1, 二叉查找树
二叉查找树就是以二分法思想为指导,设计出来的一种快速查找树,二叉查找树保证以下特性:
- 每一个节点关键字只会在树中出现一次。
- 任何一个节点,如果它有子节点,那么左侧的关键字一定比较小,右侧的关键字一定比较大。
基于这种结构,搜索时每次从根节点开始查找,就算找到叶子结点,也只进行了log2n次比较,效率明显高于顺序/倒序遍历。
2, 平衡二叉树(AVL树)
极端情况下的二叉查找树可能只有左子树,进而退化为链表结构。为应对这种情况,引入了平衡二叉树:
- 它是一个空树或二叉查找树
- 左右两个子树的高度差的绝对值不超过1
- 左右两个子树都是一颗平衡二叉树
平衡二叉树的查找时间复杂度不会超过O(log2n),平衡二叉树在做插入或删除的时候,需要通过一系列的旋转(左旋、右旋)操作(自平衡),让其始终满足平衡二叉树的条件。
3, 红黑树
红黑树也是一种自平衡二叉树,但在统计上,它的性能要优于平衡二叉树。
1) 节点是红色或者黑色
2) 根节点是黑色
3) 每个叶子结点(NIL节点,虚拟的外部空节点,不真实存在)为黑色
4) 每个红色节点的两个子节点都是黑色
5) 从任一节点到其每个叶子结点的所有路径都包含相同数目的黑色节点。
根据这些性质,可以得出推论:从根到叶子的最长距离,不超过最短距离的两倍。 因为性质5约束了左支和右支黑色节点数目一定相等,性质4又约束了不会有两个相邻的红色节点,最长路径为红黑相间的节点序列,红色节点数最多为黑色节点数-1,因此红色+黑色<黑色*2。
对红黑树进行增删操作,会是树结构违背这些性质,因此像平衡二叉树一样需要在插入时进行自平衡操作。
红黑树的节点除了和其它二叉树一样的left/right/parent节点外,还有颜色red/black属性和是否为叶子节点标记isNil。
4, 红黑树的插入
由于性质5的约束,所有新插入的节点,都是红色节点,假设插入节点为N,父节点为P,祖父节点为G,叔节点为U,定义一个函数f(A,B),函数返回A节点相对B节点的位置(left/right)。
1) 如果该树为空树,那么N节点为根节点,根据性质2变色为黑。
2) 如果P为黑色,那么新增节点为红色,不会违背性质5,满足红黑树性质,不做任何操作。
3) 如果P为红色,那么分多种子情况:
- U为红色,把P、U改为黑色、G改为红色。G改为红色后,由于G的父节点也可能是红色,从而违背性质4,这时把G节点视为新插入的节点,递归进行插入操作。
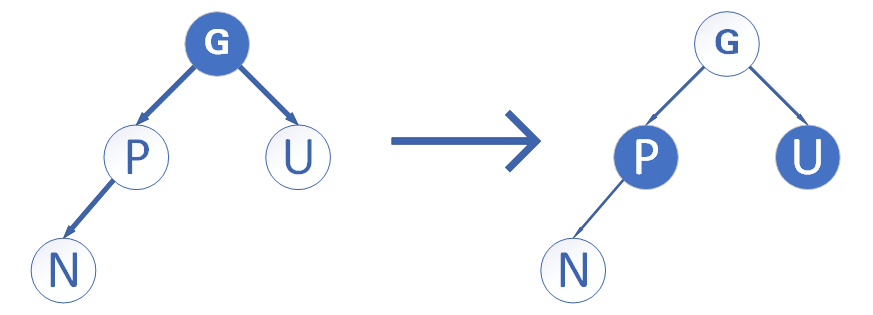
- U为黑色,且f(P,G)=f(N,P),则将P、G变色,对G为根节点的树做单向旋转(f(P,G)=L则LL右旋转,为R则RR左旋转),旋转是为了保证子树上黑色节点总数一致。

- U为黑色,且f(P,G)!=f(N,P),对P进行一次单向旋转,转化为f(P,G)=f(P,N)情况。

总结:红黑树的插入过程主要操作有两种。
变色,用于调整两个红色节点相邻的情况,以适应性质4
旋转,用于调整左右子树黑色节点数目不等的情况,以适应情况5
5, 红黑树在HashMap中的体现
1) treeifyBin方法
当table容量小于最小建树容量64时,调整table大小。最小建树容量的意义在于,重新规划table大小和树化某个哈希桶(哈希值对应下标的容器),都可以提高查询效率。这里取一个经验数字64作为衡量,当table容量超过64,调用TreeNode.treeify方法把链表转化为红黑树。
2) putTreeVal方法
执行二叉树查找,每一次都比较当前节点和待插入节点大小,如果带插入节点较小,那么从当前节点左子树查找,否则从右子树查找,这种查询效率等同于二分法,时间复杂度为O(log2n),待找到空位可以存放节点值之后,执行两个方法。
balanceInsertion(root,x),平衡插入,一方面把节点插入红黑树中,一方面对红黑树进行变换使之平衡。
moveRootToFront(table, root)由于红黑树重新平衡之后,root节点可能发生了变化,table里记录的节点不再是红黑树的root,需要重置。
3) balanceInsertion方法
此方法即上边插入分析的代码实现。
4) rotateLeft和rotateRight方法
左旋与右旋,改变节点左右子树引用即可实现。