一、定义
matplotlib:最流行的python的底层绘图库,主要做数据可视化,模仿MATLAB构建
二、为什么学习
1,能将数据进行可视化,更直观的呈现
2,使数据更加客观,更具说服力
三、基础绘图
案列1 :假设一天中每隔两小时(range(2,26,2))的气温分别是[15,13,14,5,17,20,25,26,26,24,22,18,15]
# 代码 import matplotlib.pyplot as plt # 规范,官方推荐 # 构建坐标 x = range(2,26,2) y = [15,13,14.5,17,20,25,26,26,24,22,18,15] # 画图 plt.plot(x, y) # 显示图标 plt.show()
1,1、保存图片
# 代码
fig = plt.figure(figsize=(20,8), dpi=100)
plt.plot(x,y)
fig.savefig('test.png')
1,2、X轴,Y轴的调整
# 代码 plt.plot(x, y) # x轴的刻度 plt.xticks(x) # y轴的刻度 plt.yticks(y) plt.show()
案列2 :列表a表示10点到12点每一分钟的气温,如何绘制折线图观察每分钟的气温?
a=[random.randint(20,35) for in range(120)]
# 代码
import random
# 随机气温值
# y = []
# 产生120个随机值
#for i in range(120):
# y.append(random.randint(20,35))
# 列表生成式
y = [random.randint(20,35) for i in range(120)]
x = list(range(120))
# 设置图片大小
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x,y)
# 调整刻度
xlables = ['10点{}分'.format(i) for i in range(60) ]
xlables += ['11点{}分'.format(i) for i in range(60) ]
plt.xticks(x[::3], xlables[::3])
plt.yticks(y)
plt.show()
2,1 显示中文
matplotlib默认不支持中文字符,需要修改默认字体来显示中文字符
# 代码
import random
import matplotlib as mpl
# 设置字符集
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
mpl.rcParams['font.size'] = 16 # 设置字体大小
# 随机气温值
# y = []
# 产生120个随机值
#for i in range(120):
# y.append(random.randint(20,35))
# 列表生成式
y = [random.randint(20,35) for i in range(120)]
x = list(range(120))
# 设置图片大小
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x,y)
# 调整刻度
xlables = ['10点{}分'.format(i) for i in range(60) ]
xlables += ['11点{}分'.format(i) for i in range(60) ]
plt.xticks(x[::3], xlables[::3], rotation=45)
plt.yticks(y)
plt.show()
2,2 添加描述信息
X,Y轴的描述
# 代码
y = [random.randint(20,35) for i in range(120)]
x = list(range(120))
# 设置图片大小
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x,y)
# 调整刻度
xlables = ['10点{}分'.format(i) for i in range(60) ]
xlables += ['11点{}分'.format(i) for i in range(60) ]
plt.xticks(x[::3], xlables[::3], rotation=45)
plt.yticks(y)
# 添加描述
plt.xlabel('时间', color='red', fontdict={'fontsize': 20})
plt.ylabel('温度')
plt.show()
2,3 图形标题
# 代码
y = [random.randint(20,35) for i in range(120)]
x = list(range(120))
# 设置图片大小
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x,y)
# 调整刻度
xlables = ['10点{}分'.format(i) for i in range(60) ]
xlables += ['11点{}分'.format(i) for i in range(60) ]
plt.xticks(x[::3], xlables[::3], rotation=45)
plt.yticks(y)
# 添加描述
plt.xlabel('时间', color='red', fontdict={'fontsize': 20})
plt.ylabel('温度')
# 设置标题
plt.title('某日10点到12点间的温度变化情况')
plt.show()
2,4 添加网格
# 代码
y = [random.randint(20,35) for i in range(120)]
x = list(range(120))
# 设置图片大小
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x,y)
# 调整刻度
xlables = ['10点{}分'.format(i) for i in range(60) ]
xlables += ['11点{}分'.format(i) for i in range(60) ]
plt.xticks(x[::3], xlables[::3], rotation=45)
plt.yticks(y)
# 添加描述
plt.xlabel('时间', color='red', fontdict={'fontsize': 20})
plt.ylabel('温度')
# 设置标题
plt.title('某日10点到12点间的温度变化情况')
# 添加网格
plt.grid(alpha=0.1)
plt.show()
案列3 :
问题:根据实际情况统计出来你和你的同桌各自从11岁到30岁每年交的男(女)朋友的数量如列表a和b,请在一个图中绘制出该数据的折线图,以便比较自己和同桌20年间的差异,同时分析每年交男(女)朋友的数量趋势
a=[1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
b=[1,0,3,1,2,2,3,3,2,1,2,1,1,1,1,1,1,1,1,1]
#代码
import matplotlib.pyplot as plt
import matplotlib as mpl
# 设置中文
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
mpl.rcParams['font.size'] = 16 # 设置字体大小
# 构建坐标
# x轴表示 年龄 ,y轴表示女朋友个数
x = range(11, 31)
y_self = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_d = [1,0,3,1,2,2,3,3,2,1,2,1,1,1,1,1,1,1,1,1]
# 创建容器
fig = plt.figure(figsize=(20,8))
# 画图
plt.plot(x, y_self, label='自己', color='black', linestyle='-.')
