1,CopyOnWriteArrayList
CopyOnWriteArrayList是java1.5版本提供的一个线程安全的ArrayList变体,ArrayList具有fast-fail特性,它是值在遍历过程中,如果ArrayList的内容发生过修改,那么会抛出ConcurrentModificationException。
在多线程环境下,这种情况变得尤为突出。不使用迭代器形式而使用下标来遍历就会带来一个问题,读写没有分离。写操作户影响到读的准确性,甚至导致IndexOutOfBoundsException。不直接遍历list,而是把list拷贝一份数组,再行遍历。
写时拷贝,自然实在做写操作时,把原始数据拷贝到一个新的数组,与写操作相关的主要有三个方法:add、remove、set,在每一次add操作里,数组都被拷贝了一个副本,这就是写时拷贝的原理,那么写时拷贝和读时拷贝各有什么优势,如何选择呢?
如果一个list的遍历操作比写入操作更频繁,那么用该使用CopyOnWriteArrayList,如果list的写入操作比遍历操作更频繁,那么应该考虑读时拷贝。
2,ConcurrentHashMap
ConcurrentHashMap是Java5中支持高并发、高吞吐量的线程安全HashMap实现,它由Segment数组结构和HashEntry数组结构组成。Segment在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,首先必须获得它对应的Segment锁。
HashTable和ConcurrentHashMap存储的内容为键值对,且他们都是现成安全的容器,下面通过简要介绍他们的实现方法来对比他们的不同点。
HashTable所有的方法都是同步的,因此,它是线程安全的。HashTable是通过拉链法实现的哈希表,因此他使用数组+链表的方式来存储实际元素。
最顶部标数组的不封为一个Entry数组,而Entry又是一个链表,当项HashTable中插入数据的时候,首先通过键的hashcode和Enttry数组的长度来计算这个值应该存放在数组中的位置index,如果index对应的位置没有存放值,那么直接存放到数组的index位置即可,当index有冲突的时候,则采用“拉链法”来解决冲突。假如想往HashTable中插入的值的index相同,则以链表的形式存储。
HashTable继承自Dictionary,为了使HashTable拥有比较好的性能,数组的大小也需要根据实际插入的数据的多少来进行动态的调整,Hashtable类中定义了一个rehash方法,该方法可以用来动态地扩充HashTable的容量,该方法被调用的时机为:Hashtable中的键值对超过某一阈值。默认情况下,该阈值等于HashTable中Entry数组长度为*0.75.HashTable的默认大小为11,当达到阈值后每次按照下面的公式对容量进行扩容:newCapacity=oldCapacity*2 + 1;
HashTable通过使用synchronized修饰方法来实现多线程同步。因此,HashTable的同步会锁住整个数组,在高并发的情况下,性能会非常差,java5中引入java.util.concurrent.ConcurrentHashMap作为高吞吐量的线程安全HashMap实现,它采用锁分离的技术允许多个修改锁操作并发进行。
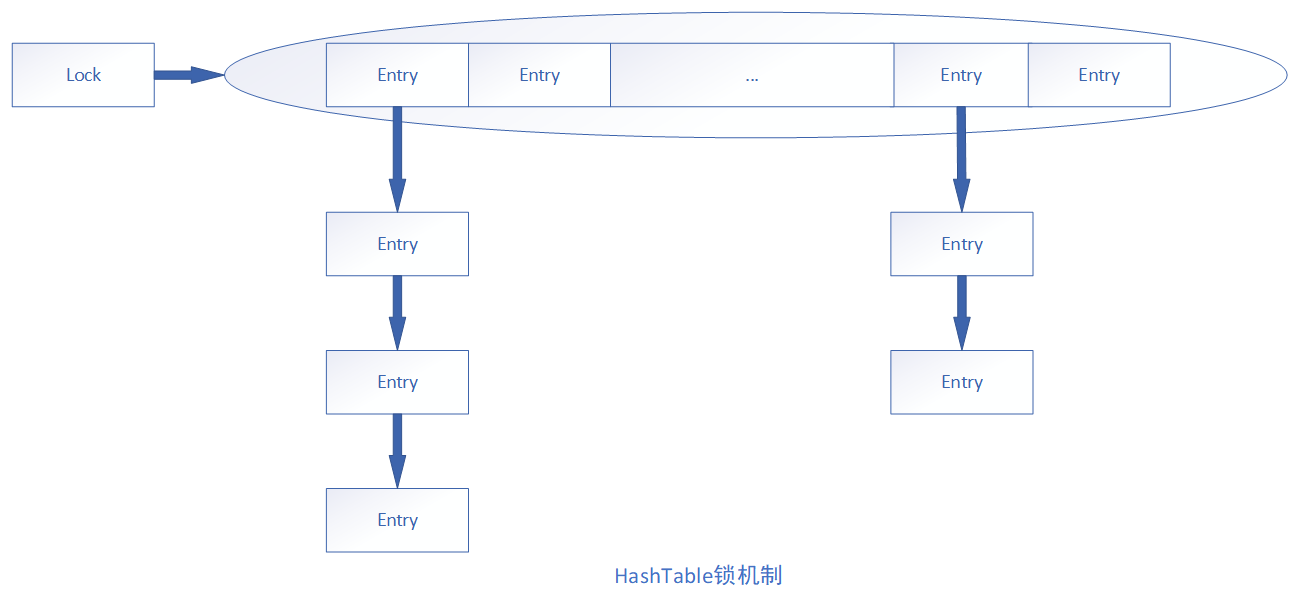
ConcurrentHashMap采用了更细粒度的锁来提高在高并发情况下的效率。ConcurrentHashMap将HashMap表默认分为16个桶(每一个桶可以被看作是一个HashMap),大部分操作都没有用到锁,而对应的put、remove等操作也只需要锁住当前线程需要用到的桶,而不需要锁整个数据。采用这种设计方式以后,在大并发的情况下,同时可以有16个线程来访问数据,显然大大提供了并发性。

