一、算法思想
优先队列的原理本质上就是利用完全二叉树的结构实现以log2n的时间复杂度删除队列中的最小对象(这里以小堆顶为例)。完全二叉树又可以通过数组下标实现索引,当插入一个对象的时候,利用上浮操作更新最小对象。当删除堆顶最小对象时,将末尾的对象放置到堆顶上,然后执行下沉操作。
优先队列有一个缺点,就是不能直接访问已存在于优先队列中的对象,并更新它们。这个问题在Dijistra算法中就有明显的体现,有时候我们需要更新已在队列中的顶点的距离。为此就需要设计一种新型的数据结构来解决这个问题,这就是本文要介绍的索引优先队列。
索引优先队用一个整数和对象进行关联,当我们需要跟新该对象的值时,可以通这个整数进行快速索引,然后对对象的值进行更新。当然更新后的对象在优先队列中的位置可能发生变化,这样以保证整个队列还是一个优先队列。
二、算法流程
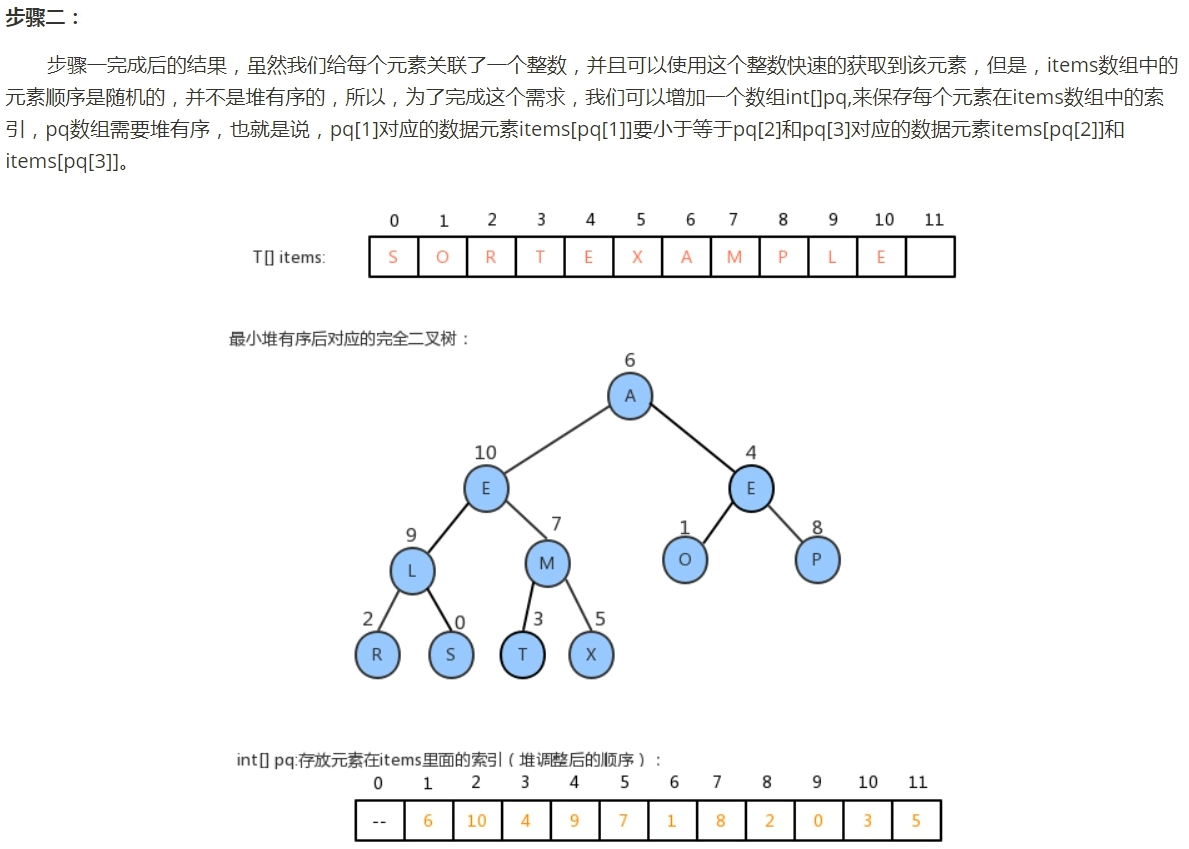
1,增加数组keys用来保存优先队列元素(item or key)
2,pq数组则改用于保存索引(pq[i] = k,k为索引),这里的pq数组仍然保持堆有序,即pq[1]所对应的元素(keys[pq[1]])大于或等于pq[2]、pq[3]所对应的元素(keys[pq[2]]、keys[pq[3]])。
3,增加数组qp,用于保存pq的逆序。如果pq[i] = k,则qp[k] = i,也就是pq[qp[k]] = k。如果k不在队列之中,则qp[k] = -1。


三、算法实现
1 package io.guangsoft; 2 3 import java.util.Arrays; 4 5 public class IndexMinPriorityQueue <T extends Comparable>{ 6 //用来存储元素的数组 7 private T[] items; 8 //保存每个元素在items数组中的索引,pq数组需要堆有序 9 private int[] pq; 10 //保存pq的逆序,pq值作为索引,pq的索引作为值 11 private int[] qp; 12 //记录堆中元素个数 13 private int n; 14 //创建容量为capacity的indexMinPriorityQueue 15 IndexMinPriorityQueue(int capacity) { 16 this.items = (T[])new Comparable[capacity + 1]; 17 this.pq = new int[capacity + 1]; 18 this.qp = new int[capacity + 1]; 19 this.n = 0; 20 //默认情况下,队列中没有任何存储数据,让qp中的元素都为-1 21 for(int i = 0; i < qp.length; i++) { 22 qp[i] = -1; 23 } 24 } 25 //获取队列中元素的个数 26 public int size() { 27 return n; 28 } 29 //判断队列是否为空 30 public boolean isEmpty() { 31 return n == 0; 32 } 33 //判断堆中索引i处的元素是否小于索引j处的元素 34 private boolean less(int i, int j) { 35 return items[pq[i]].compareTo(items[pq[j]]) < 0; 36 } 37 //交换堆中索引i处元素和索引j处元素 38 private void swap(int i, int j) { 39 //交换pq中的数据 40 int tmp = pq[i]; 41 pq[i] = pq[j]; 42 pq[j] = tmp; 43 //更新qp中的数据 44 qp[pq[i]] = i; 45 qp[pq[j]] = j; 46 } 47 //判断k对应的元素是否存在 48 public boolean contains(int k) { 49 return qp[k] != -1; 50 } 51 //最小元素关联索引 52 public int minIndex() { 53 return pq[1]; 54 } 55 //删除队列中最小的元素,并返回该元素关联的索引 56 public int delMin() { 57 //获取最小元素的关联索引 58 int minIndex = pq[1]; 59 //交换pq中索引1处和最大索引处的元素 60 swap(1, n); 61 //删除qp中对应的内容 62 qp[pq[n]] = -1; 63 //删除items中对应的内容 64 items[minIndex] = null; 65 //删除pq中最大索引处的内容 66 pq[n] = -1; 67 //元素个数-1 68 n--; 69 //下沉操作 70 sink(1); 