plt.plot(x, y_d, label='同桌')
# 设置刻度
x_lables = ['{}岁'.format(i) for i in x]
plt.xticks(x, x_lables)
plt.xlabel('年龄')
plt.ylabel('女朋友个数')
plt.title('我和同桌历年交女朋友个数对比')
# 设置了图例一定要加上这句话
plt.legend()
plt.grid(alpha=0.3)
# 标记点
plt.annotate('最高点',xy=(23,6), xytext=(24, 6),arrowprops={'arrowstyle': '<->'})
plt.show()
--一些自定义绘图风格
# 代码 plt.plot( x, y, color='r', # 线条颜色 linestyle='--', # 线条风格 linewidth=5, # 线条粗细 alpha=0.5 #透明度 )
--标记一个点
# 代码
plt.annotate(text='最高点', xytext=(24, 6.1), xy=(23, 6), arrowprops={'arrowstyle': '->'})
# text 想要标记的文本
# xytext 标记文本的坐标
# xy 被标记点的坐标
# arrowprops 箭头形式
四,简单图形总结
1,绘制了折线图
2,设置图片的大小和分辨率
3,实现了图片的保存
4,设置了XY轴上的刻度和字符串
5,解决了刻度稀疏和密集的问题
6,设置了标题,X,Y轴的lable
7,设置了字体
8,在一个图形上绘制多个图形
9,为不同图形添加图例
五、绘制散点图
假设通过爬虫你获取了北京2016年3月份,10月份每天白天的最高气温(分别位于列表a,b),要求找出气温随时间变化的规律
a = [10, 16, 17, 14, 12, 10, 12, 6, 6, 7, 8, 9, 12, 15, 15, 17, 18, 21, 16, 16, 20, 13, 15, 15, 15, 18, 20, 22, 22, 22, 24]
b = [26, 26, 28, 19, 21, 17, 16, 19, 18, 20, 20, 19, 22, 23, 17, 20, 21, 20, 22, 15, 11, 15, 5, 13, 17, 10, 11, 13, 12, 13, 6]import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['fangsong']#用来正常显示中文标签
mpl.rcParams['font.size'] = 16 #设置字体大小
y_3 = [10, 16, 17, 14, 12, 10, 12, 6, 6, 7, 8, 9, 12, 15, 15, 17, 18, 21, 16, 16, 20, 13, 15, 15, 15, 18, 20, 22, 22, 22, 24]
y_10 = [26, 26, 28, 19, 21, 17, 16, 19, 18, 20, 20, 19, 22, 23, 17, 20, 21, 20, 22, 15, 11, 15, 5, 13, 17, 10, 11, 13, 12, 13, 6]
x_3=list(range(1,32))
x_10=[i+50 for i in x_3]
#设置容器
fig=plt.figure(figsize=(15,8))
#绘图
plt.scatter(x_3,y_3,label='3月份')
plt.scatter(x_10,y_10,label='10月份')
#设置刻度
#集合
y=set(y_3+y_10)
min_y=min(y)
max_y=max(y)
plt.yticks(range(min_y,max_y))
#x轴
x=x_3+x_10
x_lables=['3月{}日'.format(i) for i in range(1,32)]+['10月{}日'.format(i) for i in range(1,32)]
plt.xticks(x[::2],x_lables[::2],rotation=45)
plt.xlabel('日期')
plt.ylabel('温度(C)')
plt.title('北京2016年3月份和10月份的气温变化趋势图')
plt.annotate('最高点',xy=(53,28),xytext=(56,28),arrowprops={'arrowstyle':'<->'})
plt.annotate('最低点',xy=(73,5),xytext=(76,5),arrowprops={'arrowstyle':'<->'})
plt.grid(alpha=0.3)
plt.legend()
plt.show()
散点图更多的应用场景:
--不同条件(维度)之间的内在关联联系
--观察数据的离散程度
六、绘制条形图
假设你获取了2019内地电影票房前20的电影(列表X)和电影票房数据(列表Y),那么如何更加直观的展示数据
x = ['哪吒之魔童降世', '流浪地球', '复仇者联盟4:终局之战', '疯狂的外星人', '飞驰人生', '烈火英雄', '速度与激情:特别行动', '蜘蛛侠:英雄远征', '扫毒2天地对决', '大黄蜂', '惊奇队长', '比悲伤更悲伤的故事', '哥斯拉2:怪兽之王', '阿丽塔:战斗天使', '银河补习班', '狮子王', '反贪风暴4 ', '熊出没·原始时代', '使徒行者2:谍影行动', '大侦探皮卡丘']
