这篇文章讲的很详细 https://www.jianshu.com/p/528ce5cd7e8f
背景:
首先,本质上来说,一致性Hash仍然是一种Hash算法,用来解决Hash更均匀分布的问题。
传统的Hash算法是通过对一个数据长度取模来得到Hash值,这有一个缺点就是,如果我的数据长度变化,那就需要更改长度,不够灵活。
如 hash(product.png) % 6 = 5 。其中6代表一些服务的集群节点数量(如Redis集群)。当我的集群数量变化时候,我需要重新修改为其它的值,很不方便
所以就有了一致性Hash的算法用来改进。
一致性Hash的定义:
一致性Hash算法也是使用取模的方法,不过,上述的取模方法是对服务器的数量进行取模,而一致性的Hash算法是对
2的32方 取模。即,一致性Hash算法将整个Hash空间组织成一个虚拟的圆环,Hash函数的值空间为0 ~ 2^32 - 1(一个32位无符号整型),整个哈希环如下: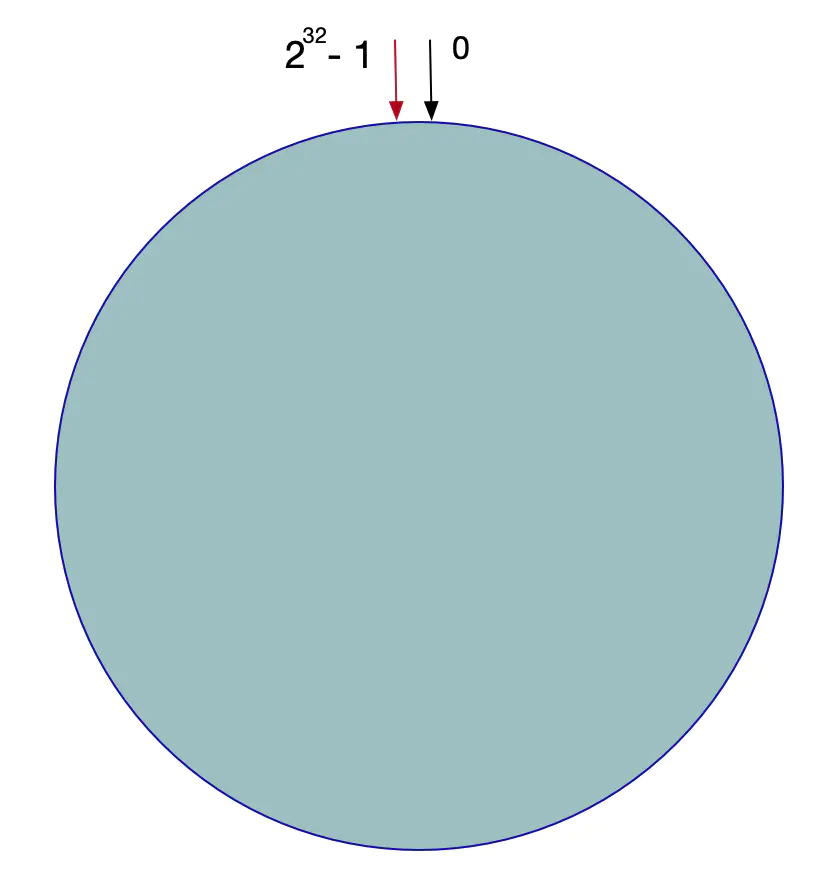
整个圆环以顺时针方向组织,圆环正上方的点代表0,0点右侧的第一个点代表1,以此类推。
链接:https://www.jianshu.com/p/528ce5cd7e8f
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。