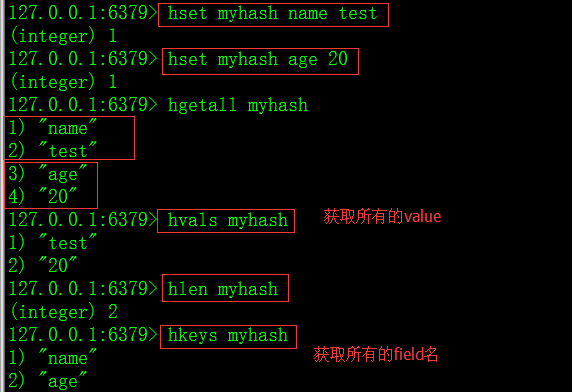
1)hset命令:设置一个key的filed对应的值,filed不存在则新增,field存在则修改field对应的值。
2)hgetall命令:获取该key的所有field以及对应的值。
3)hlen命令:获取key的长度,就是field的个数。
4)hvals命令:获取所有filed对应的value,只返回value。
5)hkeys命令:获取所有的filed,只返回filed,不返回value。
6)hmset命令:一次设置多个filed和对应的值
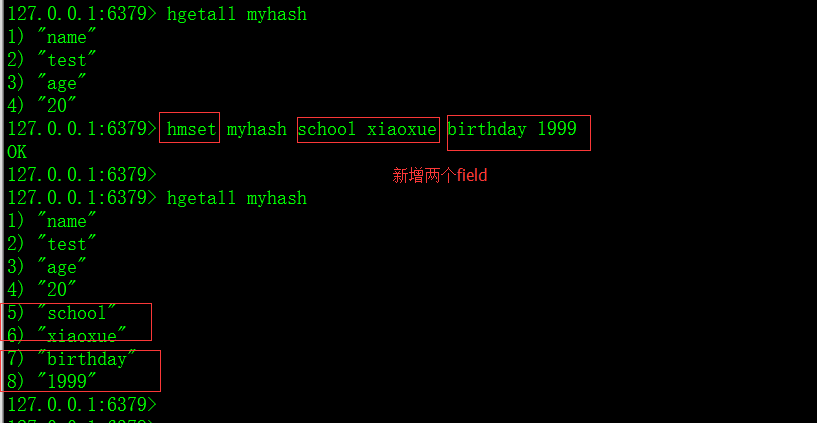
7)hmget命令:获取多个filed的值

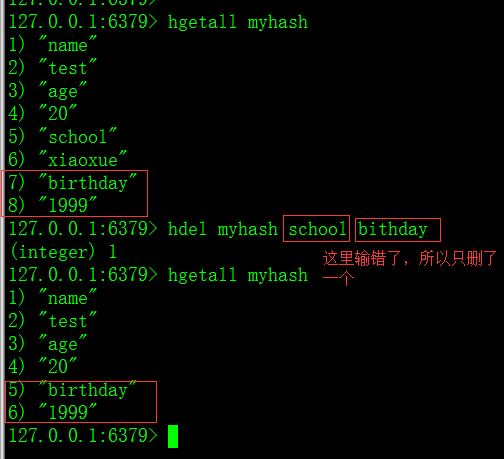
8)hdel命令:删除filed,允许删除多个。
9)hincrby命令:给filed字段的值增加一个数,可以是负数。
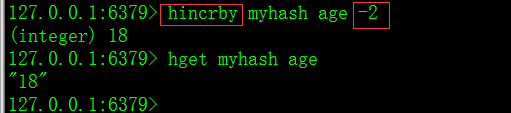
【注意】不能增加浮点数

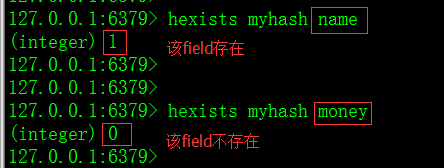
10)hexists命令:判断某个field是否存在,存在则返回1,否则返回0。
3、小结
1)hash结构是可以压缩的,要同时满足2个条件,也就是两个配置项;
2)根据需求来确定数据是采用string类型来存储(比如把对象序列化为string类型),还是说使用hash存储(把对象的属性化为field和value来存储),如果是field比较少的,而且value也比较小,那么用hash节省内存。但是也要考虑具体的需求,如果采用hash,同时要更新几个field时会不会麻烦些,如果采用string类型,直接修改整个对象然后直接序列化。
当然hash也支持直接把对象序列化来存储。具体问题具体分析。