y = [49.04, 46.18, 42.05, 21.83, 17.03, 16.74, 14.16, 14.01, 12.85, 11.38, 10.25, 9.46, 9.27, 8.88, 8.64, 8.23, 7.88, 7.09, 6.92, 6.34]
# 代码
import matplotlib as mpl
import matplotlib.pyplot as plt
# 设置中文
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
mpl.rcParams['font.size'] = 16 # 设置字体大小
# 构建坐标
movies = ['哪吒之魔童降世', '流浪地球', '复仇者联盟4:终局之战', '疯狂的外星人', '飞驰人生', '烈火英雄', '速度与激情:特别行动', '蜘蛛侠:英雄远征', '扫毒2天地对决', '大黄蜂', '惊奇队长', '比悲伤更悲伤的故事', '哥斯拉2:怪兽之王', '阿丽塔:战斗天使', '银河补习班', '狮子王', '反贪风暴4 ', '熊出没·原始时代', '使徒行者2:谍影行动', '大侦探皮卡丘']
y = [49.04, 46.18, 42.05, 21.83, 17.03, 16.74, 14.16, 14.01, 12.85, 11.38, 10.25, 9.46, 9.27, 8.88, 8.64, 8.23, 7.88, 7.09, 6.92, 6.34]
x = range(len(movies))
# 画图
fig = plt.figure(figsize=(20,8), dpi=100)
plt.bar(x, y, width=0.5, color='orange')
# 刻度
plt.xticks(x, movies, rotation=-90)
plt.xlabel('电影')
plt.ylabel('票房(亿元)')
plt.title('2019年内地前20名电影票房榜')
# 网格
# plt.grid()
plt.show()
--横向条形图
# 代码
import matplotlib as mpl
import matplotlib.pyplot as plt
# 设置中文
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
mpl.rcParams['font.size'] = 16 # 设置字体大小
# 构建坐标
movies = ['哪吒之魔童降世', '流浪地球', '复仇者联盟4:终局之战', '疯狂的外星人', '飞驰人生', '烈火英雄', '速度与激情:特别行动', '蜘蛛侠:英雄远征', '扫毒2天地对决', '大黄蜂', '惊奇队长', '比悲伤更悲伤的故事', '哥斯拉2:怪兽之王', '阿丽塔:战斗天使', '银河补习班', '狮子王', '反贪风暴4 ', '熊出没·原始时代', '使徒行者2:谍影行动', '大侦探皮卡丘']
y = [49.04, 46.18, 42.05, 21.83, 17.03, 16.74, 14.16, 14.01, 12.85, 11.38, 10.25, 9.46, 9.27, 8.88, 8.64, 8.23, 7.88, 7.09, 6.92, 6.34]
x = range(len(movies))
# 画图
fig = plt.figure(figsize=(20,8), dpi=100)
plt.barh(x, y, color='orange')
# 刻度
plt.yticks(x, movies)
plt.ylabel('电影')
plt.xlabel('票房(亿元)')
plt.title('2019年内地前20名电影票房榜')
# 网格
# plt.grid()
plt.show()
列表a中的电影最近5天的电影分别在列表,b_25,b_26,b_27,b_28,b_29中,为了展示电影本身票房,及同其他电影数据的对比,应该如何更直观的呈现数据
a = ['决胜时刻', '诛仙Ⅰ', '小小的愿望']
b_25 = [891.4, 246.71, 550.45]
b_26 = [81]9.27, 397.18, 513.67]
b_27 = [867.78, 480.43, 752.36]
b_28 = [533.09, 500.42, 780.69]
b_29 = [679.87, 462.28, 374.11]
# 代码
# 导库
import matplotlib as mpl
import matplotlib.pyplot as plt
# 设置中文
mpl.rcParams['font.sans-serif'] = ['Fangsong']
mpl.rcParams['font.size'] = 16
# 准备数据
a = ['决胜时刻', '诛仙Ⅰ', '小小的愿望']
b_25 = [891.4, 246.71, 550.45]
b_26 = [819.27, 397.18, 513.67]
