严格意义上来说,操作系统可以被定义一种软件,它控制计算机硬件资源,提供程序运行环境。
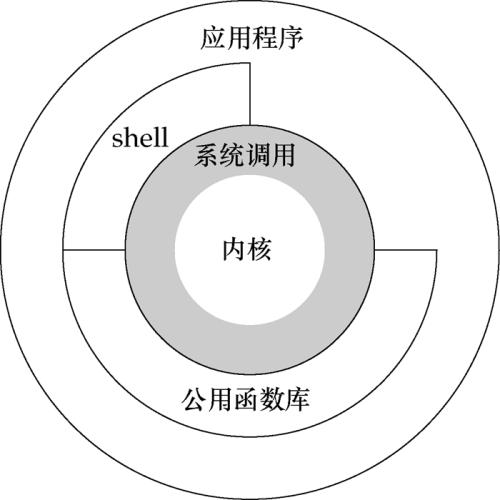
我们通常将这种软件称为内核(kernel)。因为它相对较小。
内核的接口被称为系统调用(system call)。公共函数库建立在系统调用之上。
应用程序既可以使用公共函数库,也可以使用系统调用。
shell是一款特殊的应用程序,为运行其他应用程序提供了一个接口。
登录:
/etc/password文件中:有7个由冒号分隔的字段组成。
依次是:登录名,加密口令,数字用户ID,数字组ID,注释字段,起始目录,shell程序。
文件和目录:
文件系统:是目录和文件的一种层次结构,所有东西的起点是根(root)的目录。这个目录的名字就叫做“/”。
目录:是包含目录项的文件,每个目录项都包含一个文件名,同时还包含说明该文件属性的信息。
文件属性:文件类型,大小,所有者,权限,最后的修改时间等。
文件名:斜线/和空字符不能出现在文件名中。斜线是用来分隔构成路径名的各文件名,空字符用来终止一个文件名;
新建一个目录的时候,会自动创建两个文件名 . 和.. 。点指向当前目录,点点指向父目录。最高层次的根目录中,点和点点相同。
路径名:由斜线分隔的一个或多个文件名组成的序列构成了路径名。以斜线开头的路径名称为绝对路径。否则就是相对路径。
相对路径指向相对于当前目录的文件。文件系统中根目录的名字是一个特殊的绝对路径名,它不包含文件名。
工作目录:每个进程都有一个工作目录,有时称其为当前工作目录。所有相对路径名都从工作目录开始解释。
输入和输出
文件描述符:通常是一个非负整数。内核用以标识一个特定进程正在访问的文件。当内核打开或创建一个新文件时,它都返回一个文件描述符。
在读写文件时,都可以使用这个文件描述符。
标准输入,标准输出和标准错误:每当运行一个程序时,shell都为其打开三个文件描述符。即标准输入,标准输出,标准错误。
如果不做特殊的处理,这三个描述符都链接向终端。大多数shell能够提供方式,使得三个描述符重定向到指定得文件中。
不带缓冲的I/O:函数open,read,write,lseek,close提供了不带缓冲的I/O;<unistd.h>头文件包含了很多UNIX系统服务的函数原型。
STDIN_FILENO和STDOUT_FILENO是POSIX标准的一部分。它们指定了标准输入和标准输出的文件描述符。
标准I/O:标准I/O函数为那些不带缓冲的I/O函数提供了一个带缓冲的接口。使用标准I/O函数无需担心如何选取最佳的缓冲区大小。还简化了堆输入行的处理。
程序和进程
程序:是一个存储在磁盘上某个目录中的可执行文件。内核使用exec函数将程序读入内存,并执行程序。
进程和进程ID:程序执行的实例被称为进程。UNIX系统确保每个进程都有一个唯一的数字标识符。被称为进程ID。进程ID是一个非负整数。
进程控制:fork,exec,waitpid。exec函数有7类但是被统称为exec函数。
线程和线程ID:通常情况下一个进程只有一个控制线程。对于某些问题,如果有多个控制线程分别作用于它的不同部分,那么解决问题就容易得多。
多个控制线程也可以充分利用多处理器系统得并行能力。一个进程的所有线程共享同一地址空间,文件描述符,栈以及进程相关的属性。因为它们能够访问同一存储区。
所以各线程在访问共享数据时需要采取同步措施以避免不一致性。与进程ID相同,线程也有ID标识。线程ID只在它所属的进程内起作用。
出错处理
当UNIX系统函数出错时,通常会返回一个负值。
而整型变量errno通常会被设置为具有特定信息的值。
文件<errno.h>中定义了errno以及可以赋与它的各种常量。这些常量都以字符E开头。
用户标识
用户ID:是一个数值,它向系统标识各个不同的用户。
用户ID为0的用户为根用户或超级用户。系统管理员在确定一个用户的登录名的同时,确定其用户ID。
用户不能更改其用户ID。通常每个用户有一个唯一的用户ID。