71 return minIndex; 72 } 73 //删除索引i关联的元素 74 public void delete(int i) { 75 //找到i在pq中的索引 76 int k = qp[i]; 77 //交换pq中索引k处的值和索引n处的值 78 swap(k, n); 79 //删除qp中的内容 80 qp[pq[n]] = -1; 81 //删除items中的内容 82 items[k] = null; 83 //删除pq中的内容 84 pq[n] = -1; 85 //元素的数量-1 86 n--; 87 //堆的调整 88 sink(k); 89 swim(k); 90 } 91 //往队列中插入一个元素,并关联索引 92 public void insert(int i, T t) { 93 //判断i是否已经被关联,如果已经被关联,则不允许插入 94 if(contains(i)) { 95 return; 96 } 97 //元素个数增加 98 n++; 99 //把数据存储到items对应的i位置 100 items[i] = t; 101 //把i存储到pq中 102 pq[n] = i; 103 //通过qp来记录pq中的i 104 qp[i] = n; 105 //通过堆上浮进行堆的调整 106 swim(n); 107 } 108 //把与索引i关联的元素修改为t 109 public void changeItem(int i, T t) { 110 //修改items数组中i位置的元素为t 111 items[i] = t; 112 //找到i在pq中出现的位置 113 int k = qp[i]; 114 //堆调整 115 sink(k); 116 swim(k); 117 } 118 //使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置 119 private void swim(int k) { 120 while(k > 1) { 121 if(less(k, k / 2)) { 122 swap(k, k / 2); 123 } 124 k /= 2; 125 } 126 } 127 //使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 128 private void sink(int k) { 129 while(2 * k <= n) { 130 //找到子节点中的较小值 131 int min; 132 if(2 * k + 1 <= n) { 133 if(less(2 * k, 2 * k + 1)) { 134 min = 2 * k; 135 } else { 136 min = 2 * k + 1; 137 } 138 } else { 139 min = 2 * k; 140 } 141 //比较当前节点和较小值 142 if(less(k, min)) { 143 break; 144 } 145 swap(k, min); 146 k = min; 147 } 148 } 149 //主类 150 public static void main(String args[]) { 151 //创建索引最小优先队列和对象 152 IndexMinPriorityQueue<Integer> queue = new IndexMinPriorityQueue<>(10); 153 //往队列中添加元素 154 queue.insert(0, 2); 155 queue.insert(1, 1); 156 queue.insert(2, 3); 157 //测试修改 158 queue.changeItem(2, 7); 159 //测试删除 160 System.out.print("队列的序列为:" + Arrays.toString(queue.items)); 161 System.out.println(); 162 System.out.print("最小值索引为:" ); 163 while(!queue.isEmpty()) { 164 int index = queue.delMin(); 165 System.out.print(index + " "); 166 } 167 } 168 }
四、算法分析
索引优先队列,用一个索引数组保存了元素在数组中的位置。在插入队列中时,可看作将一个整数和一个对象相关联,使得我们可以引用队列中的元素。比如在Dijkstra算法中就用到了索引优先队列,他将顶点(整数表示)和源点到该顶点的最短路径长度关联起来,每次删除最小元素,都能得到与之关联的那个整数;如果该整数已经被关联了,还可以更新与该整数关联的对象。可以看出,索引优先队列和优先队列比起来,操作数组里面的元素更加方便了——这就是关联了索引带来的好处。时间复杂度为O(ElogV)。