b_27 = [867.78, 480.43, 752.36]
b_28 = [533.09, 500.42, 780.69]
b_29 = [679.87, 462.28, 374.11]
#
fig = plt.figure(figsize=(20,8))
width = 0.1
plt.bar(range(3), b_25, width=width)
plt.bar([i+width for i in range(3)], b_26, width=width, label='9月26日')
plt.bar([i+width*2 for i in range(3)], b_27, width=width, label='9月27日')
plt.bar([i+width*3 for i in range(3)], b_28, width=width, label='9月28日')
plt.bar([i+width*4 for i in range(3)], b_29, width=width, label='9月29日')
# 刻度
plt.xticks([0.2, 1.2, 2.2], a)
# 描述信息
plt.xlabel('电影')
plt.ylabel('票房(万)')
plt.title('某些电影的票房')
plt.legend()
plt.show()
--条形图应用更多的场景
-数量的统计
-频率的统计
七、绘制直方图
我们获取了347部电影的时长(列表data中),希望统计出这些电影的时长分布状态(比如时长100到120分钟的数量,出现频次等)等信息,你该如何呈现这些数据
data = [110, 201, 160, 152, 139, 178, 179, 83, 67, 132, 136, 177, 162, 110, 132, 115, 108, 102, 76, 105, 108, 24, 140, 162, 143, 165, 163, 95, 129, 137, 84, 93, 115, 96, 145, 173, 102, 116, 100, 120, 119, 88, 108, 136, 144, 111, 212, 87, 120, 91, 126, 55, 134, 181, 159, 138, 119, 138, 93, 155, 119, 88, 108, 136, 144, 111, 212, 87, 120, 91, 126, 55, 134, 181, 159, 138, 119, 138, 93, 155, 89, 140, 139, 75, 230, 179, 126, 178, 102, 91, 150, 96, 118, 100, 125, 130, 144, 140, 124, 157, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 89, 140, 139, 75, 230, 179, 126, 178, 102, 91, 150, 96, 118, 100, 125, 130, 144, 140, 124, 157, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 101, 141, 99, 139, 132, 93, 136, 127, 87, 96, 108, 120, 111, 130, 91, 237, 151, 76, 102, 64, 118, 84, 84, 105, 140, 144, 133, 93, 123, 147, 130, 149, 147, 121, 114, 105, 104, 98, 115, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 101, 141, 99, 139, 132, 93, 136, 127]
# 代码 import matplotlib as mpl import matplotlib.pyplot as plt # 设置中文 mpl.rcParams['font.sans-serif'] = ['Fangsong'] mpl.rcParams['font.size'] = 16 # 准备数据 data = [110, 201, 160, 152, 139, 178, 179, 83, 67, 132, 136, 177, 162, 110, 132, 115, 108, 102, 76, 105, 108, 24, 140, 162, 143, 165, 163, 95, 129, 137, 84, 93, 115, 96, 145, 173, 102, 116, 100, 120, 119, 88, 108, 136, 144, 111, 212, 87, 120, 91, 126, 55, 134, 181, 159, 138, 119, 138, 93, 155, 119, 88, 108, 136, 144, 111, 212, 87, 120, 91, 126, 55, 134, 181, 159, 138, 119, 138, 93, 155, 89, 140, 139, 75, 230, 179, 126, 178, 102, 91, 150, 96, 118, 100, 125, 130, 