如果一个进程具有超级用户特权,则大多数文件权限检查都不再进行。
某些操作系统的功能只向超级用户提供,超级用户堆系统有自由的自配权。
组ID:口令文件登录项也包括用户的组ID。它是一个数值。组ID也是有系统管理员在指定用户登录名时分配的。
组被用于将若干用户集合到项目或部门中去。这种机制允许同组的各个成员之间共享资源。
组文件将组名映射为数值得组ID。组文件通常时/etc/group。
使用数值得用户ID和数值得组ID设置权限时历史上形成的。
对于磁盘上的每个文件,文件系统都存储该文件所有者的用户ID和组ID。
存储这两个值只需要4个字节。校验权限期间,比较字符串较之比较整数型更消耗时间。
对于用户而言,使用名字比使用数值更加方便,所以口令文件包含了登录名和用户ID之间的映射关系。
组文件则包含了组名和组ID之间的映射关系。
附属组ID:除了在口令文件中对一个登录名指定一个组ID外,大多数UNIX系统版本还允许一个用户属于另外一些组。
这一功能时从4.2BSD开始的,它允许一个用户属于多至16个其他的组。
登录时,读文件/etc/group,寻找列有该用户作为其成员的其成员的前16个记录项就可以得到该用户的附属组ID。
信号
信号用于通知进程发生了某种情况。
进程有三种处理信号的方式:
1)忽略信号;
2)按系统默认方式处理:对于除数为0,系统默认方式是终止该进程;
3)提供一个函数,信号发生时调用该函数,这被称为捕捉该信号。通过提供自编的函数,我们就能知道什么时候产生了信号,并按期望的方式处理它。
很多情况都会产生信号,终端键盘上有两种产生信号的方式。分别为中断键(通常是Ctrl+C和Delete键),退出键(Ctrl+)。它们被用于中断当前运行的进程。
另一种产生信号的方法是调用kill函数。在一个进程中调用此函数就可以向另一个进程发送一个信号。当向一个进程发送信号时,我们必须是那个进程的所有者或者是超级用户。
时间值
历史上,UNIX系统使用过两种不同的时间值。
1)日历时间
该值是自协调世界时(UTC)这个特定时间以来所经历过的秒数累计值。这些时间值可用于记录文件最近一次的修改时间等。
系统基础数据类型time_t用于保存这种时间值。
2)进程时间
也被称为CPU时间,用以度量进程使用的中央处理器资源。进程时间以始终滴答计算。每秒钟曾取为50,60或100个时间滴答。
系统基本数据类型clock_t保存这种时间值。
当度量一个进程的执行时间时,UNIX系统为一个进程维护了3个进程时间值。
时钟时间;
用户CPU时间;
系统CPU时间;
时钟时间又称为墙上时钟时间(wall clock time)。它是进程运行的时间总量。其值与系统中同时运行的进程数有关。
用户CPU时间是执行用户指令所用的时间量。
系统CPU时间是为该进程执行内核程序所经历的时间。
每当一个进程执行一个系统服务时,如read或write,在内核内执行该服务所花费的时间就计入该进程的系统CPU时间。
用户CPU时间和系统CPU时间之和常被称为CPU时间。
系统调用和库函数
所有的操作系统都提供多种服务的入口点,由此程序向内核请求服务。
各种版本的UNIX实现都提供良好定义、数量有限、直接进入内核的入口点。这些入口点被称为系统调用(system call)。
UNIX所使用的技术是为每个系统调用在标准C库中设置一个具有同样名字的函数。
用户进程用标准C调用序列来调用这些函数,然后,函数又用系统所要求的技术调用相应的内核服务。
从应用角度考虑,可将系统调用视为C函数。系统调用和库函数都使用函数这一属于来表示。
从实现者的角度来看,系统调用和库函数之间有根本的区别。从用户角度来说,其区别不重要。
系统调用和库函数都以C函数的形式出现,两者都为应用程序提供服务。
但是我们应当理解,如果希望的话,我们可以替换库函数,但是系统调用通常是不能被替换的。
应用程序既可以调用系统调用也可以调用库函数。很多库函数则会调用系统调用。
系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能。