只有个别方法,如size和contailsValue方法可能需要锁定整个表而不是仅仅某个桶,在实现的时候,需要按顺序锁定所有桶,操作完毕后,又按顺序释放所有桶,按顺序的好处是能防止死锁的发生。
假设一个线程在读取数据的时候,另外一个线程在Hash链的中间添加或删除元素或者修改某一个节点的值,此时必定会读取到不一致的数据。那么如何才能实现在读取时不加锁而又不会读取到不一致的数据呢?ConcurrentHashMap使用不变量的方式实现,它通过把Hash链中的节点HashEntry设计成几乎不可能的方式来实现。
在HashEntry的定义中,除了value以外,其他变量都被定义final类型,因此,增加节点的操作只能在Hash链的头部增加,对于删除操作,则无法直接从Hash链的中间删除节点,因为next也被定义为不可变量。因此,remove操作的实现方式如下所示:把需要删除的节点前面的所有节点都复制一遍,然后把复制后的Hash链的最后一个节点指向待删除节点的后继节点,由此可以看出,ConcurrentHashMap删除操作是比较耗时的,此外,使用volatile修改value的方式使这个值被修改了以后对所有线程都是可见的,采用这种方式的好处:一方面,避免了锁;另一方面,如果把value也设计成不能变量,那么每次修改value的操作都必须删除已有的节点,然后插入新的节点,显然,此时的效率会非常低下。
由于volatile只能保证变量所有的写操作都能立即反应到其他线程之中,也就是说volatile变量在各个线程中是一致的,但是由于volatile不能保证操作的原子性,因此它不是线程安全的。此处的线程安全指的是put(1,i++)这里i++操作,在进行这里操作时最好使用原子类的方法,保证多线程进行增值或减值时的线程安全。
3,ConcurrentHashMap在JDK1.7与1.8中的不同实现
对于JDK1.7
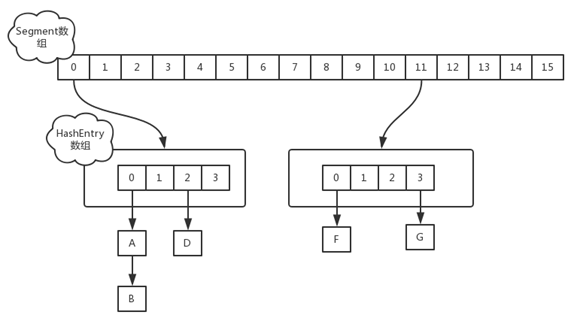
哈希桶的size:
因为size用位于运算来计算(ssize <<=1),所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为 DEFAULT_CONCURRENCY_LEVEL =16;
多个线程一起put时候,currentHashMap如何操作:
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
计算size方式:
1、使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
2、如果步骤一失败,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回(美团面试官的问题,多个线程下如何确定size)
JDK1.8的实现
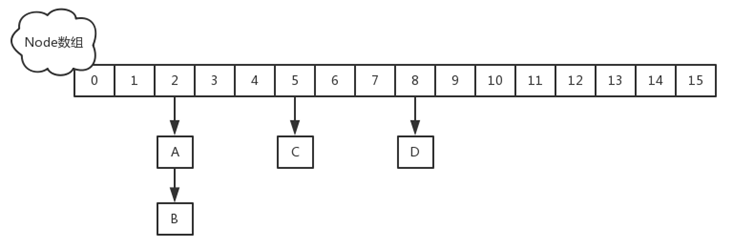
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本
JDK1.7与1.8中ConcurrentHashMap区别:
1.7的ReentrantLock+Segment+HashEntry,1.8中synchronized+CAS+HashEntry+红黑树,JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(链表首节点)。
1.7中put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表。1.8取消了segment,只需一次hash。
1.7中计算size 先不加锁计算3次,如果不对再给每个segment加锁计算一次,在JDK1.8版本中,对于size的计算,在put的扩容和addCount()方法就已经计算好了,直接给你。
HashEntry最小容量为2,1.7中segment初始容量为16,1.8中Node节点转TreeNode的阈值为8;