144, 140, 124, 157, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 89, 140, 139, 75, 230, 179, 126, 178, 102, 91, 150, 96, 118, 100, 125, 130, 144, 140, 124, 157, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 162, 121, 170, 111, 124, 99, 102, 75, 120, 139, 110, 138, 40, 70, 138, 137, 123, 133, 161, 83, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 101, 141, 99, 139, 132, 93, 136, 127, 87, 96, 108, 120, 111, 130, 91, 237, 151, 76, 102, 64, 118, 84, 84, 105, 140, 144, 133, 93, 123, 147, 130, 149, 147, 121, 114, 105, 104, 98, 115, 93, 121, 105, 106, 140, 101, 124, 148, 131, 101, 90, 90, 100, 129, 100, 94, 96, 89, 144, 100, 107, 90, 137, 133, 97, 84, 99, 142, 126, 132, 144, 124, 112, 111, 169, 151, 132, 169, 127, 120, 101, 141, 99, 139, 132, 93, 136, 127] # 组距 bin_width = 8 max_value = max(data) min_value = min(data) bins = (max_value - min_value)//bin_width # 实际组距 real_width = (max_value - min_value)/bins # 设置大小 fig = plt.figure(figsize=(20,8)) plt.hist(data, bins) print([min_value + i*bin_width for i in range(bins)]) # x轴刻度 plt.xticks([min_value + i*real_width for i in range(bins)], rotation=45) plt.grid() plt.show()
需要注意的点:
1,组数的选择
组数要适当,较少会有太大的统计误差,太多规律不明显
当数据在100以内时,按数据多少一般分5-12组
当数据较多时可以按照组距进行分组
组距:是指每组两个端点的距离
组数:=极差/组距=(最大数据-最小数据)/组距
2,X轴的刻度
正常情况下实际组距会是小数,所以刻度需要按照实际组距来,否则或出现图形偏移的情况
实际组距=极差/组数
刻度列表=[最小数据+实际组距 * i for in range(组数 +1)]
3、频率直方图与频数直方图
频率分布直方图纵轴表示频率/组距,横轴表示各组组距,若求某一组的频率,就用纵轴的频率/组距*横轴的组距,即得到该组频数
频率=频数/数据总数
美国人口普查发现有1.24亿人在外工作。根据他们从家到上班地点所需要的时间,通过抽样统计出了下表的数据,这些数据能绘制成直方图吗
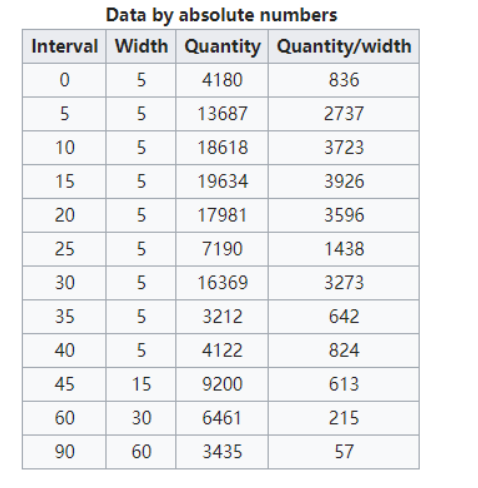
思考这个数据能绘制直方图吗?
给出的数据是统计之后的数据,所以为了达到直方图的效果,需要绘制条形图。
结论:一般来说能够使用plt.hist方法绘制直方图的是那些没有统计过的原始数据。
# 代码
import matplotlib as mpl
import matplotlib.pyplot as plt
# 设置中文
mpl.rcParams['font.sans-serif'] = ['Fangsong']
mpl.rcParams['font.size'] = 16
# 用条形图模拟直方图
# 数据
interval = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 60, 90, 150]
width = [5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 30, 60]
quantity = [4180, 13687, 18618, 19634, 17981, 7190, 16369, 3212, 4122, 9200, 6461, 3435]
# 画图
plt.figure(figsize=(20,8))
for i in range(len(width)):
plt.bar([interval[i]+width[i]/2], [quantity[i]], width=width[i], color='orange')
# plt.bar(interval[1:], quantity, width=5)
# 刻度
plt.xticks(interval)
# x轴 ,y周的信息
plt.show()